DNN的隐喻分析:“深度学习”,深在何处
【编者按】 DNN现在已经被互联网公司广泛使用 ,但大众对深度学习的理解水平并不一致。Nuance的这篇文章从另外一个角度来审视DNN技术的演进——分析隐喻如何作为强大的工具来引导我们的思维进入新视野,同时又引诱思维步入新的误区。作者告诫说:不要被“深度学习”的隐喻冲昏头脑。
隐喻在流行文化中和科学界随处可见。“埃尔维斯是摇滚乐之王”就是一个例子。严格说来,摇滚乐界并不是一个王国,但这里借用“王”这个字,我们会脑补出一个王国:那里有各位不同地位的歌手,以及浩浩荡荡的簇拥人群(即他们的粉丝团)。回到“深度学习”这个词,它纠缠在错综复杂的隐喻网中。真的有足够复杂的机器能够显示出像人类一样的学习能力?学习这种抽象的行为又何谓“深度”(亦或浅度)?我在这篇文章里将探究这些问题。
《机械姬》、《她》、《模仿游戏》等等电影不断在冲击着银屏,围绕“深度学习”的激动画面也层出不穷。出于消遣目的,我用一款著名的搜索工具搜索“深度学习应用于”词条,成百上千条返回的结果显示,“深度学习”正被应用于:“从卫星图像来获取商业洞察力”,“从自然环境中采集的数据集来区分疾病状态”,“理解电影评价”,“从生理传感器采集的数据预测情绪”,“自然语言”,以及我最感兴趣的“人类事物的纠结困惑”(我猜测我并不是唯一声称这两种现象存在联系的人)。深度学习似乎可以被应用于所有这些领域,不过,我们首先得回答一个问题,“深度学习”这个概念源自哪儿?什么是“深度学习”?首先,我认为这个概念和隐喻有一定联系。
今天,我们将苦心孤诣地探讨一番,看看隐喻如何作为强大的工具来引导我们的思维进入新视野——同时又引诱思维步入新的误区。

隐喻随处可见,在上一句中我就轻易地插入至少七处隐喻(斜体字标注)。概括来说,隐喻是用一个领域特定的词语和概念来介绍另一个完全不同的领域。以“埃尔维斯是摇滚乐之王”为例。严格地说,摇滚乐界并不是一个王国,但在这里借用“王”字,我们可以脑补一个王国:那里有各位不同地位的歌手,以及浩浩荡荡的簇拥人群(即他们的粉丝团)。相反地,我们也可以称其为“最权威的艺术家”或者造一个意思相近的新词。但是,前一种说法显得碎烦,后一种说法则会给我们留下太多新词。若下一次需要创造一个新词来替换迈克尔•杰克逊的“流行音乐之王”,我们又将面临一次窘境。显然,隐喻不是详细叙述时的修饰元素,而是使得语言更加精炼的修辞,在旧词的暗示之下感知、体验和理解新语境。
第一部分:“深度学习”之“学习”
根据大多数字典的定义,“学习”——韦氏字典定义为“通过学习、练习、传授、体验来掌握新知识和技能”——属于人类的一种行为。当“学习”这个词被用于动物、物体、甚至网络世界的硬件系统之类事物时,就已经是一种隐含表达,因为它适用于人类的概念,涉及到意识——除人类以外的事物不存在意识。你可能听说过所谓的形状记忆合金。这些金属制作的物品有一种有趣的特性:当你把它们从目前的形态弯曲成一种新的形态,然后对其加热,它们又会恢复到原来的形态。
这里也试图用隐喻的方式来描述这种行为(也是有助于概念化)。维基百科也用这种方法来描述 形状记忆合金 ,在用到隐喻的地方加上引号:训练意味着形状记忆可以通过特定的方式去“学习”行为。在正常情况下,形状记忆金属“记住”它在低温下的形变,但在加热时又恢复高温形状,立刻“忘记”之前在低温下的形变。我相信没人会对此信以为真,认为金属原子内部有个微型大脑,能“学习”和“记忆”一些事。那么用于“机器学习”的计算机程序又是怎样的呢?他们的“学习”也仅仅只是隐喻吗?或者说,真的有足够复杂的机器能够显示出像人类一样的学习能力?而且,为什么我们不像讨论记忆金属那样,立刻推翻后一种说法呢?
