antlr4操作入门(java版本)
背景
最近在学习github上的一个mlsql项目的时候,发现了antlr这一强大的语言解析工具。上网搜罗了很多资料,基本都是概念原理之类,示例也比较单一,看了之后难以上手。为了帮助初次接触antlr的童鞋们能够快速运用antlr做出东西来,遂出此文,希望能帮助到迷茫中的朋友。(本人渣渣一枚,没有什么语言解析的基础,仅仅帮助大家使用工具,不谈原理)概要
本文参照mlsql,定义一种数据加载规则,使用antlr,实现spark加载各种数据源的功能环境准备
环境:java8+maven+idea 插件:安装idea-antlr4的插件(file-->setting-->plugins-->install plugin from disk) 插件下载antlr前端
一些概念
- 前端:定义语法规则,antlr通过g4文件来定义
- lexer:词法解规则,就是将一个句子多个字符进行组装分成多个单词的规则
- parser:语法解析,对分词后的整个句子进行解析,可以对每个分词单元做出自定义的处理,从而来实现自己的语法解析功能。
g4文件
g4文件是antlr生成词法解析规则和语法解析规则的基础。该文件是我们自定义的,文件名后缀需要是.g4。g4文件的结构大致为:- grammar
- comment(同java //)
- options
- import
- tokens
- @actionName
- rule 我们需要关注的主要是grammar与rule
grammar
grammar是规则文件的头,需要与文件名保持一致。当antlr生成词法语法解析的规则代码时,类名就是根据grammar的名字来的。rule
rule是antlr生成词法语法解析的基础。包括了lexer与parser,每条规则都是key:value的形式,以分号结尾。lexer首字母大写,lexer小写。g4文件的编写与解释
grammar Dsl; //定义规则文件grammar
@header { //一种action,定义生成的词法语法解析文件的头,当使用java的时候,生成的类需要包名,可以在这里统一定义
package antlr;
}
//parsers
sta:(sql ender)*; //定义sta规则,里面包含了*(0个以上)个 sql ender组合规则
ender:';'; //定义ender规则,是一个分号
sql //定义sql规则,sql规则有两条分支:select/load
: SELECT ~(';')* as tableName //select语法规则,以lexer SELECT开头, 以as tableName 结尾,其中as 和tableName分别是两个parser
| LOAD format '.' path as tableName //load语法规则,大致就是 load json.'path' as table1,load语法里面含有format,path, as,tableName四种规则
; //sql规则结束符
as: AS; //定义as规则,其内容指向AS这个lexer
tableName: identifier; //tableName 规则,指向identifier规则
format: identifier; //format规则,也指向identifier规则
path: quotedIdentifier; //path,指向quotedIdentifier
identifier: IDENTIFIER | quotedIdentifier; //identifier,指向lexer IDENTIFIER 或者parser quotedIdentifier
quotedIdentifier: BACKQUOTED_IDENTIFIER; //quotedIdentifier,指向lexer BACKQUOTED_IDENTIFIER
//lexers antlr将某个句子进行分词的时候,分词单元就是如下的lexer
//keywords 定义一些关键字的lexer,忽略大小写
AS: [Aa][Ss];
LOAD: [Ll][Oo][Aa][Dd];
SELECT: [Ss][Ee][Ll][Ee][Cc][Tt];
//base 定义一些基础的lexer,
fragment DIGIT:[0-9]; //匹配数字
fragment LETTER:[a-zA-Z]; //匹配字母
STRING //匹配带引号的文本
: '\'' ( ~('\''|'\\') | ('\\' .) )* '\''
| '"' ( ~('"'|'\\') | ('\\' .) )* '"'
;
IDENTIFIER //匹配只含有数字字母和下划线的文本
: (LETTER | DIGIT | '_')+
;
BACKQUOTED_IDENTIFIER //匹配被``包裹的文本
: '`' ( ~'`' | '``' )* '`'
;
//--hiden 定义需要隐藏的文本,指向channel(HIDDEN)就会隐藏。这里的channel可以自定义,到时在后台获取不同的channel的数据进行不同的处理
SIMPLE_COMMENT: '--' ~[\r\n]* '\r'? '\n'? -> channel(HIDDEN); //忽略行注释
BRACKETED_EMPTY_COMMENT: '/**/' -> channel(HIDDEN); //忽略多行注释
BRACKETED_COMMENT : '/*' ~[+] .*? '*/' -> channel(HIDDEN) ; //忽略多行注释
WS: [ \r\n\t]+ -> channel(HIDDEN); //忽略空白符
// 匹配其他的不能使用上面的lexer进行分词的文本
UNRECOGNIZED: .;
插件配置生成代码
- 创建一个maven项目
- 将Dsl.g4文件放入项目中
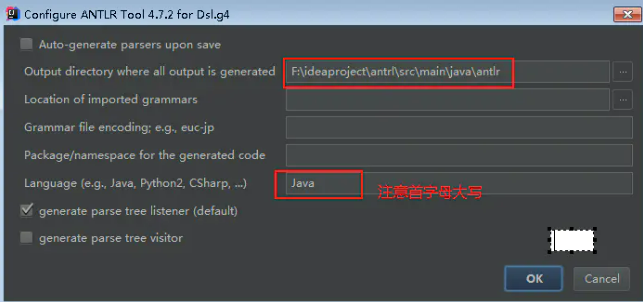
- 配置antlr插件的config
configure


