IBM BigSQL—真正的大数据 SQL
对于 Hadoop 之上的大数据应用,SQL-on-Hadoop 的需求一直备受关注,市场上也出现了很多 SQL-on-Hadoop 产品,例如最早的开源产品 Hive,Cloudera 的 Impala 等。IBM 依托其在 RDBMS 领域多年来积累的丰富经验,结合在 RDBMS 中的先进技术推出了其 SQL-on-Hadoop 的重要产品 - BigSQL。衡量一个优秀的 SQL-on-Hadoop 产品的标准有很多,包括对 SQL 语法的支持程度、性能、扩展性、是否易于集成等等,而 BigSQL 在这些方面都有不俗的表现。而且,BigSQL 不仅支持 Hadoop 之上的 SQL 查询,同时能够操纵 RDBMS。因此可以说,BigSQL 是一个真正的大数据之上的 SQL 应用。本文从 SQL-on-Hadoop 的需求背景入手,逐步介绍 IBM BigSQL 在 SQL 语法、内存优化、负载管理、安全与监控、企业级集成等各方面的功能,最后结合实际的实际案例来直观展现 BigSQL 如何满足大数据之上的 SQL 需求。
背景
提起“大数据”这个名词,相信大家都已经不再陌生。大数据可以说无所不在,社交媒体、传感设备、机器生成的信息、手持终端设备产生的信息等等,这些“新数据”有相当一大部分都是非结构化的,而且产生速度非常快,是大数据的一个重要部分。通过这些数据的分析,可以帮助我们可以更加全面的了解用户的心理、习惯、喜好等等,从而为他们提供更好的产品和服务。但是我们也不要忽略了,其实对于很多企业来说,有一些传统的关系型数据可能会是他们更加关心的。比如曾经存储在企业数据库、商业智能应用等中的历史数据,企业为了保证在线平台的实时查询,不得不将这些数据导出来。但这些庞大的历史数据中潜藏着巨大的价值,例如银行可以通过对用户几年、几十年的数据分析,从而分析出客户的理财习惯、对哪些理财产品可能感兴趣等等。这些数据虽然数据量庞大但是是关系型的,那么对于这类数据,自然的就会产生这样一种需求:能不能利用我们已经非常熟悉的 SQL 来对这种类型的大数据进行分析?
或许有人会问,MapReduce 不能够做这样的分析吗?为什么需要再开发一种新的技术呢?原因有很多方面,但是最重要的原因有以下几个方面:
1)与关系型数据库技术相比,Hadoop 还比较年轻,那么对于 Hadoop 中的 MapReduce 技术掌握的开发人员相对来说还是少数的。我们的开发人员需要额外的花费很多时间去学习这一新的技术框架,这不是很多人所愿意的;
2)如果去直接开发 MapReduce 程序去做数据仓库里面操作,比如最常见的连接查询,代码量、性能调优需要的精力等,都还是蛮大的;
3)提供大数据之上的 SQL 技术会吸引更多的人加入到大数据分析这场战役里面来。因为 SQL 的语法大家已经非常熟悉,这之上产品、工具、应用也已经有非常多,所以这是很吸引人的一件事。
正是在这种需求下,现在市场上出现了大量的 Hadoop 之上的 SQL 产品,比如最早的开源产品 Hive、Cloudera 的 Impala、Apache Drill 等等。
所有的这些产品基本都会去考虑以下几个方面,这些也是衡量一个产品是否足够强大的标准:
(1)性能,查询速度是否足够快。
(2)对 SQL 语法的支持程度。
因为传统的 SQL 是运行在关系型数据库中的表上的,表中是一条条的记录。但是 Hadoop 之上的文件全部存储在 HDFS 上,没有真正的“表”的概念。那么 SQL 去运行在这些 HDFS 文件上,并不是那么容易的事情,它需要我们在底层做很多工作,来完善对 SQL 语法的支持。不光要简单的能够运行,还要对它进行优化,尽量让我们的查询速度比较快;
(3)企业级的特性。
比如安全性,是不是支持类似数据库里面的行安全性、列安全性?比如跟企业其他信息系统的集成,是否支持标准的 JDBC/ODBC 接口?
