大搜车前端开发模式:被动编译和主动编译
最近,梳理了一下公司的前端开发体系,准备给已经工作一年多的原有体系引入一些新的开发模式,其实也不算新了,只是对于我们一直采用的模式来说,是两个完全不同的方向,以前,我崇尚简单,一直按照简单易用的理念构建了公司现有的前端开发体系,现在随着人数的增多和业务的复杂度提升,感觉是时候引入一些差异化的开发体系了。
说来说去有点绕的慌,上面一段中说的 传统的开发模式,在团队内部我们叫做 被动编译,而新的开发方式,在团队内部叫做 主动编译。
被动编译
可能很多人对于被动编译都不是很熟悉,因为这种开发方式现在并不流行,不过貌似也从来没流行过。
所谓 被动编译。核心理念是:所有源码都是在被访问的时候才会去编译。
这里的“源码”,指的是 jade,less,js,coffee甚至jsx之类的预处理语言代码,在我们公司前端项目中,约定了使用这些预处理语言来组织代码,他们普遍的特点是 简单而强大,而对于一个团队来说,大家趋向于一种语言和模式是非常重要的,所以这里我们不讨论这些预处理的语法优劣,只介绍我们是如何运用它们的。
在大搜车,一个前端开发的开发和发布流程是这样的:写jade,写less,写js —> 浏览器访问jade对应的路径 —> 浏览器显示编译后的html —> html中的css的内容其实是直接来自less的编译 —> js之类的也经过了一个服务的处理 —> 但是看源码,里面只有jade,less,jsx等。  事实上,被动编译的关键是 一个小型服务器,我们在内部称之为 ads,它事实上是一个带有动态功能的静态服务器。前端写的jade,less,js都会托管在这个服务器的静态目录里,然后浏览器的请求,每次都会经过这个ads服务器,服务器内部的逻辑会判断当前请求的url应该对应到本地何种资源的哪个源文件上去,然后读取这个源文件,在进程中直接调用编译器,将编译结果返回给浏览器,中间不生成中间文件。
事实上,被动编译的关键是 一个小型服务器,我们在内部称之为 ads,它事实上是一个带有动态功能的静态服务器。前端写的jade,less,js都会托管在这个服务器的静态目录里,然后浏览器的请求,每次都会经过这个ads服务器,服务器内部的逻辑会判断当前请求的url应该对应到本地何种资源的哪个源文件上去,然后读取这个源文件,在进程中直接调用编译器,将编译结果返回给浏览器,中间不生成中间文件。
为什么我们一直坚持 被动编译 这种开发模式呢?
- 统一整个团队的开发环境,甚至是预处理器的选型,甚至是代码的风格。
看上去有点剥夺自由发挥的嫌疑,但是对于程序员的问题来说,总是难以满足各方的,其实统一带来的一大问题就是不够灵活,但是灵活带来的问题也是不够统一,然后不够统一造成的问题会引起一些其他的问题,例如人和人之间的沟通成本,跨项目开发的痛苦,前人写的代码难以维护,不同的项目配置不同的环境耗费掉的时间成本。 这个问题,我们都是从团队角度出发,对个人的开发自有做了一部分牺牲,通过ads,我们把预处理的语言规范化了,把项目目录规范化了,甚至把预处理的使用方式也规范化了(不嫩使用高级特性)。
