前端开发中务必要转义的三处场景
出于这样或那样的原因,我们在传输、存储、展现字符串时需要进行转义操作,防止不可控的事情发生。下面我将分三处场景描述,有的里边确实有坑,希望大家看完后都有所收获。欢迎积极留言补充。
场景1:使用URL
前端开发中,我们经常会使用到URL,比如博客查询的表单action:"http://eastme.me?q=前端"、Ajax发送Get/Post请求、跳转至网址:"http://www.eastme.me/个人简介"等等。这些请求的URL经常会出现汉字,尤其是当表单提交时,我们无法知道用户输入的是什么内容,传递的参数是否包含中文。
标准URL只能使用英文、数字、某些部分标点符号,包含汉字的URL是无法直接使用的。浏览器对待此事毫不含糊,假如我们请求了上述包含汉字的地址,它会帮我们做些转义工作。然而不幸的是, 不同浏览器 在 不同的操作系统 , 不同的网页编码 , 不同的请求方式 下,使用的编码方式大相径庭。比如网址路径用的是UTF-8的编码,而查询字符串使用的是操作系统的编码。详细请参见阮一峰: 关于URL编码 。
于是,我们必须赶在浏览器之前对URL进行统一编码,JavaScript为我们提供了三种编码函数,分别是escape、encodeURI、encodeURIComponent。
在Web2.0时代,Ajax的兴起成就了越来越多的无刷新应用。我们在使用ajax提交表单,获取数据时,包含中文的URL和参数等项务必进行提前编码,防止兼容问题的发生。
还有一个问题需要引起注意,当表单提交时,空格会被转成+号。例如在搜索引擎中搜索"a b"时,搜索结果页会给出类似"xxx.com/s?q=a+b"这样的URL,而当真正搜索+号时,浏览器会将其转为"%2B"以示区分。当使用Ajax发送Post请求时,请求实体中的参数不会被转义,如果需要与get请求保持一致,需要使用encodeURIComponent进行显示转义。目前三个转义函数中,仅encodeURIComponent函数会对"+"号进行转义。
所以,我们在设计API时,尽量要使用英文,数字,下划线等无须编码就可直接使用的URL,从而防止不必要的兼容问题;我们在传递参数时,需要一直替浏览器做一下转义操作,以保持不同情况下系统的稳定性。
场景2:表单提交或本地数据存储
永远不要相信用户输入的内容。为了防止XSS攻击,我们需要对用户提交的表单进行HTML标签转义处理。有些场景诸如评论系统、搜索引擎自动完成,系统会将用户输入的内容再次吐出来显示到页面上。XSS攻击的原理很简单,某个用户输入脚本通过某种途径嵌入到页面上,这段脚本便会在任何访问此页面的客户终端上再次执行。最后可能造成的影响有轻有重,不堪设想。
举一种最为常见的XSS攻击的例子。本文下方有一个评论框,当有人评论时,评论的内容会跟随文章展示出来。假如评论内容未经限制,某人输入的评论为“<srcipt>alert('XSS')</script>”,系统在保存和展示时均未经转义处理,将这段字符串无差异输出到页面上,那么任何一个访问此篇文章的人都会看到弹出一个提示框:alert("XSS")。
所以,当涉及到此类表单时,一定要慎重。不论是在保存时,亦或是展现时,是在前端,亦或是后端,只要在其中一环对数据进行转义处理,就可以避免这种简单XSS攻击。
场景3:使用JavaScript渲染页面
现在,页面上的一些功能经常会异步渲染,当用户点击时,才会通过Ajax异步获取数据,然后经JavaScript解析后渲染成HTML片段,最后拼接在页面上。假如返回的数据内容不可控,则需要尽可能的转义以保证渲染正确。
举一个搜索引擎常用的auto-complete的例子。当用户输入内容时,客户端发起Ajax请求,在非常短暂(10-100ms)的时间内将推荐词返回值客户端,通过脚本拼接成HTML片段,展示在输入框的下方。如下图所示:
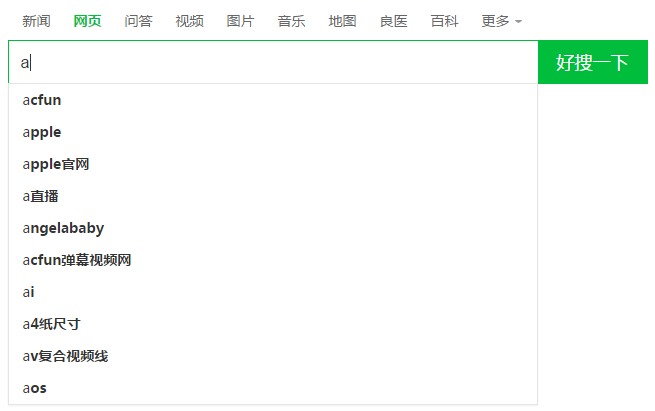
服务端返回的数据是这样的:
suggest_so({"query":"a","result":[{"word":"acfun"},{"word":"apple官网"},{"word":"adidas"},{"word":"angelababy"},{"word":"acfun弹幕视频网"},{"word":"apple"},{"word":"a直播"},{"word":"ai"},{"word":"a4纸尺寸"},{"word":"av复合视频线"}],"version":"3.2.1","rec":"acfun"}); 这是以jsonp实现跨域的一种数据格式,暂且不管jsonp和格式如何,我们只知道返回的仅仅是字符串,展现和交互都需要前端来处理。