(4)与 Hadoop 生态系统里面的其他组件的集成。
比如能不能直接访问 Hbase 里面的数据?数据能不能被类似于 Pig 这样的高级 MapReduce 语言进行查询?等等。
那么 IBM 是否有某个产品能够对上面所说的四个方面都提供很好的支持呢?答案是肯定的,IBM InfoSphere BigInsights 里面的 BigSQL 就是这么一款优秀的产品。
回页首
最早的开源 SQL-on-Hadoop 产品 Hive 简介
前面我们讲了 SQL-on-Hadoop 的一些背景,这里我们来简单介绍一下最早的开源的产品 Hive,通过跟 Hive 的对比我们可以更好的了解 BigSQL 有哪些优势。
因为 Hive 是开源的产品,目前基本所有的 Hadoop 分发版本都包含它,BigInsights 也包括 Hive。我们这里所讲的 Hive 的特性是基于 0.12 版本之前的,目前 Hive 的 0.13 版本也在做一些新的改动,大家可以访问 Hive 的官网 来了解详细信息。
Hive 最早是由 Facebook 公司开发的,后来将它开源了出来。我们应该感谢 Hive,因为 Hive 提供了很多非常有价值的组件,这些组件目前也被很多 SQL-on-Hadoop 的其他产品所重用,比如它的 Metastore (BigSQL 同样也重用了 Hive 的 Metastore)。
图 1 是 Hive 的一个大概架构。可以看到最下面是 Hadoop,表明 Hive 架构在 Hadoop 上面,上面一层分为三个部分,三个部分之间有交互。最左侧是 Hive 的 Metastore,中间是 Client 端访问 Hive 的几种方式,比如 JDBC/ODBC、命令行,或者是 Web;最右侧的部分表示 Hive 中对 HQL 进行解析、优化、产生运行计划的引擎。Client 端通过提交查询语句到 Hive 之后,会被引擎生成 MapReduce 去运行;在定义一个表的时候,会将元数据信息写入 Metastore。
图 1. Hive 架构
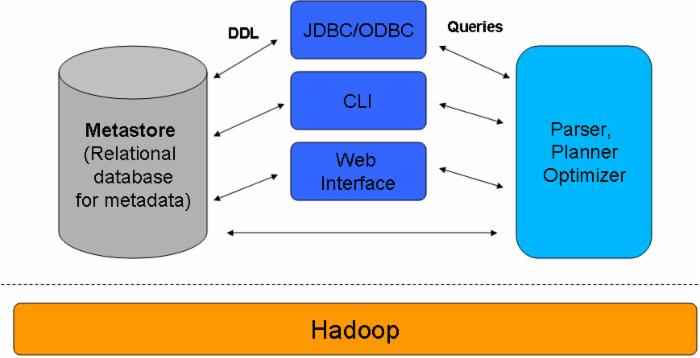
Hive 的 SQL 语句叫做 HQL,这些 HQL 语句大部分在运行的时候,底层被自动翻译成 MapReduce 在 Hadoop 集群上运行(图 2)。
图 2. SQL 查询与 MapReduce
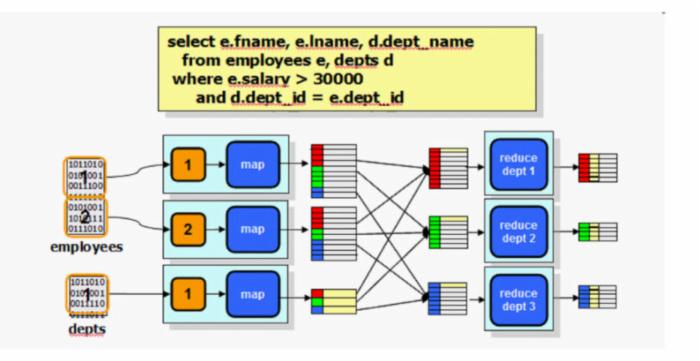
这幅图向大家简单展示了当一个 select 查询在执行时是怎么转化成 MapReduce 的。我们有两个表,现在要做一个简单的 join 查询,查询中还有另外一个条件是 salary>30000, 那么这个查询就会转化成一个 MapReduce 程序,map 阶段读取每个表的一个个 block,我们知道 MapReduce 程序中,Map 和 Reduce 的输入、输出都是 key-value 的形式。那么 Map 阶段输入的 key 是这个查询中做 join 的 key 值,这里是 dept_id;value 是对应的 record 记录。然后 map 将处理完的结果发送到 reduce,reduce 部分处理 e.salary>30000,最终得到我们要的结果。
