大规模数据集成: Linked Data
在本系列的前两篇文章(“ 使用 RDF 创建数据网络 ” 和 “ 使用 SPARQL 查询 RDF 数据 ”)中,您了解了资源描述框架和 SPARQL 协议和 RDF 查询语言 (SPARQL),它们是万维网联盟 (W3C) 的两个创建可移植、可查询、网络友好的数据的标准。RDF 的图表模型使得从各种来源积累有关一个主题的信息变得很容易。您现在已经知道了如何通过 HTTP 为本地查询接入 RDF 数据,或者向符合标准的服务器推送查询来避免传输不相关的数据。在这一期 大规模数据集成 中,将了解如何结合使用 RDF 和 SPARQL 与 Web 架构来创建和使用 Linked Data 。
Linked Data 原则
为了鼓励以一致的方式在网络上发布数据,Tim Berners-Lee 定义了 4 条 Linked Data 原则 :
- 使用统一资源标识符 (URI) 作为事物的名称。
- 使用 HTTP URI,使人们能够查找这些名称。
- 在有人查找一个 URI 时,可以使用标准(RDF*、SPARQL)来提供有用的信息。
- 包含其他 URI 的链接,以便他们可以发现更多的信息。
关于本系列
本系列介绍、探讨和应用全球标准,解决开发人员、架构师和数据管理员每天所面临的大规模数据集成难题。本系列文章介绍的一些跨平台的、独立于语言和应用程序的技术,支持在数据库、文档、电子表格、服务 API 中进行信息集成。您将了解的数据模型和工具可以让您的工作变得更轻松,并对您的组织产生实质性的影响。
在本系列文章中,现在应该不需要太多地解释这些原则背后的动机,但为明确了解这些动机,我将进行快速介绍。
首先,命名模式的用途是在共享的上下文中创建引用。这些引用应该一致、清楚明白而且无冲突。URI 标准提供了一种命名模式模式:一种创建命名模式的模式。只要您知道如何在系统中解析、表达以及可能存储 URI,就可以接受来自其他任何符合该标准的系统的标识符。这些系统可能包括目前编写和部署的,接受对未来符合 URI 的新名称的名称引用的代码。
URN
URI 的使用并不意味着 ISBN 对语义 Web 无用。统一资源名称 (URN) 是一种 URI,它允许通过命名空间前缀将外部命名模式映射到 URI 空间内。一本书的有效的 URN 可能为:urn:isbn:978-1608454303。
还存在其他全局命名系统。一种常见的模式是 国际标准书号 (ISBN)。ISBN 多年来对标准化图书的引用至关重要。该模式的成功主要源于,对命名系统的支持减少了突出出版和发行市场的成本和错误。不幸的是,ISBN 仅 引用图书。杂志、乐谱和视听产品(电影、电视节目、广播体育活动)都拥有不同的标识符模式。图书的主题可使用一种分层的分类模式来指定,比如 Dewey Decimal Classification 系统,但这是另一个不兼容的标识符系统。学术研究人员可通过 ORCID 标识符标识,但非学术领域没有这样的系统。因此,要表明一本(学术)图书是由一位特定的研究人员为一个已知主题编写的,不仅涉及到这 3 个不同的标识符,还涉及到 3 种不同的模式!拥有一种标准模式来引用所有这些事物,显然非常有意义。
请注意,Berners-Lee 的指导方针并不是说每个人都需要使用 同样的 URI。您可以使用 URI 标准实现基本的互操作性。这在人们对事物的叫法达成一致时非常好,但它们不需要一致。RDF 图表中的截点和链接标识符都属于此情况。
第二,即使任何 URI 感知系统可在外部数据集中使用一个 URI 标识符的引用,该系统的用户也可能不认识该标识符。不熟悉的标识符需要一种途径来查找它指向的事物。要找到指定实体的任何信息,摄入系统必须知道这样一种服务或拥有一种途径来发现它。因此,用户应用程序为使用特定的命名约定而需要支持的依赖关系和耦合增加了。
第二条原则为数据交换增添了巨大的价值。如果您的系统可使用 URI,如果它们是可解析的 URI(URL),那么(要了解它们引用的对象的更多信息),您可像其他任何 Web 资源一样对待它们,向它们发出一个 GET 请求。不需要发现任何单独的服务,在 HTTP 和它的统一接口之外不存在任何新依赖性。名称既是标识符,也是您可用来了解更多信息的手段。
