中国工程院院士高文:多媒体大数据分析与搜索
【CSDN现场报道】2015年12月10-12日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,中国科学院计算技术研究所、北京中科天玑科技有限公司与CSDN共同协办,以“数据安全、深度分析、行业应用”为主题的2015中国大数据技术大会(Big Data Technology Conference 2015,BDTC 2015)在北京新云南皇冠假日酒店盛大开幕。
2015中国大数据技术大会首日全体会议下午场在蚂蚁金融服务集团安全智能部总监、CCF大数据专家委员会委员陈继东的主持下正式开始。 中国工程院院士高文带来了名为“多媒体大数据分析与搜索”的主题演讲,深度剖析媒体大数据的存不下、看不清、找不到的三大技术挑战问题,以及解决方案,分别为:超高效视频编码解决压缩问题,在视频编码工具中引入场景模型,获取更好的编码效率;以面向对象检测、跟踪与识别解决模式识别问题,支持ROI、GPS和多摄像机关联;以大规模视觉搜索解决跨摄像头搜索问题,制订新视觉描述子标准来支持有效搜索。高文表示,当前,智能城市媒体大数据方面的研究才刚起步,个人大数据方面的研究将更具挑战性,我们需要在数据科学的各个方面进一步努力,协同创新。

中国工程院院士 高文
以下为演讲实录
高文:
现代社会中,大数据来源丰富,更直接让交通、医疗卫生、教育、安全等发生变化,而在智慧城体系中,监控视频是体量最大的大数据。基于此,今天,我主要分享媒体大数据的三个挑战问题。第一,存不下,24小时产生的数据量积累得很大。第二,看不清,用眼睛看,横看竖看,还是看不清楚,可能有时候都要猜来猜去,还需要很有经验的人才能看出来大概。为什么?存的时候做了压缩,压缩时不知将来作何用,为了节省存储量,压得太狠了,再把它解开时基本看不清。第三,找不到。现在摄像头到处都是,摄像头拍到了,但是不是想要找的?不知道,即使看清楚了,一跨摄像头也就找不到了。所以摄像机网络跨摄像头搜索问题也是个难题。
一、存不下:视频压缩率增长<<数据量增长,超高效视频编码解决压缩问题。
第一个挑战,我们想办法找到最高效的编码来应对这个挑战。视频流是图像序列,在每个单独的图像里是有冗余的,通常这个冗余我们把它叫作“空间冗余”。相邻的像素或相邻的图像块会有一些相关性,这些相关性即是“冗余”,这种冗余可以通过滤波器的算法进行估算。如果参数对了,就可以用它去做预测,继而找到一些更简洁的表达方式,使得你表达信息不需要那么多比特就可以压缩了,这就是空间冗余。
其次是时间冗余,即一个图像序列,第一帧和第二帧有很多是连续的,背景几乎是一样的,它有很多东西是重复的,这个重复的就是冗余,我们管它叫“时间冗余”。第三种是感知冗余,这个是为了大众化一点才这么讲,行业里的人把它叫“编码冗余”,比如26个字母要表达,怎么表达?给出8个bit或7bit,每个字母给的bit是一样的,学计算机的人都知道这种分法是不科学的,应该怎么分?按照它的信息熵来分,图像也是一样,每个像素表达的亮度、颜色在每类里分布不均匀,最好把出现概率高的那些单体给它比较短的码,把出现概率低的给长码,统计上面就会比较合理,对此我们称之为“熵编码”。如果这三种用好了,就有办法把图像或视频完美地压缩下去。
现在图像压缩实际达到的现状和理论上到底有多大差别?很大,但同时空间也很大。到现在为止,不管是多好的编码技术,离理论上限大概还有百分之八九十的空间可以改进,因为我们数学上很容易证明理论上限,若干个上限中我可以取最低的上限,就很容易计算出有多大空间可以继续改进。这就是为什么视频编码领域这些年还在不停地发展,并且,每十年编码效率就会提高1倍。
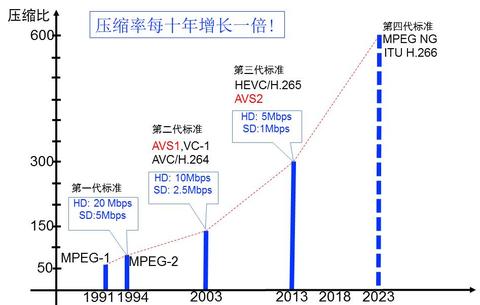
视频压缩效率“倍增定律”