如果这个查询稍微复杂一点,涉及到的表有三个,那么底层就需要做两次的 MapReduce,如果更复杂的查询,就会产生更多次的 MapReduce。大家都知道,MapReduce 是不能支持实时查询的,因为每一个 MapReduce 作业在启动和 cleanup 阶段都会耗费一定量的时间(秒级别),而且多次 MapReduce 会产生很多的中间结果,因此这些都限制了 Hive 的性能。当然 Hive 在做执行计划的时候会做一些优化,去提高执行的速度,但是这些还不足够。
Hive 是一种 schema-on-read 的方式,所谓 schema-on-read 是说,在插入数据到表的时候它实际上不进行语法校验,而是在查询的时候才会进行语法校验。这种方式好处是可以非常快速的加载完数据,同时也为以多种 schema 去分析数据提供了灵活性;一个弊端就是因为在查询时作语法校验,会对查询速度有一定的影响。
Hive 中的表
Hive 里面也有所谓的“表”的概念,但这些表跟数据库里面的表不同,它其实就是存储在 HDFS 上的一个个的文件,Hive 并不会对文件进行二次的拆分,它的目的是直接工作于现有的数据之上。所以从某种意义上说,Hive 中其实是不存在 Hive table 的。
Hive 的表又分为两种,一种是 Hive 自己管理的表,所有使用 Create Table 语法定义的表都属于这一类。那么对于这类表,当我们运行 LOAD 语句的时候,原始 HDFS 文件系统上的数据会被直接移动到 Hive 的 data warehouse 文件夹下;在运行 Drop 命令的时候,表的元数据信息和数据文件将全部被删除;
另外一种表叫做外部表,使用 Create External Table 语法定义,对于这类表,当使用 LOAD 语句的时候,事实上只是会在 Hive 里面生成关于表结构的元数据信息,原始的数据不会被移动或者 copy。当我们运行 Drop 命令的时候,只有元数据信息会被从 Hive 里面删除,原始数据不会受到影响。
什么时候会用到外部表呢?一种情况是需要在 Hive 和 Hadoop 的其他应用之间共享数据,比如我们可以在 Hive 里面去访问 HBase 的数据,这是一种情况;第二种常见的情况是,对于同样的一份数据,我们想要用不同的 schema 去分析,那么也可以使用外部表的功能。
Hive Metastore
Hive 的 Metastore 是 Hive 中一个非常重要的概念,它是一个存储元数据信息的地方,这些元数据包括表定义相关的数据,比如位置、列名和类型、分区信息、读写 table 涉及的类名等等;另外还包括安全性相关的一些信息,比如组、角色、权限管理等信息。Hive 提供了多种访问 Metastore 的方式,比如 Thrift 方式、通过 JDBC 访问,还有一种快速的方式是通过 Hive 提供的 API 来访问。
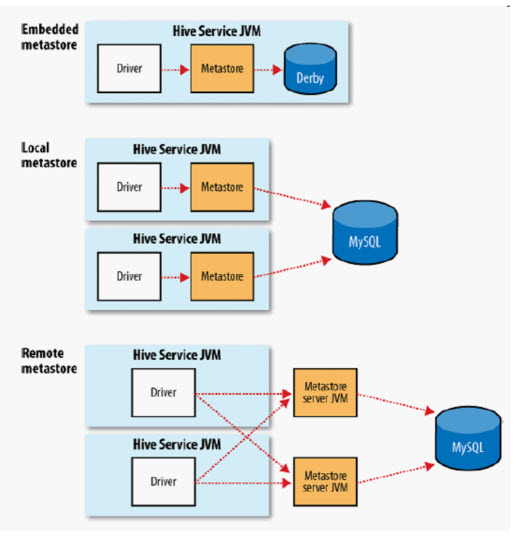
Hive 的 Metastore 更细一步的说,其实包含了两个概念:
一个是底层存储元数据的一个数据库,可以是 Derby 或者 MySQL 或者其他数据库;
另外一个是 Metastore service。用户通过 Metastore service 去访问数据库。
那么这样一来,Hive 的 Metastore 就可以配置为三种的方式(图 3),关于这三种方式的意义网上有很多相关资料,这里不再详细解释。
图 3. Hive Metastore 三种配置方式
Hive Query Language (HQL)
