Android IOS WebRTC 音视频开发总结(五一)-- 降噪基本原理
文章主要介绍噪声消除,文章来自博客园RTC.Blacker,支持原创,转载必须说明出处,欢迎关注微信公众号blacker,更多详见www.rtc.help
--------------------------------------------
RTC中声音处理是个很麻烦的事,难点很多,回声,噪声,啸声,增益,等等,其实从中国潜艇噪声那么大就可看出这东西确实不好处理。
这些年我也被这些问题搞得烦死了,特别是android上面的,当然折腾过程中也发现了很多被大家误解的现象:
1、只有qq和微信语音效果才处理得比较好?
不是,有些公司语音效果也很牛b,只不过他们的产品的终端用户不是个人,所以我们很少听说,但这不影响他们在业界的口碑,为了避嫌,名字我就不说了,大家以后有用到的时候自然会知道。
2、做图像识别和语音识别的公司在RTC方面就一定很牛?
不一定,昨天科技园一家做通讯的公司给我看了他们的一个合作客户——硅谷很牛的一家做机器人公司(语音识别和视频交互,不是那种简单的摄像头转一下,扫扫地的),人家对RTC基本上就是一片空白,这也正说明了术业有专攻。
3、视频通讯的都是用WebRTC搞的?
有些公司是完全用WebRTC搞的(用libjingle,ICE,webrtc),而更多公司只是用他里面的一些模块,当然也有公司基本上都是自己搞的(包括编解码,传输,抖动缓冲,回声消除,噪声消除等),WebRTC对他们来说主要是做参考。
4、找个大牛用webrtc就可以搞定RTC所有问题?
用之前在微信里面做底层编解码的朋友的话解答:“我们做底层算法的不熟悉上层应用,熟悉上层应用的不熟悉底层算法”,我当时补充了一句:“两者都能搞定的不熟悉市场,熟悉市场又懂技术的当老板去了”,世界就是这样,没有人能搞定所有问题,所以 合作与互补很重要,这就是我为什么一直找志同道合的人的原因 。
更多交流请关注我的微信公众号blacker,言归正传, 下面 这篇文章是刘老师( icoolmedia )写的,kelly进行编辑和整理
一、 谱减法语音降噪基本原理
谱减算法为最早的语音降噪算法之一,它的提出,基于一个简单的原理:
假设语音中的噪声只有加性噪声,只要将带噪语音谱减去噪声谱,就可以得到纯净语音幅度。这么做的前提是噪声信号是平稳的或者缓慢变化的。
得到纯净信号的幅度谱后,可以结合带噪语音相位(近似带替纯净语音相位),从而得到近似的纯净语音,语音信号的相位对语音可懂度不敏感。
按上述所示,如果我们设y(n)为受噪声污染的信号,则y(n)由纯净语音信号x(n)和加性噪声d(n)组成,即:y(n)=X(n)+d(n)。
其傅里叶变换后表示为:Y(ω)=X(ω)+D(ω),或写为:
X(ω) = Y(ω) – D(ω),如果用功率谱表示可以写为:

这里  被称为交叉项,我们假定d(n)具有0均值,并且与x(n)不相关,则交叉项为0,
被称为交叉项,我们假定d(n)具有0均值,并且与x(n)不相关,则交叉项为0,
上述公式简化为: 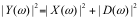 或写为:
或写为: 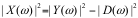
二、音乐噪声和过减因子、谱下限的关系
如果带噪语音的幅度谱(功率谱也同此理)与估计出来的噪声谱相减出现负值时,说明对噪声出现了过估计问题,对这种现象最简单的处理就是将负值设为0,以保证非负的幅度谱。但是对负值的这种处理,会导致信号帧频谱的随机位置上出现小的,独立的峰值。
转换到频域后,这些峰值听起来就像帧与帧之间频率随机变化的多频音,这种情况在清音段尤其明显,这种由于半波整流引起的“噪声”被称为“音乐噪声”。从根本上,通常导致音乐噪声的原因主要有:
1,对谱减算法中的负数部分进行了非线性处理
2,对噪声谱的估计不准
3,抑制函数(增益函数)具有较大的可变性
减小音乐噪声的方法是对噪声谱使用过减技术,同时对谱减后的负值设置一个下限,而不是将它们设为0,其技术形式如下:

其中alpha(大于等于1)为过减因子,它主要影响语音谱的失真程度。Beta(大于0小于1)是谱下限参数,可以控制残留噪声的多少以及音乐噪声的大小。
使用过减因子与谱下限的动机在于:当从带噪语音谱中减去噪声谱估计的时候,频谱中会残留一些隆起的部分或谱峰,有些谱峰是宽带的,有些谱峰很窄,看起来像是频谱上的一个脉冲。通过对噪声谱的过减处理,我们可以减小宽带谱峰的幅度,有时还可以将其完全消除。但是仅仅这样还不够,因为谱峰周围可能还存在较深的谱谷。因此需要使用谱下限来“填充”这些谱谷。
在高信噪比中,alpha应取小值;对低信噪比中,alpha建议取大值。Berouti等人做了大量实验来确定alpha与beta的最优值,在这里我们直接使用就可以了。具体请参考论文:Enhancement of speech corrupted by a acoustic noise。
下面给出谱减算法的Matlab验证代码,调用方法为specsub(‘filename.wav’,’outfile.wav’);