- 开发人员不关心环境,不需要配置。
在经历过五六年的开发经验之后,很多开发中碰到的问题都给了我深刻影响,深知有些东西看起来很美好,但是放到现实中就是另外一回事,在开发中这类事情很多,例如模块化,解耦,重构,服务化这些事情,在某些方面,是很好的改变,但是做到某种程度,效果就开始适得其反,很多问题就开始放大化了,而这些问题往往很多开发都选择性忽视或者压根没有考虑过。具体就不展开了。
其实ads的一大好处(也有可能是坏处)就是 无需配置。一个开发者入职后,需要做的事情,下载ads,启动,然后clone我们的前端代码库,找到文件夹,开始写代码,ok,本地浏览器里可以实时访问了。不需要配置路径,不需要配置需要打包编译的文件,不需要执行命令,不需要监听文件变化。
然后,继续,开发完成后,要发布测试了,怎么操作呢,很简单,把文件都提交到git,然后等一会会,测试环境自动生效了。为什么能做到这个效果呢?最重要的一点,ads的项目文件不需要编译,不管在本地还是测试还是线上,在你的电脑上在我的电脑上,他都是源文件的状态躺在你的硬盘里,只有浏览器访问的时候才会去编译文件。所以,发布测试其实是个很简单的操作,把文件从你本地copy到测试环境的静态目录,而发布线上其实是一样的,把文件从测试copy到线上目录。仿佛他们是静态文件,而事实上他们是动态的预处理代码。 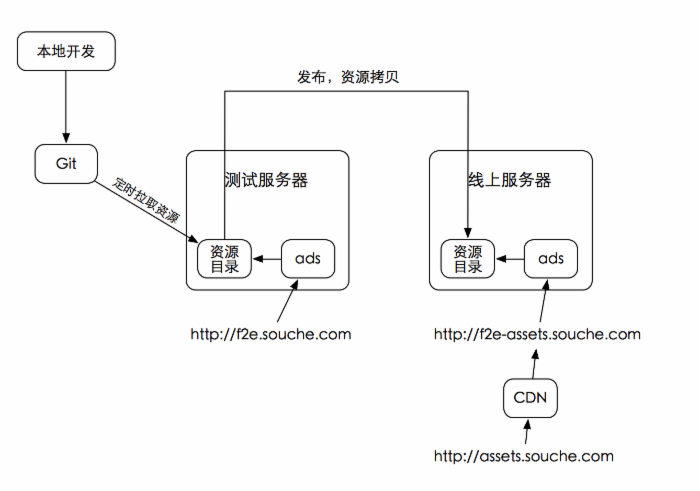
- 实现灵活的动态应用。
举几个例子
一个是combo,很常见的需求,我们的代码可以随意combo,事实上支持任何文件无限combo,当combo的是css的时候,其实是把所有less源码合并编译的结果,而对于js,则是合并然后压缩。
二是可以动态生成css,这个在多主题的项目中很有用。因为我们的css都是less写成的,当在less中定义一个变量的时候,可以在url里传入这个变量的初始值,然后,整个主题就会变成另一个颜色。同理,可以传入很多东西,就可以实现很多灵活性的功能。

大家可能会问一些问题,其实我们自己也提出一些问题:
- 性能不会有问题么?
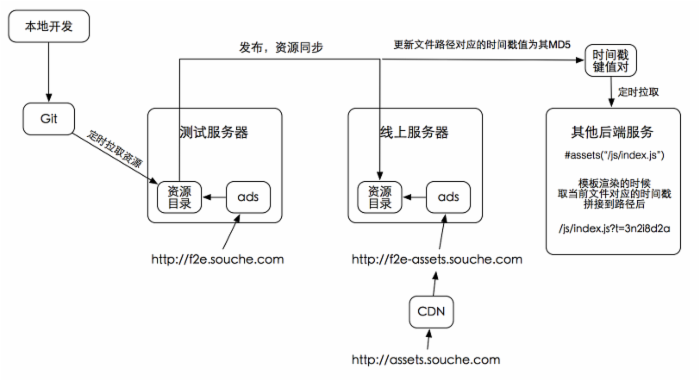
这个问题其实很简单,我们所有线上静态资源都是经过cdn的,所以这个问题就不是问题了,一个文件只有第一次被访问的时候才会被动态编译,之后结果就缓存在cdn服务商那里了,下一次请求就不会到我们的ads线上服务器来。所以我们的线上服务其实承载的访问还是很少的,也不会有性能问题。针对cdn更新还需要有一套时间戳刷新的功能。
- 如何处理时间戳问题?