Hive 的语言称为 Hive Query Language,简称 HQL,是 SQL 语法格式的,这里不做细节性的介绍。需要指出的一点是,Hive 对 SQL 的语法支持并不是很完整,大概有这些方面:
它不支持对任意记录的更新或者删除,它只能对全表数据进行追加或者直接覆盖;
- 不支持事务和索引;
- 不支持 Select 语句中使用 Having 子句;
- 不支持相关子查询或者 FROM 子句之外的子查询;
- 不支持物化视图和存储过程。
Hive 的优势与劣势
Hive 的优势个人认为主要有三点:
- 它是最早的一个 SQL-on-Hadoop 产品,所以有很多企业已经使用它有一段时间了,虽然它不支持实时查询,但对于历史数据查询不那么在意速度的话,是可以接受的;
- 它是开源的产品,了解和使用它的人相对最多,当然更新也会比较快;
- 相对来讲,因为发展时间比较长,尽管它也有一些缺陷,但是稳定性方面还是比较令人满意的。
它的不足之处主要有以下两个方面:
- 对 SQL 语法的支持不完整。这对于某些情况下可能会带来额外的工作,比如企业之前在数据仓库中处理这些数据的时候,是有很多成形的 SQL 的,有些 SQL 可能是不能直接的使用,需要重新改写为 Hive 支持的方式;或者直接就不能达到某些目的。
- 因为大部分 SQL 查询被转化为 MapReduce 去执行,因此查询速度不是很快,不支持实时查询。
接下来我们会为大家介绍 IBM BigSQL,它可以弥补 Hive 以上的不足。
回页首
BigSQL
BigSQL 是 IBM 推出的 Hadoop 之上的 SQL 产品,我们知道关系型数据技术最早就来源于 IBM,经过几十年的发展,IBM 在关系型数据库领域累积了非常先进的技术、经验,也拥有很多优秀的基于 RDBMS 的产品和应用。所以 IBM 就将这些先进的技术运用到了 BigSQL 当中,使得它无论从性能上、SQL 语法的支持上、与其他应用的集成上、安全性等方面都有了非常强大的功能。
BigSQL 重用了 Hive 的 Metastore,因此 Hive 里的数据和 BigSQL 里面的数据对彼此是互见的,保证了数据在 Hadoop 生态系统之间能够进行共享。
BigSQL 有两个版本,BigSQL 1.0 和 BigSQL 3.0(BigSQL 3.0 包含在 BigInsights 3.0 中,所以版本名采用了与 BigInsights 3.0 一致的名称),我们这里介绍的特性主要基于 3.0 版本。
BigSQL 3.0 将 IBM 在关系型数据库中积累的很多先进技术运用到了其中,最重要的一个特性是,用 MPP SQL 引擎替代 MapReduce,大大提高查询速度。当然,BigSQL 处理的原始数据仍然以文件的方式存在 HDFS 上。(请统一文中技术名词大小写问题。)
除此之外,还有很多其他方面的增强,后面我们会一一来看。
BigSQL 架构
我们先来看一下 BigSQL 的架构(图 4)。可以看到 BigSQL 也是一个主从的架构,主节点负责接收 Client 端发送的 SQL 查询,并编译、优化 SQL、生成并行的执行计划,然后分发给从节点或者叫做工作节点,从节点执行数据的读取、计算和存储。当然,我们要注意的是,BigSQL 集群不是独立于 Hadoop 集群之外的,它跟 Hadoop 的其他服务是共享节点的,比如说 BigSQL 的主节点可能同时是 HDFS 的 namenode、MapReduce 中的 jobtracker、HBase 的 hmaster 等;而从节点可能同时承担了 HDFS 中的 datanode、MapReduce 中的 tasktracker、HBase 中的 regionserver 这些角色。