原因之一当然是计算机更加复杂,很多人对计算机不够了解。从最初谈论计算机就用到隐喻的手法,在1950年代计算机被媒体称为是“电子大脑”。接着是科幻小说,它们很少提及计算机枯燥的技术细节,而主要呈献给大家的是会“思考”的机器和机器人,这个概念在流 行文化中一直传播。在这里,它们遇到了根植于西方文化的“人造生命”概念,从由黏土捏成的假人,到中世纪的炼金术士的侏儒,直到玛丽•雪莱的弗兰肯斯坦。
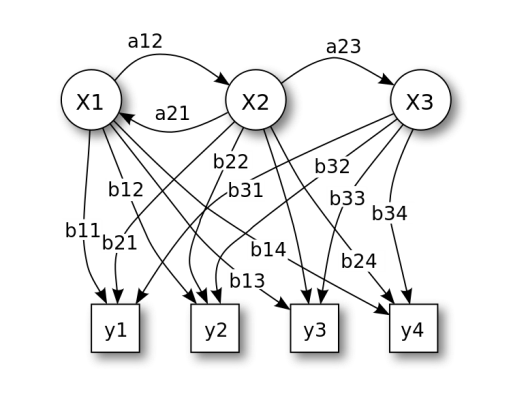
为了判断“机器学习”(ML)是真的学习还是“学习”,这里有个快速入门的方法。我们从隐马可夫数学模型(Hidden Markov Models, HMMs)开始说起,它曾一度是很多机器学习系统的中枢。请看上图,整个结构不算太复杂,由隐含状态(x),转换概率(a),输出概率(b)以及观察状态(y)组成。在大量训练数据集上“训练”得到模型,然后从中“学习”得到的概率值,训练集可以由单词或音素组成。我想我们都赞成这里的“学习”属于隐喻,因为这些模型和之前记忆金属里的原子并没有实质上的区别。然而,几年前HMM逐渐偏离主流的ML,取而代之的是另一种不同类型的模型,它最初于1990年代开始流行。这一取代没过多久就消失了,但最近又强势地返回舞台(我们稍后解释原因)。问题首先来自模型的名称:“神经网络”(Neural Network, NN)。从下图可以看到,模型由多层节点组成,这些节点能够被神经所“触发”,工作原理如同我们的大脑:左侧的箭头表示节点输入,就像神经元的树突接收输入信号(电刺激),然后触发一些计算步骤,计算结果从右侧输出(成为下一层的输入),犹如神经元的轴突。神经元内部的计算往往很简单,类似找出输入的最大值,或者输入之和。为了将此应用于ML任务——例如图像识别——需要把每个输入节点和黑白图像的一个像素对应,输出节点和想要识别的类的物体对应(树、牛等等)。接着,按照HMM的流程,设置输入输出值为样本图像和对应的正确分类结果(比如输入的图像是一头牛)。然后,使用“反向传播”的算法从右向左(模型在使用时是从左向右计算)调整权重值,因此若左侧有一个输入,在右侧就会计算得到正确的输出类别。
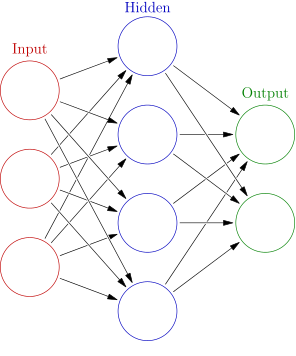
如你所见,整个模型并不比HMM复杂,至少不能立刻让我们信服神经网络模型能够思考和学习。假设,真实的模型有更多的节点(几千个),这和大脑中真正的神经元还是差别巨大:大脑拥有的神经元数量更庞大,以模拟化的方式工作,将电信号和化学信号甚至遗传效应结合起来,况且我们还不明白意识之类东西是如何产生的。在我看来,“神经网络”和HMMs对大脑的模拟程度并无二致。但是因为名称里存在“神经”(很不幸,它的替代词“感知器”也好不到哪里去)这个词,这类模型就如同我们在上面所见,携带了大量隐喻意义:“电子大脑”能用人造“神经元”来“学习”不是很容易让人产生联想吗?
第二部分:“深度学习”之“深度”
等一等,先不考虑“深度学习”的这个“深度”。从字面意思理解,“深度”是指一种空间关系。湖里和海里的水是深的。其它用法几乎都是隐喻,像表示颜色的时候会说“深红”和“深蓝”,表示颜色很重或者很暗,仅此而已。当然,用来形容“思考”也很常见:你深入探究这件事,经过深度思考,提出了深刻的见解。
在《银河系漫游指南》一书中,道格拉斯•亚当描述了计算机“深思”(这个计算机为了运算和检查答案深度思考了700多万年,最后显示出了答案42)。随后,一名后来成为IBM员工的学生借此命名了他的国际象棋计算机,并在1996年击败世界冠军卡斯帕罗夫而出名。再后来,IBM营销部门的一些人将其更名为“深蓝”——这里你看到了从“深海”到“深蓝”(像大海,也是IBM的logo)到深度“思考”的整个隐喻过程。事实上,国际象棋计算机与“深”相关并不多:其算法相当“浅显”且粗暴;“深蓝”的成功在于它使用大量硬件来计算可能的棋子移动方向,大量的芯片来巧妙设计评估落棋位置。尽管如此,“深”仍保留于此。(Deep Fritz如今仍是一款具有竞争力的商业国际象棋计算机)。DeepQA是另一个向“深”进军的产品:收集自维基百科的文本数据和本体打包,使机器在Jeopardy 能击败人类挑战者(以沃森的名义)。
机器学习研究员几年前就决定要扩展神经网络中间的“浅”隐藏层,变为多层结构,并且使节点更复杂,新的网络称为“深度神经网络”(DNNs),或是“深度置信网络”(DBNs)。普通非技术人员在听到“深度置信网络”这个隐喻的名词时,怎能不与“深度思考”以及人工智能相联系呢?