在这样每十年翻一番的情况下,到底什么东西改变了?其实是算法更复杂了,很多靠计算的复杂度换取了编码的效率。当然,这里有很多新的算法,以前因为硬件比较贵,不能让编码的器件成本太高,所以有些算法还行,只要算法太复杂就基本不用。现在不在乎这个,因为集成电路发展以后,复杂点就复杂点吧,只要你想得出来,时限上不会在给定时间内完不成,算法愈来愈多,编码放进去后视频效果会越来越好。针对监控视频我们会有更好的方法,使得它的效率可以做得更高。
刚才说的是从编码的角度,我们有去空间冗余、去时间冗余和去编码冗余三种技术,来把视频流里的冗余去掉,这三种技术包含了许多算法,有变换、滤波、运动补偿、熵编码等等。分类就是像刚才说的,去空间冗余最主要的工具是变化,把时域变到频域上再进行处理,对于空间的冗余主要是采用预测编码的方式去除,对于感知主要是通过熵编码去除。
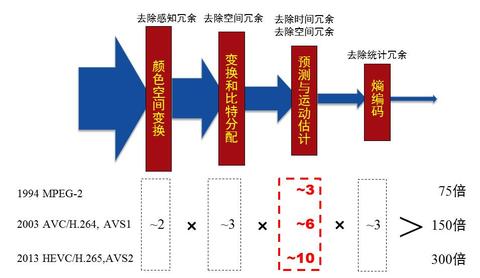
压缩性能来源估计(倍数)
再细分一下,这三代到底是哪个工具做了多大的贡献?上图左边两列,色彩空间和这几代大概贡献度是6倍,第三类是预测与运动估计。这一块每一代是不一样的,比如第一代贡献3左右,第二代贡献6左右,第三代贡献10左右。熵编码这三代有点变化,但是没有构成成倍的变化,基本大约是3倍左右。所以乘起来,针对高清视频,第一代是75倍,二代是150倍,三代是300倍,我们正在做第四代,希望做600倍。
刚才我们说第一代、第二代、第三代,它的应用场景是什么?应用场景是电视、电影,因为我们什么东西都是需求拉动的,它最大的需求是什么?过去30年一直是广播电视和电影,广播电视和电影有个假定,即场景要经常换。为什么?场景不换,人的注意力就会失散掉,很有可能就打瞌睡睡着了。所以,它有一个假定是最长30秒就必须换掉场景,这样人脑能被抓住,随着情节的演化,人能够深入进去。这个假定已经被视频编码界广泛接受,也就是说背景是要经常换的。并且,经过反复实验,认为0.5-2秒为最合适的间隔。
但是如果应用于监控,故事就不一样了,这是为什么?因为一个场景长时间不变,这时候假定是错误的。现在监控里面用的算法和广播电视一模一样,只不过有的厂商比较聪明一点,说咱们能不能别2秒钟就切换,能不能再长一点,比如弄1分钟、2分钟,有这样的案例,效果也确实提高了一些。但是又有一个问题,尽管场景是不换的,但镜头拉得近的时候,场景里面公交车站分之一画面,你也不知道它什么时候进来,刚好你切换时公交车在里面,切换完公交车走了,这个场景和你后面参考的场景变化非常大,这时候就来问题了,就是多少秒或多少分钟的擦分全都不对了,这个突然马力就上来了,系统就崩溃掉。
现在做模式识别时,压得狠了以后把目标里面很重要的特征给滤掉了。如果我知道哪个是前景,这个我压得轻一点,后面的识别就会好了。对于背景,因为反正它是背景,没有人在乎好一点差一点,背景可以压得稍微狠一点,这样可以把真正有用信息保留得多一点。怎么样做背景建模呢?我的学生们做了一些工作,可以通过算法把它们组合到一起。预测场景怎么建立起来,什么时间更新,多长时间需要更新,更新的点是什么,是固定更新,还是发现过了哪个域值就要更新,有两个博士论文都是做这样的工作。
把所有这些东西集成在一起,我们做的音视频标准里面,专门有个分值做监控视频,这个正在走国家标准化的程序。它经过严格的测试,在视频流里面我们加上这个模式,然后在里面做点优化,比广电里面用性能高一倍,提前完成了在2023年做到的任务,也就是说从监控视频角度我们已经做到了第四代,它已经性能提高了一倍,测试的结果是基本可以翻一番了。我们把同样的技术架到,国外最好的编码叫HEVC,我们把同样的场景技术加到HEVC上,其他什么都不动,加上背景建模技术进去,它的性能可以提高40%,提到50%就是下一代了,我们没做优化,直接加上去就做到这样的效果,这是非常好的技术,这个技术目前还没有开始用,我们也希望找到一些好的用户,特别是建大的城市的数据中心时最好采用这种技术,存储就会节省很多。作为AVS2这个标准本身,它现在已经在一些地方开始使用。