主节点上,我们可以看到有一个叫做 Scheduler 的模块,这个模块比较重要,是用来负责调度的,后面我们还会详细的讲;还有一个橙色的部分,叫做 Catalog,这个 Catalog 其实是有两个意义的,我们一会儿再详细的讲。
每一个从节点上,我们可以看到它有一个 HDFS Reader/Writer,用于读取 HDFS 上的数据,这些 Reader/Writer 大部分都是由 C++写的,速度比较快。在从节点上还可以看到有个 Temp(s) 临时表,在处理的数据比较多或者我们的查询比较复杂时,比如涉及到多个表的连接查询,中间会产生一些临时表,这些临时表会被先存储下来,供后续的计算使用。这些临时表通常情况下会被尽量的 cache 在内存中,因此对提高查询速度有很大帮助。
图 4. BigSQL 3.0 架构

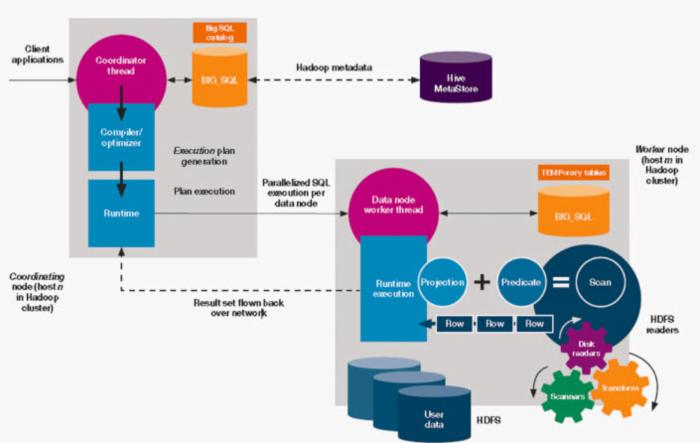
我们再来看下图 5,这幅图展示了 BigSQL 查询在执行过程中的一个情况。
图 4 里面我们提到过,在主节点中,有一个 Catalog 的概念,这个概念其实包含了两层意思,一个是 Hive 的 Metastore 这个 Catalog,是关于表的元数据信息(图 5 中紫色的部分);那么还有一个 Catalog 是 BigSQL 本身的 Catalog(图 5 中橙色的部分)。BigSQL 自己的 Catalog 存储的是关于表的统计信息,我们知道,在关系型数据库里面,在插入数据的时候,会产生一些统计信息,这些统计信息对于查询的优化是非常重要的。BigSQL 做了类似的事情,将这些统计信息存储在自己的 Catalog 里面,可以优化查询。这些统计信息怎么生成呢?BigSQL 提供了一条 ANALYZE 命令,通过运行这个命令,这些统计信息将会被收集到 Catalog 中。
当 Client 端发送一个查询到主节点,主节点的 Coordinator 线程会对 SQL 先进行解析、编译、优化,生成一个分布式的执行计划发送给各个从节点。那么主节点的 scheduler 在这个过程中会做两件事情,第一是查询 Hive 的 Metastore,得到表的元数据信息,这个元数据信息其中就包含了每一块儿的数据它的存放位置,从而将计算分配到合适的点上,尽量保证计算和数据在同一个节点上,这个跟 MapReduce 的理念是一样的,也就是将计算往数据的节点上推送,而不是将数据移动到计算节点上。
第二件事情是,如果存在分区表,先排除掉与查询无关的分区。
右侧的部分是从节点上做的事情,我们可以看到里面有很多的 projection、predicate 等很多很多关系型数据库技术里面用到的优化方法,这些是直接重用的关系型数据库引擎里面的功能。
图 5. BigSQL 查询执行过程
BigSQL 主要特性
1. 支持 SQL 2011 标准语法
BigSQL 对 SQL 语法的支持能够达到与 DB2 类似的高度。基本上,企业以前在数据库、数据仓库上的 SQL 可以不用改动或者非常少的改动就可以直接在 BigSQL 里面运行,这个我们来讲是非常高效的事情。
2. 性能大大提升
除了刚才我们已经讲过的利用了很多数据库领域的技术提高性能之外,以下几个方面也对性能提升有所帮助:
1)它的分布式概念有横向和纵向两个方面:
第一个是所有的工作发送给不同的节点来并行执行;还有一个是在每个从节点上,也可以启动多个线程进行计算。
2)另外,BigSQL 还支持自动根据每个从节点上的负载状况去动态调整内存的配置。
3)大部分的 I/O 引擎、运行时引擎、函数等等都是 native code,执行速度比较快。
3. 应用集成
与其他应用的集成这个特性,可以分两个部分来看:
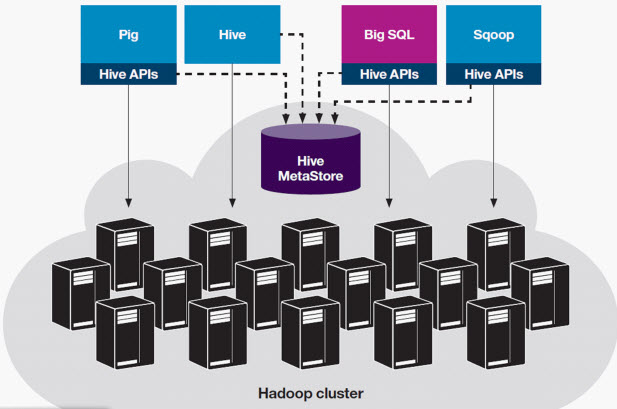
(1)是否能够跟 Hadoop 生态系统里面的其他应用集成。 这个比较显然,因为 BigSQL 跟 Hive 共享 Metastore,而 Hive 里面的数据能够被 Hadoop 生态系统里面的其他很多产品访问,所以 BigSQL 里面的表跟 Hive 里面的表实质上就是一回事,那么 BigSQL 里面的表就可以被其他很多产品访问。从图 6 中可以看到,Pig 可以通过 Hive 的 API 来访问 Hive 中的数据;Sqoop 也可以通过 Hive 的 API 去访问 Hive 数据;BigSQL 可以通过 Hive 的 Metastore 访问数据,也可以通过 Hive 的 API 访问数据。
图 6. Hadoop 生态系统共享 Hive Metastore
(2)是否能够跟基于关系型数据库技术的一些应用(比如 BI 工具)方便的集成。BigSQL 支持市面上所有常用的 Driver,包括 JDBC、ODBC、.Net 等等,同时支持很多种语言来访问。
从跟一些 BI 分析工具的集成来说,我们来衡量这个集成好不好其实有两个方面,一个是数据能不能被 BI 访问;第二是访问的性能怎样。影响性能的方面也有两个,第一个是底层的技术对 SQL 语法的支持是否足够丰富;第二个是对 SQL 查询的优化做的是否足够。为什么这么说呢?我们拿关系型数据库举个例子,BI 工具比如 Cognos,是一个上层的应用;底层它使用的是数据库存储数据,将 Cognos 的 ETL 操作转化为 SQL 执行。如果数据库对 SQL 语法支持的比较丰富,同时性能调优的工作做的比较好,那么底层的这部分工作就会由底层的数据库去承担,BI 基本上不用承担太多的工作。但是如果数据库对 SQL 语法支持的不好或者性能调优做的不好,那么这个性能会大打折扣,因为它需要将很多的工作推回到 BI 工具去做。
综合起来,BigSQL 拥有与 DB2 类似的 SQL 语法支持;BigSQL 支持与 DB2 类似的 Driver;BigSQL 对查询的优化重用了关系型数据库里面的很多技术,这几个方面加起来使得利用 BigSQL 来处理数据仓库使这样一个需求变得容易很多。
4. 联邦
数据从来不是信息孤岛,很多时候我们需要将很多来自不同数据源的数据集成到一起进行分析。BigSQL 提供了联邦 Hadoop 和其他关系型数据库的能力。那么在查询存储在其他关系型数据库或者数据仓库中的数据时,考虑到不同的数据库底层的工作机制不太一样,它会尽量利用原有数据库本身的功能对 SQL 进行优化,而不是自己负责这部分工作,因为原有的数据库系统在这方面应该做的更好。
5. 安全性和审查方面的功能
BigSQL 支持 LDAP、Kerberos、本地系统等验证方式;同时在用户授权方面也支持的比较丰富,比如完全的基于 GRANT/REVOKE 的授权、基于角色组的授权,同时也支持比表级别更细粒度的权限控制,比如行安全和列安全,这个与关系型数据库里面是类似的。