第三个原则表明,除了在解析您的资源时您希望返回的其他任何自定义格式 ,如果您允许对标准数据模型进行标准序列化,那么解析系统不需要知道任何额外的信息来解析得到的结构。系统可能不知道这些标识符的含义,但通过第二条原则,它可以在任何想要了解更多信息时解析它们。除了标准序列化格式之外,对 SPARQL 协议等标准查询机制的支持还是的客户端能够询问有关您数据的问题。
“ Linked Data 是一种完全不同的方法,如果您拥有与企业和编程语言相关的解决方案,那么该方法能实现难以想象的生产力、规模和灵活性水平。 ”
因为第一条原则不需要使用标准标识符(仅标准标识符模式),所以同一个事物在不同的数据集中肯定具有多个名称。此问题可通过许多方式解决,但我不会花时间深入介绍。一般而言,您可以使用更高阶的语义关系(比如来自 Web Ontology Language (OWL) 的 owl:sameAs ),在标识符之间建立永久的等同关系。从那时起,您可以使用任何理解 OWL 语义的推理系统来查询任何等同的资源,从所有这些资源获取属性。这里的重点是,这些机制为您提供了将您的术语与其他术语联系起来的途径。这么做可以充实您的数据,帮助在数据集中实现可发现性。
总体上讲,这些原则非常适合公共和私有数据。不要认为所有这些技术仅是您想要放弃的免费的公共数据。到最后,它们都是 Web 资源,您可以将它们放在防火墙后,设置付费门槛,采用身份验证和授权模型。目的在于使用规模化的技术解决在各种不同的数据源之间连接信息的许多问题。与未基于网络友好的标准的更昂贵、零散且耗时的技术相比,满足该目标有助于将集成成为降低到几乎为零。
您只需要考虑 Linking Open Data 社区项目,就可以看到这些想法的大规模实现。
回页首
Linking Open Data 项目
2007 年,一小群人(Linking Open Data (LOD) 社区项目)开始将一系列公共数据集连接起来。在 图 1 中,可以看到前 12 个数据集关联在一起,这些数据集包括 DBpedia 、 GeoNames 和 US Census 信息。
图 1. 2007 年的 Linking Open Data 项目云

我稍后会更加详细地介绍 DBpedia。现在首先要指出的是,事实上,从 Wikipedia 提取的有关 Auburn, California 主题的信息来自 DBpedia。其他有关 Auburn 的信息可能是在 2000 U.S. Census 中生成的,一些可能来自 GeoNames 项目 。这 3 个数据集为同一个事物 (Auburn) 使用了不同的标识符,但借助幕后的细微调整,您可以看到 DBpedia 使用了 OWL sameAs 关系来连接术语。现在您可使用这 3 个术语中的任一个,通过基于 OWL 的推理系统查询数据和检索所有结果。(同样地,具体工作原理和原因不属于本文的讨论范围。)
在 清单 1 中,GeoNames 项目中的 Auburn 的 URI 等同于来自英语上下文的 Auburn DBpedia 资源。我随后会将 Auburn 的 Freebase 标识符连接到 DBpedia 资源。最后,我将 Auburn 标识符从日语 DBpedia 语言上下文连接到英语上下文。此刻,所有这 4 个名称彼此等同。其中任何一个名称指定为主题的三元组现在对它们都是正确的。
清单 1. 使用 OWL 连接标识符
# Connecting the DBpedia resource for Auburn, CA to three other # resources using owl:sameAs @prefix owl: <http://www.w3.org/2002/07/owl#> . <http://sws.geonames.org/5325223/> owl:sameAs <http://dbpedia.org/resource/Auburn,_California> . <http://rdf.freebase.com/ns/m.0r2rz> owl:sameAs <http://dbpedia.org/resource/Auburn,_California> . <http://ja.dbpedia.org/resource/オーバーン_(カリフォルニア州)> owl:sameAs <http://dbpedia.org/resource/Auburn,_California> .