有人会想,这个很简单。拿到json字符串,转成对象,拼接到一个<ul>标签里,不就可以了吗?其实就是这样的,我们写的脚本可能是这样的:
var s = "<ul>"; //开始for遍历 s += "<li data-word='" + result[i].word + "'>" + result[i].word + "</li>"; //结束遍历 s += "</ul>"; $('#auto-c').html(s);
但我们必须明白一点,用户的输入内容是不可控的,那么服务器返回的推送数据也同样不可控。假如其中一项word包含HTML标签或单双引号且不经转义,最后会拼出类似这样的字符串插入到页面上:
<ul> <li data-word='don't push me'>don't push me</li> </ul>
上面的例子中,data-word = 'don'。
再看类似的一个例子,现在很多搜索引擎都会做本地存储,将用户输入的词保存下来,点击时提示:
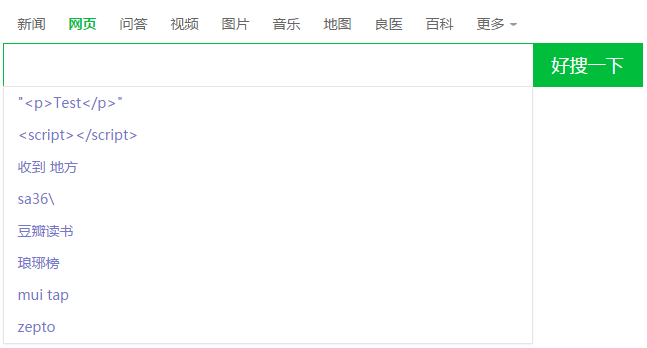
这对HTML的转义要求更高。假如上面的auto-complete服务端可以为我们过滤掉"<",">"等HTML标签,这里服务器什么也做不了。所有的数据均存储在Local Storage中。假如不对HTML标签转义,最后拼接出来的字符串可能会变成这样:
<ul> <li data-word=""<h1>Test</h1>"">"<h1>Test</h1>"</li> </ul>
上面的例子中,不仅data-word变为空,内容Test也将变为h1格式。
所以,当我们使用JavaScript渲染页面时,假如是不可控的内容,做一次HTML标签转义是很有必要的。
结语
第三个场景中,使用了jQuery的html方法将HTML片段附加在页面上,这也是我们最为常用的一种方式。事实上改变DOM内容或节点属性方式不止一种。想象一下,假如现在有一个变量为
var s = "<p>一个小学生 - 博客园</p>" DOM中有一个节点ID为demo,下面几种方法哪个会原样输出,哪个又会解析成段落呢?
1.document.getElementById('demo').innerHTML = s; 2.document.getElementById('demo').setAtrribute('data-word',s); 3.var t = document.createTextNode(s);document.getElementById('demo').appendChild(t); 4.document.getElementById('demo').innerText = s; // No FireFox 5.$('#demo').html(s); 6.$('#demo').text(s); 7.$('#demo').attr('data-word',s); 其实很简单,只有 innerHTML 和jQuery的 html 方法把字符串解析成p标签。这两种情况下,假如我们就是为了显示出"<p>",则要进行转义,防止结果超出预期。
PS:有人说jQuery的html方法和innerHTML一样嘛不是,好像都是那么点功能。这只能说明你把jQuery想象的太简单了。html方法有原生innerHTML所不能具备的很多特性,而这些特性往往正是我们需要的。比如说,假如代码片段中有脚本,不管是外链还是inline,html方法会请求外链文件,并执行脚本,而innerHTML则会装作看不懂的样子,什么都不做。
关于HTML转义,还有一个深坑,那就是空格。我建议不要对空格进行转义,并没有什么用,反而会带来意想不到的兼容性问题。

键盘输入的空格和HTML转义的空格是两回事,当我们对空格做了转义时,虽然取到的数据仍然是空格,而不是 ,但是其与真正的空格完全不一样。
所幸,"<"与"<",">"与">"," " "与""" 等等不会有这样的问题。
请一定要记住,   !== ' '
关于前端开发中的转义,肯定还有很多需要注意的地方,这些东西往往不是书本中可以学来的,坑很多,踩一踩才能长记性。分享出来让更多人避免同样的困扰,是我写这篇文章的初衷。欢迎你们留言补充!
(全文完)
正文到此结束
热门推荐









相关文章

近期评论
-
https://www.newcmy.com/register?aff=HBVX
建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。 -
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