- 生成代码
 generate
generate
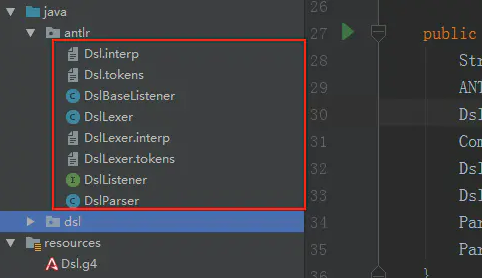
生成代码解释
- DslLexer 词法解析类
- DslParser 语法解析类,在类中有各种Context,每个parser都赌对应了一个xxxContext的内部类,在Context中记录了与其他Context的包含关系,还提供了获取parser中的lexer的方法,以及进出这个rule的回调函数
- DslListener 语法解析监听器。antlr有listener和visitor两种遍历方式,前面配置的时候选择的是listener,因此只生成了listener。 在Listener中提供了进入和退出每一种规则的回调方法。我们可以通过实现Listtener类,按需覆写回调方法,以此来实现我们的业务。
antlr后端
简单使用
- 添加依赖
<dependency> <groupId>org.antlr</groupId> <artifactId>antlr4-runtime</artifactId> <version>4.7.1</version> </dependency>- 打印解析树
public static void main(String[] args) throws IOException { String sql= "Select 'abc' as a, `hahah` as c From a aS table;"; ANTLRInputStream input = new ANTLRInputStream(sql); //将输入转成antlr的input流 DslLexer lexer = new DslLexer(input); //词法分析 CommonTokenStream tokens = new CommonTokenStream(lexer); //转成token流 DslParser parser = new DslParser(tokens); // 语法分析 DslParser.StaContext tree = parser.sta(); //获取某一个规则树,这里获取的是最外层的规则,也可以通过sql()获取sql规则树...... System.out.println(tree.toStringTree(parser)); //打印规则数 }load语法实现
功能解说
load的语法: load json.'F:\tmp\user' as temp; 通过类似的语法,实现spark加载文件夹的数据,然后将数据注册成一张表。这里的json可以替换为spark支持的文件格式。实现思路
如load json.'F:\tmp\user' as temp这样一个sql,对应了我们自定义规则的sql规则里面的load分支。 load-->LOAD,json-->format,'F:\tmp\user' -->path, as-->as,temp--> tableName。 我们可以通过覆写Listener的enterSql()方法,来获取到sql规则里面,与之相关联的其他元素,获取到各个元素的内容,通过spark来根据不同的内容加载不同的数据。实现代码
ps:由于近期使用,只是大致调试整理了下,仅仅只是为了方便初接触的朋友快速用起来,要深入就要靠自己了,可能有很多错误和见解疏漏的地方,还请大家莫要介意。public class ParseListener extends DslBaseListener { @Override public void enterSql(DslParser.SqlContext ctx) { String keyword = ctx.children.get(0).getText(); //获取sql规则的第一个元素,为select或者load if("select".equalsIgnoreCase(keyword)){ execSelect(ctx); //第一个元素为selece的时候执行select }else if("load".equalsIgnoreCase(keyword)){ execLoad(ctx); //第一个元素为load的时候执行load } } public void execLoad(DslParser.SqlContext ctx){ List<ParseTree> children = ctx.children; //获取该规则树的所有子节点 String format = ""; String path = ""; String tableName = ""; for (ParseTree c :children) { if(c instanceof DslParser.FormatContext){ format = c.getText(); }else if(c instanceof DslParser.PathContext){ path = c.getText().substring(1,c.getText().length()-1); }else if(c instanceof DslParser.TableNameContext){ tableName = c.getText(); } } System.out.println(format); System.out.println(path); System.out.println(tableName); // spark load实现,省略 } public void execSelect(DslParser.SqlContext ctx){ } public static void main(String[] args) throws IOException { String len = "load json.`F:\\tmp\\user` as temp;"; ANTLRInputStream input = new ANTLRInputStream(len); DslLexer lexer = new DslLexer(input); CommonTokenStream tokens = new CommonTokenStream(lexer); DslParser parser = new DslParser(tokens); DslParser.SqlContext tree = parser.sql(); ParseListener listener = new ParseListener(); ParseTreeWalker.DEFAULT.walk(listener,tree); //规则树遍历 } } - 生成代码


正文到此结束
热门推荐










相关文章

近期评论
-
不会英语啊。
-
前100名用户会展示特殊的纪念徽章
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
-
哥太牛了
-
是呀,看您的IP显示在美国,还以为您移民了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