需要记住的是,这些数据集来自不同的组织,不一定是 LOD 项目的成员生成的。但它们是使用标准表达的,这对让数据可供各种各样的客户端使用发挥着重要作用。一些数据以 RDF 格式原生地存储在文件中,一些存储在 3 个三元组存储中,一些存储在关系数据库中并根据需要表达为 RDF。Linked Data 技术的使用通常不会增加信息来源的负担。使用这些技术只是为了帮助解放信息,并轻松地将它们与相关内容联系起来。数据集之间的链接可与剩余内容混在一起,也可在一个 链接集 中保持分开。
回想一下上一篇文章,您可以通过 SPARQL 从多个数据来源拉入信息,只需使用 FROM 关键字引用它们即可。现在可以想象,让来源数据原封不动,但将标识符链接存储在一个文件中,就像 清单 1 中一样,并在 SPARQL 查询中引用该链接,就像 清单 2 中一样。出于查询的用途,每个数据来源中的术语之间的连接将包含在图表中,可用于执行基于推理系统的集成。
清单 2. 包含数据集和链接集的 SPARQL 查询
SELECT variable-list FROM dataset1 FROM dataset2 FROM linkset WHERE { graph pattern } LOD 项目最初的 12 个数据集就是以这种方式连接的。然后添加了更多数据集。数据集越来越多。该项目添加了新的数据集类别,涉及到学术研究引用,生命科学,政府生成的数据,演员、导演、影片、饭店信息,等等。到 2014 年,570 个代表着数十亿个 RDF 三元组的数据集建立了连接。可在 图 2 中看到截至 2014 年的 LOD 云图的摘要。在启用了 SVG 的浏览器中查看 交互式版本 会更有趣。如果单击大多数单独的数据集,则会跳转到相应的 Datahub 页面。
LOD 云图
LOD 图依照 CC-BY-SA 许可发布,可从该云的各个历史阶段 获得 。Linking Open Data 云图 2014 版,由 Max Schmachtenberg、Christian Bizer、Anja Jentzsch 和 Richard Cyganiak 创建。
图 2. 2014 年的 LOD 项目云
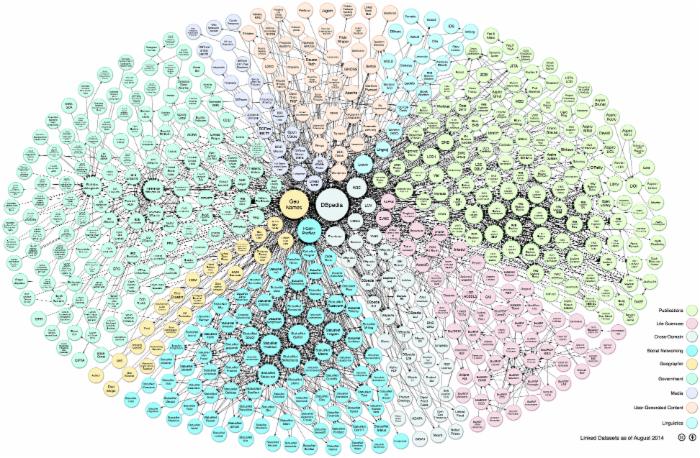
点击查看大图
关闭 [x]
图 2. 2014 年的 LOD 项目云
许多这些数据集都是使用描述相互链接的数据的 RDF 词汇表来描述的(还有其他工具可供使用吗?): Vocabulary of Interlinked Datasets (VoID)。是谁生成了它们?它们上次修改是何时?它们由多大?您可在何处找到链接集来将它们连接到其他数据?VoID 描述回答了这些问题。
让我们更深入地分析其中一个数据来源: DBpedia 。DBpedia 是对从 Wikipedia 提供结构化元数据的第一次尝试。DBpedia 的 VoID 描述将包含元数据,比如 清单 3 中的元数据。
清单 3. DBpedia 的 VoID 描述示例
@prefix void: <http://rdfs.org/ns/void#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix owl: <http://www.w3.org/2002/07/owl#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . @prefix dcterms: <http://purl.org/dc/terms/> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . @prefix wv: <http://vocab.org/waiver/terms/norms> . @prefix sd: <http://www.w3.org/ns/sparql-service-description#> . @prefix : <#> . :DBpedia a void:Dataset; dcterms:title "DBPedia"; dcterms:description "RDF data extracted from Wikipedia"; dcterms:contributor :FU_Berlin; dcterms:contributor :University_Leipzig; dcterms:contributor :OpenLink_Software; dcterms:contributor :DBpedia_community; dcterms:source <http://dbpedia.org/resource/Wikipedia>; dcterms:modified "2008-11-17"^^xsd:date; . :DBpedia_Geonames a void:Linkset ... . :FU_Berlin a foaf:Organization; rdfs:label "Freie Universität Berlin"; foaf:homepage <http://www.fu-berlin.de/>; . . .