1 function specsub(filename,outfile) 2 3 if nargin < 2 4 5 fprintf('Usage: specsub noisyfile.wav outFile.wav /n/n'); 6 7 return; 8 9 end 10 11 12 [x,fs,nbits] = wavread(filename); 13 14 len = floor(20*fs/1000); % Frame size in samples 15 16 if rem(len,2) == 1, len=len+1; end; 17 18 PERC = 50; % window overlap in percent of frame size 19 20 len1 = floor(len*PERC/100); 21 22 len2 = len-len1; 23 24 25 Thres = 3; % VAD threshold in dB SNRseg 26 27 Expnt = 2.0; % power exponent 28 29 beta = 0.002; 30 31 G = 0.9; 32 33 34 win = hamming(len); 35 36 winGain = len2/sum(win); % normalization gain for overlap+add with 50% overlap 37 38 39 % Noise magnitude calculations - assuming that the first 5 frames is noise/silence 40 41 nFFT = 2*2^nextpow2(len); 42 43 noise_mean = zeros(nFFT,1); 44 45 j=1; 46 47 for k = 1:5 48 49 noise_mean = noise_mean+abs(fft(win.*x(j:j+len-1),nFFT)); 50 51 j = j+len; 52 53 end 54 55 noise_mu = noise_mean/5; 56 57 58 %--- allocate memory and initialize various variables 59 60 k = 1; 61 62 img = sqrt(-1); 63 64 x_old = zeros(len1,1); 65 66 Nframes = floor(length(x)/len2)-1; 67 68 xfinal = zeros(Nframes*len2,1); 69 70 71 72 %========================= Start Processing =============================== 73 74 for n = 1:Nframes 75 76 insign = win.*x(k:k+len-1); % Windowing 77 78 spec = fft(insign,nFFT); % compute fourier transform of a frame 79 80 sig = abs(spec); % compute the magnitude 81 82 %save the noisy phase information 83 84 theta = angle(spec); 85 86 SNRseg = 10*log10(norm(sig,2)^2/norm(noise_mu,2)^2); 87 88 if Expnt == 1.0 % 幅度谱 89 90 alpha = berouti1(SNRseg); 91 92 else 93 94 alpha = berouti(SNRseg); % 功率谱 95 96 end 97 98 %&&&&&&&&& 99 100 sub_speech = sig.^Expnt - alpha*noise_mu.^Expnt; 101 102 diffw = sub_speech - beta*noise_mu.^Expnt; % 当纯净信号小于噪声信号的功率时 103 104 % beta negative components 105 106 z = find(diffw <0); 107 108 if~isempty(z) 109 110 sub_speech(z) = beta*noise_mu(z).^Expnt; % 用估计出来的噪声信号表示下限值 111 112 end 113 114 % --- implement a simple VAD detector -------------- 115 116 if (SNRseg < Thres) % Update noise spectrum 117 118 noise_temp = G*noise_mu.^Expnt+(1-G)*sig.^Expnt; % 平滑处理噪声功率谱 119 120 noise_mu = noise_temp.^(1/Expnt); % 新的噪声幅度谱 121 122 end 123 124 % flipud函数实现矩阵的上下翻转,是以矩阵的“水平中线”为对称轴 125 126 %交换上下对称元素 127 128 sub_speech(nFFT/2+2:nFFT) = flipud(sub_speech(2:nFFT/2)); 129 130 x_phase = (sub_speech.^(1/Expnt)).