至此,我想我们已经剖析完毕,并且充分揭秘了我们所看到的模型是一种数学建模过程,和HMMs并无太大差别。因此,不管名字如何,这些系统所谓的“学习“只是一种隐喻。那么这意味着我们就可以低视他们了吗?完全不是!

首先,DNNs使我们Nuance核心的自动语音识别(ASR)引擎的准确率提升(错误率降低)—— ASR引擎是我们云计算背后的支持技术,也是 Dragon NaturallySpeaking 内部所用的技术,目前已经发展到第13代。在过去20年里,每一代的错误率都持续下降。到最后,在HMM框架下降低错误率已经变得越来越难,因为这个框架已经经历了20年的提升和优化,改进空间很小。所以,不仅仅是因为DNNs降低错误率的效果立竿见影,而且在DNNs这把大伞下蕴藏着巨大的未知改进空间,像在不同的拓扑结构,不同的层数和节点数,多节点的结构,网络的训练过程等等方面,它在未来几年里还有很大的潜能。在语音合成领域,DNNs提高了从待合成文本的语言特点到目标语言声学参数(如音韵)的映射能力。在语音识别技术中,他们有助于提高说话人身份鉴别的准确性。考虑到这一切,可以毫不夸张地说,DNNs是近几年我们众多产品中对创新贡献最大的独立个体。
当我说到DNNs并不复杂(很难从中看到意识和真正的智慧这个层面来说),我并不是说它们很容易被发现,或者说,容易使用它们。同样,结论完全相反。正如之前提到的,神经网络大约在1990年代就已经出现,但当时有两个问题限制它们的成功应用。一个是若想要在大数据集上训练它们,或者节点数和层数太多,训练消耗的时间就会很久——主要受限于当时的硬件条件。而且,尽管训练得到的模型在局部区域效果比其它相似模型要好,如果从全局来看,会有其它更好的配置。你训练得到的模型究竟是局部最优还是真正的全局最优取决于训练阶段早期的随机因素。当Geoffrey Hinton,Yoshua Bengio等先驱者解决这两个问题之后,DNNs开始取得突破。当然,更好的硬件帮助他们解决了第一个问题,但是利用并行计算和图形处理单元(GPU,最初为计算机图像开发的专用芯片)计算也是一个好主意,使其发展更快。在此之前,局部最小的问题是通过引入预训练的概念来解决,也就是把模型预先设置在接近(更快达到)全局最优点的一个状态,而不是完全从头开始训练。
下一步将是什么?
好事不仅仅是这些问题被解决了,神经网络现在被广泛应用。还在于开辟了更多的研究领域,这将为未来的发展提供更多的改进。在游戏产业的驱动下,GPU越来越强大,DNNs也搭上了顺风车。缩短训练时间不仅对实际应用有意义,也间接地帮助算法的改进:原来DNN消耗几周或几个月的时间在有意义的大型数据集上训练(它们直到几年前还是这个状态),实验代价非常高,进展也缓慢。现在你可以在几天甚至几小时内完成这些训练,测试新想法变得容易了。
即使有了这些进步,我和其它研究员一样,承认还有许多事情需要做。例如,使用GPU完成所有DNN训练步骤仍是一个挑战,这是由于网络结构的属性。因为一个“神经元”的输出可能依赖于输入数据和许多其它神经元,而且训练不是一个单纯的局部问题(因此容易并行化),大量的数据需要在计算节点之间转移,可能会抵消GPU的时间优势。我们怎么来解决呢?而且,当DNNs第一次挑起语音识别的大梁时,说话者无关模型在一个庞大的训练集上完成,训练集尽可能全面地包含了方言的各种变形和个体说话方式。这里的挑战是实际应用的系统使用另一个说话者相关的训练方法,使得基础模型适应特定的说话者。根据你用几秒钟的语音素材还是几个小时的语音来训练,不同的方法将被采用。所有这些模型都是以HMM模型为基础,现在要让它们都适应DNNs形式。
等等等等……
显然,DNNs领域还有源源不断的工作等着我们完成,与此同时,也伴随着大量的惊喜。我们不要被“深度学习”的隐喻冲昏头脑。
原文地址: What is deep machine learning (译者/赵屹华 校检/刘帝伟、朱正贵、李子健 责编/周建丁)
【分享预告】9月29日20:30-21:30 ,CSDN人工智能用户群安排技术专家深度分享“ 世纪佳缘推荐和机器学习算法实践 ”。
- 讲师简介 :杨鹏,世纪佳缘算法组,从事推荐和机器学习算法相关工作。
- 分享内容 :佳缘网站在用的推荐和排序的算法,用到的工具,架构,一些成功和失败的尝试。
- 分享通道 :1.CSDN 人工智能技术交流QQ群:465538150。2.CSDN 人工智能用户微信群,请加微信号“jianding_zhou”或扫下方二维码,由工作人员邀请入群。 加群 请注明“机构名-技术方向-姓名/昵称”,并按此格式修改群名片 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