从该描述中,您可以发现 DBpedia 是从 Wikipedia 提取的信息。尽管 Wikipedia 上的大部分内容都是非结构化的,但该站点包含海量经过编辑控制的结构。具体地讲,这些文章中的信息框是一致的,很容易以结构化方式获得其信息。因此,126 亿多个事物使用来自 119 种本地化语言上下文的 25 亿个 RDF 三元组惟一地描述,包括:
- 830,000 个人
- 640,000 个地点
- 370,000 个创造性作品
- 210,000 家组织
- 226,000 个物种
- 5,600 种疾病
每个主题是自己的资源,拥有自己的可解析标识符。在估计这里描述的主题的数量级和种类时,请记住这个多领域数据集是由自愿者维护和管理的。它包含 2500 万个图片链接、2800 万个文档链接,以及 4500 万个其他 RDF 数据集的链接。接近 3/4 的资源按来自多种本体论的类别组织。
每种资源拥有一个逻辑标识符、一个 HTML 渲染页面,以及一个 RDF/XML 序列号的直接链接:
http://dbpedia.org/resource/Auburn,_California # logical identifier http://dbpedia.org/page/Auburn,_California # HTML-rendered page http://dbpedia.org/data/Auburn,_California.rdf # direct RDF link
如果访问 逻辑资源 的链接,您会被重定向到 HTML 渲染的视图。发生这种情况是因为,您单击该链接时,浏览器请求以 HTML 作为其首选来源的响应。DBpedia 服务器将您重定向到渲染的表单。从这里,您可以探索 Auburn 与相关资源的连接,比如它的 报纸 ,它所在的 国家 ,以及在这里出生的 著名人物 。
这些 URI 都是资源引用,每个资源使用从 Wikipedia 提取的 RDF 来描述。您单击时看到的是 RDF 数据的 HTML 渲染结果,而不是该资源的网页。例如, Auburn Journal 拥有自己的网页,该页面可通过该报纸的资源的 http://dbpedia.org/ontology/wikiPageExternalLink 关系来找到。
我提到过大部分 DBpedia 资源都按多种本体论进行分类。具体地讲,这意味着资源是也属于 RDF 资源的类的实例。如果仔细查看 Auburn 资源页面,您会看到它是多个类的 rdf:type ,包括:
- http://www.w3.org/2003/01/geo/wgs84_pos#SpatialThing
- http://schema.org/City
- http://dbpedia.org/class/yago/CitiesInPlacerCounty,California
- http://dbpedia.org/class/yago/CountySeatsInCalifornia
请注意,这些是来自不同模式的不同类。很容易看到,可通过断言与有意义的信息的新 rdf:type 实例关系,随时添加更多类别。但是,这是一种集员关系。这意味着可以请求该数据集(或该类的实例)中包含的任何信息。如果单击 http://dbpedia.org/class/yago/CitiesInPlacerCounty,California 类别,就会看到 Placer County 内的其他城市,包括 Loomis 、 Rocklin 和 Roseville 。在这里,您会看到基于同一个县中的包含关系的一组相关城市。
http://dbpedia.org/class/yago/CountySeatsInCalifornia 类包含一个大得多的数据集。在这里,加利福尼亚的各个县的位置分类到一起,通过该关系,您可从一个县访问您知道的其他县。您导航的链接实际上是在后台处理的隐含 SPARQL 查询。一个等效的查询是:
SELECT ?s WHERE { ?s a <http://dbpedia.org/class/yago/CountySeatsInCalifornia> } 因为 DBpedia 支持 SPARQL 协议 (我已在上一篇文章中介绍),所以此查询可转换为一个直接 链接 。扩展的表单为:
http://dbpedia.org/snorql/?query=SELECT+%3Fs+WHERE+%7B%0D%0A+%3Fs+a+%3Chttp%3A / %2F%2Fdbpedia.org%2Fclass%2Fyago%2FCountySeatsInCalifornia%3E%0D%0A%7D
现在我将把我给出的一些信息组合到一个新查询中:
SELECT ?s ?page WHERE { ?s a <http://dbpedia.org/class/yago/CountySeatsInCalifornia> ; <http://dbpedia.org/ontology/wikiPageExternalLink> ?page . } 我添加了一种与前一个查询的额外关系。现在的要求是:“向我显示加利福尼亚州的所有县和与它们关联的外部网页。” 这是一个强大的查询,能够将从 Wikipedia 自动提取的数据集中到一起。可以在 此处 看到结果。
现在更改查询中的一个简单的东西。不查询 http://dbpedia.org/class/yago/CountySeatsInCalifornia 类中包含的资源,而使用 http://dbpedia.org/class/yago/CapitalsInEurope :
SELECT ?s ?page WHERE { ?s a <http://dbpedia.org/class/yago/CapitalsInEurope> ; <http://dbpedia.org/ontology/wikiPageExternalLink> ?page . } 结果可在 此处 获得。仅更改类名会导致结果现在反映了与欧洲大陆各国的首都关联的外部网页!