*(cos(theta)+img*(sin(theta))); 131 132 % take the IFFT 133 134 xi = real(ifft(x_phase)); 135 136 % --- Overlap and add --------------- 137 138 xfinal(k:k+len2-1)=x_old+xi(1:len1); 139 140 x_old = xi(1+len1:len); 141 142 k = k+len2; 143 144 end 145 146 wavwrite(winGain*xfinal,fs,16,outfile); 147 148 function a = berouti1(SNR) 149 150 if SNR >= -5.0 & SNR <= 20 151 152 a = 3-SNR*2/20; 153 154 else 155 156 if SNR < -5.0 157 158 a = 4; 159 160 end 161 162 if SNR > 20 163 164 a = 1; 165 166 end 167 168 end 169 170 function a = berouti(SNR) 171 172 if SNR >= -5.0 & SNR <= 20 173 174 a = 4-SNR*3/20; 175 176 else 177 178 if SNR < -5.0 179 180 a = 5; 181 182 end 183 184 if SNR > 20 185 186 a = 1; 187 188 end 189 190 end 191 192 三、几种改进的谱减算法
1,非线性谱减
Berouti等人提出的谱减算法,假设了噪声对所有的频谱分量都有同等的影响,继而只用了一个过减因子来减去对噪声的过估计。现实世界中的噪声并非如此,这意味着可以用一个频率相关的减法因子来处理不同类型的噪声。
2, 多带谱减法
在多带算法中,将语音频谱划分为N个互不重叠的子带,谱减法在每个子带独立运行。将语音信号分为多个子带信号的过程可以通过在时域使用带通滤波器来进行,或者在频域使用适当的窗。通常会采用后一种办法,因为实现起来有更小的运算量。
多带谱减与非线性谱减的主要区别在于对过减因子的估计。多带算法针对频带估计减法因子,而非线性谱减算法针对每一个频点,导致频点上的信噪比可能有很大变化。这种剧烈变化是谱减法中所遇到的语音失真(音乐噪声)的原因之一。相反,子带信噪比变化则不会特别剧烈。
3, MMSE谱减算法
上面的方法中,谱减参数alpha和beta通过实验确定,无论如何都不会是最优的选择。MMSE谱减法能够在均方意义下最优地选择谱减参数。具体请参考论文:A parametic formulation of the generalized spectral subtractor method
4,扩展谱减法
基于自适应维纳滤波与谱减原理的结合。维纳滤波用于估计噪声谱,然后从带噪语音信号中减去该噪声谱。具体请参考以下两篇论文:
Extended Spectral Substraction:Description and Preliminary Results.
Extended Spectral Substraction
5,自适应增益平均的谱减
谱减法中导致音乐噪声的两个因素在于谱估计的大范围变化以及增益函数的不同。对于第一个问题,Gustafsson等人建议将分析帧划分为更换小的子帧以得到更低分辨率的频谱。子帧频谱通过连续平均以减小频谱的波动。对于第二个问题Gustafsson等人提出使用自适应指数平均,在时间上对增益函数做平滑。此外,为了避免因使用零相位增益函数导致的非因果滤波问题,Gustafsson等人建议在增益函数中引入线性相位。具体请参考论文:Spectral subtraction using reduced delay convolution and adaptive averaging
6,选择性谱减法
前面提到的方法对所有语音都做同样处理。并不区分是浊音段还是清音段。区分浊音与清音的谱减法有:
6.1, 双频带谱减法。通过将带噪语音能量与某一阈值进行比较,把语音帧分为浊音和清音。对于浊音帧,用算法确定一个截止频率,在该截止频率之上,语音被认为是随机信号。浊音段则通过滤波分为两个频带,一个频带位于截止频率之下(低通滤波后的语音),另外一个频带高于截止频率(高通滤波后的语音)。然后对低通和高通后的语音信号使用不同的算法进行处理。对低通语音部分在短时傅立叶变换的基础上使用过减算法,对于高通部分以及清音段,使用Thomson的多窗谱估计器取代FFT估计器。主要目的在于减小高频部分的频谱值的波动。具体请参考论文:Adaptive two-band spectral subtraction with multi-window spectral estimation
6.2,双激励语音模型法,该算法把语音分为两个独立的组成部分--浊音分量和清音分量。也就是说,语音由这两个分量的和来表示(注意不同于将语音分为浊音段和清音段)。浊音分量的分析是基于对基音频率和谐波幅度的提取。然后从带噪语音谱中减去浊音谱就得到了清音谱。然后使用一个双通道系统,基中一个包括改进的维纳滤波器,被用于增强清音谱。最终增强的语音由增强后的浊音分量和清音分量求和得到。具体请参考论文:Speech enhancement using the dual excitation speech model
6.3,还有一种基于浊音、清音的谱减算法,在该算法中语音帧首先根据能量和过零率被划分为浊音和清音。然后将带噪语音谱与锐化函数进行卷积,清音的频谱就会被锐化(用锐化函数进行镨锐化的目的在于增加谱对比度,即在抑制谱谷的同时使谱峰更加突出)。具体请参考论文:Spectral subtraction based on phonetic dependency and masking effects
7, 基于感知特性的谱减
前面提到的方法,谱减参数要么是通过实验计算短时信噪比得到,要么是通过最优均方误差得到,均没有考虑听觉系统的特性,该算法的主要目的是使残余噪声在听觉上难以被察觉。利用了人类听觉系统改进系统的可懂度(即人耳的掩蔽效应)
喜欢系列文章请关注微信公众号blacker,或扫描下方二维码:

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