除此之外,通过 BigSQL 我们也可以制定审查的规则来监控用户对 Cluster 访问的动作。
如何使用 BigSQL
连接使用 BigSQL 有三种方式,第一个是利用 Jsqsh 这个命令行工具来访问 BigSQL,执行 SQL 语句;第二种是在 Eclipse 里面开发 BigSQL 的应用;第三,其他应用程序可以通过 JDBC/ODBC driver 来直接访问 BigSQL。
我们这里来简单介绍一下最简便的命令行 Jsqsh 来访问 BigSQL。Jsqsh 是一个开源的命令行 JDBC 客户端,如果想要了解它的详细信息,可以访问: http://jsqsh.wiki.sourceforge.net
下面我们以一个查询的例子来演示在 BigSQL 下创建表、加载数据、查询数据,并与 Hive 中执行 SQL 查询进行对比,最后利用 BigInsights 里面可视化展示工具 BigSheets 来展示 BigSQL 的分析结果。
Jsqsh 命令位于$BIGINSIGHTS_HOME/jsqsh/bin 目录下,可以直接运行这个命令进入交互式命令行。利用 Jsqsh 的”/connect –l” 查看目前建立到 BigSQL 的连接有哪些:

可以看到,默认情况下已经创建了两个连接,一个名为 BigSQL,对应 driver 为 db2;另外一个名为 BigSQL1,对应 driver 为 BigSQL。第二个连接对应于 BigSQL 1.0(为了向后兼容性,目前 BigSQL 的版本既包含了新版本 3.0 的功能,也包含了旧版本 1.0 的功能),我们这里使用已经默认创建好的“BigSQL”连接。使用“/connect BigSQL”,并输入用户名对应的密码,进入到与“BigSQL”的连接中。当然您也可以通过“/connect –a=myconn1”的方式添加新的连接使用。

我们此次实验环境使用的是一个比较小的集群,一共 3 个节点,当然实际生产环境中,集群内的节点数远远大于 3,查询性能比实验得到的数据也应该更优。
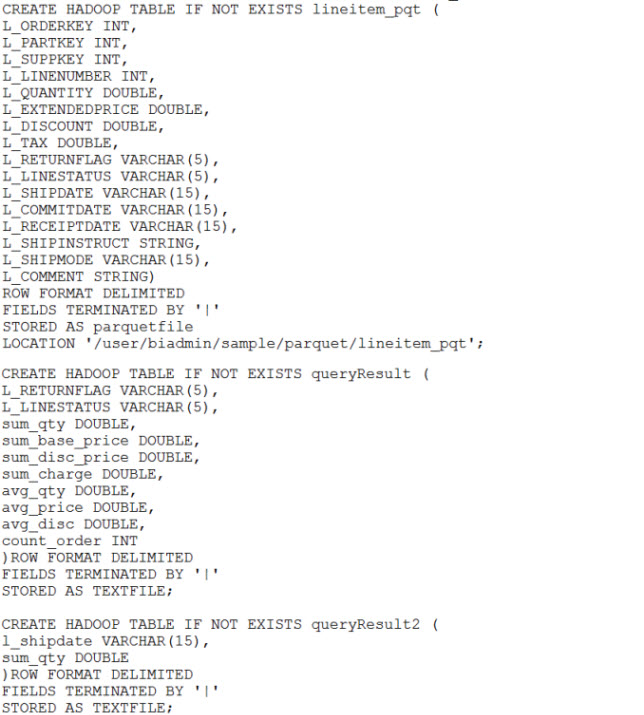
首先,我们创建一个 lineitem 表,这个表里面包含了订单信息,里面包含订单号、供应商、数量、价格、发送日期等等,这个表以最简单的 textfile 格式存储,然后将数据加载到表中(一共加载大约 600 多万条数据)。我们看一下建表和加载数据的 SQL 语句:
图 7. lineitem 建表和加载数据

然后我们再创建另外三个表:lineitem_pqt、queryresult、queryresult2。lineitem_pqt 与 lineitem 表类似,但是以 parquet 压缩的方式来存储数据;queryresult 和 queryresult2 两个表来存储查询结果:
图 8. 创建 lineitem_pqt 和查询结果表
由于我们原始的数据是普通的 text 格式,我们可以借助 Hive 的命令,将数据转化为 parquet 方式并存储到 lineitem_pqt 表中:
[biadmin@loaclhost BigSQLSample]$ /opt/ibm/biginsights/Hive/bin/Hive Logging initialized using configuration in file:/opt/ibm/biginsights/Hive/conf/Hive-log4j.properties Hive> INSERT OVERWRITE TABLE lineitem_pqt > SELECT * FROM lineitem;