如果我更改我所查找的与按这种方式分类的资源相链接的关系,我可以询问另一个完全不同的问题。此查询请求纬度和经度信息,而不是外部链接:
SELECT ?s ?lat ?long WHERE { ?s a <http://dbpedia.org/class/yago/CapitalsInEurope> ; <http://www.w3.org/2003/01/geo/wgs84_pos#lat> ?lat ; <http://www.w3.org/2003/01/geo/wgs84_pos#long> ?long . } ORDER BY ?s 结果可在 此处 获得。
应该很容易想象从这样一个查询检索信息,并在 Google Maps 上显示它。完成此查询的结果如 图 3 中所示,您可以在 此处 与结果进行交互。考虑需要更改多少代码,才能找到和直观地表示所有欧洲国家的国家元首的出生地。(提示:基本上已完成了。)
图 3. 来自的 DBpedia 的欧洲首都城市
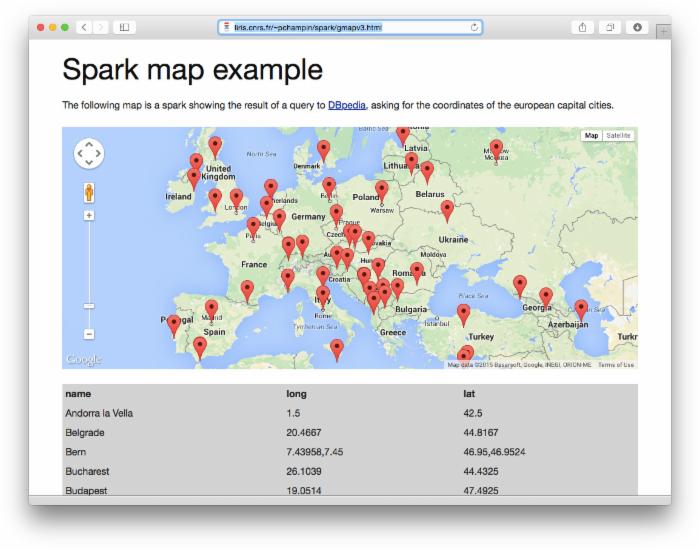
点击查看大图
关闭 [x]
图 3. 来自的 DBpedia 的欧洲首都城市
有了机制之后,很容易想象如何询问有关任意领域的其他问题。我最喜欢的 DBpedia 查询(我从 Bob DuCharme 获得)是 找到 “辛普森一家” 每一集开头黑板上写的字。 访问这些链接时,请记住每一集也是包含该集的导演、特邀嘉宾、重要角色等的链接。每一集分类为一个特定年份的一些电视节目中的成员。通过访问这些类的成员链接,您可找到在大体相同的时间段播放的其他电视剧集。
现在,您可以询问 DBpedia 能够想到的任何问题。请记住,DBpedia 仅是 LOD 云中包含了接近 600 个数据集中的一个。Linked Data 以相对较少的人为工作生成了令人难忘的结果。
回页首
结束语
考虑您的组织会花多长时间来集成单个新的数据来源。Linked Data 是一种解决该问题的完全不同的方法,如果您拥有与企业和编程语言相关的解决方案,那么该方法能实现难以想象的生产力、规模和灵活性水平。此方法不会限制面向公众的数据的适用性。您可以在您的防火墙后轻松地应用同样的理念。
Linked Data Fragments
一个小组提出了一种称为 Linked Data Fragments 的新方法,用以解决可靠地查询链接数据的问题。这还不是标准化的方法,但它有许多不错的理念可以分析一下。
Linked Data 没有魔力。解析为标准数据模型的标准序列化的标准标识符是一组简单(尽管可能不直观)的概念。但是,从工程角度讲,在网络上开放地支持 SPARQL 协议是一件非常困难的事。很难预测随机的个人会给您的服务器带来哪些负载。我们经过了许多努力来让 DBpedia 正常运行。您可在网站上进一步了解该流程。
在下一篇文章中,我将介绍一个基于这些理念的软件平台,最终开始介绍我们选择继续使用的开放生命周期协作服务 (OSLC) 技术。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