在我们的在线服务器上,维护了一个时间戳文件,每个文件在经过发布系统的时候,都会去这个文件里更新一下自己的时间戳为当前文件的hash值。然后在ads内存中我们会定时更新这个时间戳文件到内存,每次渲染jade的时候,都会带入一个方法,这个方法套起来的资源文件在渲染jade的时候会自动带上他对应的时间戳,这样jade里的资源都可以自动更新时间戳了,其实开发人员无需关心这个事情,一切都是自动的。 对于其他引用静态资源的服务,需要在他们服务中实现一个类似的维护的时间戳键值对,然后在渲染模板的时候自动渲染出时间戳。不过这种服务已经很少了,我们现在大多数系统都是前后端分离的,前端页面都是放在ads托管的项目中,由jade编写。
其实被动编译以及这套开发环境支撑大搜车的环境已经有1年之久,也算经得起考验,目前项目中的代码还是很清晰的,也没有出过比较大的问题,大家用的时间长了,基本忘了编译那一套了,甚至把jade,less当成了自然而然的终端语言使用,已经到了不用不舒服斯基的状态。
不过随着前端技术的发展,项目中必然要引入更高级的编译特性了,这时候被动编译开始显得有些力不从心了。
例如我司大规模使用的AngularJS,React的打包编译,使用ES6的项目,需要引入webpack,browserify之类工具的项目。用被动编译其实有很多限制,对于这些模式来说已经hold不住了,于是我们想,是时候引入主动编译的模式了。
主动编译
所谓主动编译,其实就是在本地打包好,然后把结果文件上传到服务器的开发方式。
主动编译一般需要引入流程控制工具,例如grunt,gulp之类的,目前用gulp的比较多,而我们最终研究过之后也选用了gulp,一个是gulp据说性能和配置都比较简单,二是之前公司有项目用grunt,后面的配置变得越来越乱,吃个教训。
其实之前准备采用百度的fis的,因为一直吹的比较厉害嘛,我一直以为fis是一个所谓“工程化”水平比较高的工具,于是跟团队说去研究下,然后仔细看了下他本身自带的一些功能,发现都很基础啊,其实ads中都有这些功能,而且可能更优。不过fis可以通过插件实现很多扩展功能,不过对于一些常用的打包工具都搜不到封装的插件,还且插件质量堪忧,实在是不宜采用作为生产工具。最后只能放弃了。
在我看来,fis还是比较基础的,适合那些没有自己的现成的开发流程管理工具的团队,对于我们团队来说,功能跟ads有所重叠,而且又不是一个路数。其实我们想着引入主动编译,不是想颠覆ads,而是主要用来处理比较重的前端项目。把这些比较重的前端项目从之前的静态项目中抽离出来,给他们赋予独立的项目构建工具。而普通的页面,里面的静态资源,仍然使用原有的开发方式。
最后,我们选择了gulp,至于gulp之类的工具,这里其实也不想详细展开,文章很多。
不过在选用主动编译的模式的时候,我们仍然很注重一些风险,因为在我看来,可以引入很多插件,使开发变得更灵活,但是更不可控了。
所以我们初步做了一些约定:
- 有一个统一的示例项目,所有项目由此衍生。
- 只允许使用常用插件,禁止使用一些奇怪的(例如把js先合并压缩然后打进html里的插件)
- 示例项目中,针对不同场景,封装成一个个小的子配置,如果要使用某功能,直接引入,最好不要自己写配置,也不需要自己写配置。
- 目录规范,配置规范,都文档化,按照规范来。
其实这些东西都没有太多技术含量的,没做觉得玄乎,做了觉得也就那些东西。最重要的还是能够解决实际问题,然后评估好可能带来的风险。每个团队可能都会有些差异,大家看看就好。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