到此为止,我们的表和数据已经准备好了,为了提高查询速度,通过在 BigSQL 中运行 ANALYZE 命令来生成关于表的统计信息:
ANALYZE TABLE lineitem_pqt COMPUTE STATISTICS FOR COLUMNS l_shipdate ,l_returnflag,l_linestatus;
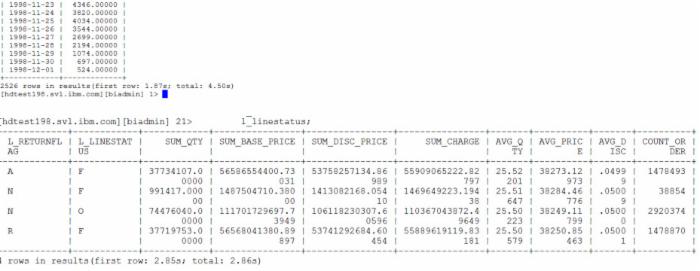
接下来我们来执行查询,这里有两个查询,第一个查询查找日期在某一范围内的分组求和信息;第二个查询稍微复杂一些,从 lineitem_pqt 中查找日期在某个范围内的记录,并对记录进行更多的统计计算(分组求和、分组求平均值等)。第一个查询共返回 2526 条记录,花费 1.87s 返回第一条记录;第二个查询一共返回 4 条记录,耗时 2.86s。
图 9. BigSQL 执行查询
接下来,我们以第一条简单的查询为例来看一下在 Hive 中,同样的查询需要的时间:
图 10.Hive 执行查询
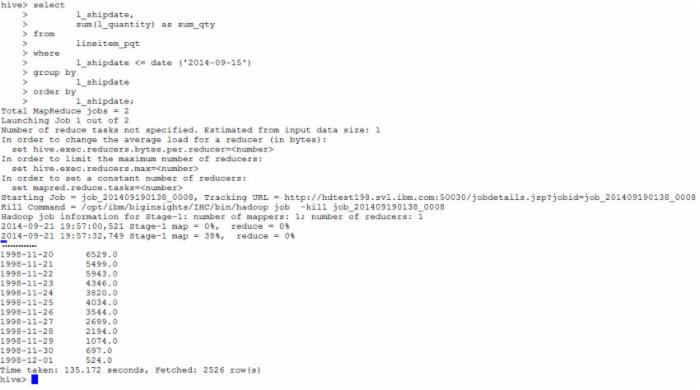
Hive 通过启动了两个 MapReduce 作业来运行这个查询,总共耗时 135.172s 的时间,在同一个集群上执行同一个查询远远长于 BigSQL 的时间。
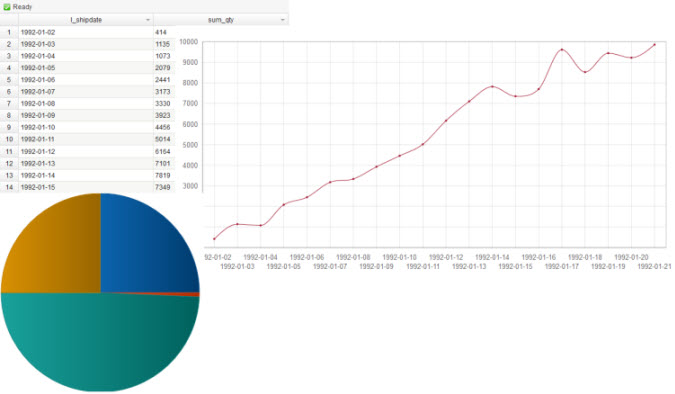
BigSQL 同时还能跟 BigInsights 中的可视化工具 BigSheets 进行集成,通过 BigSheets 来展示 BigSQL 中的分析结果:
图 11. 利用 BigSheets 展示查询结果
回页首
结束语
IBM BigSQL 作为 BigInsights 的一个重要功能,提供了海量数据之上基于 SQL 的实时查询能力,无论从 SQL 语法支持上、性能上、安全性上还是企业应用集成上,都有着不俗的表现。BigSQL 里面重用了非常多关系型数据库里面大家比较熟悉的技术,所以如果您是一个数据库方面的专家,您会发现使用 BigSQL 去分析 Hadoop 上的数据会非常得心应手。关于 BigSQL 更详细的信息和使用方法请参考 IBM BigInsight Info Center 。
回页首
附加免责说明
本文不带有任何明示或暗含的保证。文章提供的建议只作为一般的经验分享,作者不保证这些建议在任何情况下都有效。本文中任何带有主观性的陈述都只代表本文作者个人的观点,不代表 IBM 公司的官方立场。相关细节,请直接咨询作者。
正文到此结束
- 本文标签: 安全 数据 编译 智能 ip 集群 sqoop mysql API IBM value 银行 apr UI ldap Apache Drill eclipse cat sql 管理 tab key 理财 Datanode Region web 时间 db 企业 产品 HMaster 大数据 Hadoop Select Namenode 配置 apache 需求 node 开源 线程 HBase Facebook 翻译 解析 js HDFS map 目录 代码 db2 开发 数据库
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