编码有很多有意思的需求,不是所有的都能做,像这种需求我们认为在监控里能做得动的就做了,现在正在做VR,这是第一个挑战。
二、看不清:面向对象检测、跟踪与识别解决模式识别问题
第二个挑战,对象检测、跟踪识别挑战。不仅仅是模式识别率再高、人脸识别再准再高,识别的准和不准有算法的好坏,还有一点是在编码那端能不能对我提供支持。以往这两个系统像轨道一样完全平行,我们希望编码和识别能合作,把中间那堵墙翻过去或者拆掉。怎么拆掉?编码时候要考虑怎么办。现在我们提出个支持是ROI,就是编码时候识别出来哪个区域可能是识别要用的区域,把这个区域定义成感兴趣区域,对于感兴趣区域要描绘出来,现在语法里对感兴趣区域有专门的描述,除了这个区域以外还包括其他的,比如你可以放GPS信息、摄像机参数信息。有了这个以后,我在后面编码时候,会针对编码参数进行调整,ROI区域压得轻一点,这样关键的信息丢失的会少一点。
有了这样的知识,可以用它架构友好的智能监控识别体系。现在即使有个算法很好,比如266出来了,它编码的效率和AVS2是一样的,我说那也不行,为什么?因为你压完以后还有解,解的时候才知道哪个地方是识别的。现在压的时候就知道哪个东西是有用,哪个东西没有用,有用的可以压得轻一点,这样构建分析架构,底层是完全的视频流,视频流上面可以构架一个区域描述,不是有ROI么,这个“R”就是region,根据区域描述,然后若干的区域构成个对象,它们的关联就可以构成事件,只要处理能力足够强,我就把这个东西表述出来了,这是对识别非常有用的帮助。
三、找不到:以大规模视觉搜索解决跨摄像头搜索问题
第三个挑战,跨摄像头怎么办?我们可以对跨摄像头的数据进行矫正,然后进行一些后续的工作。这方面已经有很多工作在做了,比如我们试验室学生搭了一个系统,你在北大校园的一个地方走,其他几个框是别的几个摄像头,从一个摄像头跨到另外一个摄像头时候,现在有一个专门技术是再认证,一个人在一个摄像头里出现过,当你就到第二个摄像头,那么我能够再识别出来你。因为有时候可能不是正脸,靠人脸识别已经不管用了,就要靠颜色、身体、步态、外形等等综合识别就是你。

多摄像头协同的对象检测与追踪
怎么做好这个系统?除了刚才的技术以外,还有一个重要的技术是能做到大规模的搜索。大规模的搜索这一块我们组有个很好的工作叫CDVS,它可以用很少的特征去搜索你要的东西,就是说我用手机拍一张照片或者拍一个景色,拍完以后传送到服务器,搜索后会告诉你拍的是哪里。这个过程它需要你的特征选得非常好、非常准,然后有代表性,这样才能使得搜索比较准。
具体想法是这样的,可以用一组特征,这组特征我们把它命名叫“CDVS”,CD是一个紧缩的描述词,就是面向视觉搜索的紧缩描述词,这也是在国际标准化框架下面做的。前一段时间有个多媒体描述标准是MEPG7,最近很少人提了,但是最近有人开玩笑说它给MEPG7注入了新生命。
这里面的关键技术,一个是选择特征点,然后选择特征,把这些特征进行聚合、进行压缩、进行点压缩,最后形成个非常小的。举例来说有多小,比如你照了个照片,这个照片有3、4兆大的尺寸,我们从中提出来大概500个bit,连1K都不到,就可以进行搜索了,最高可以到16K,16K检索的效率就更高,我们判断特征好不好是用召回率来判断,我们都希望召回率达到90%,低于90%就认为这个特征没有选好。什么叫召回率90%?我用完整的照片到库里搜出来的东西,和我这用521个去搜,是不是有90%都在我刚才搜的100个里面,如果是的话那你这个特征是可以的,我们是根据这个准则。
它后台的技术涉及到,比如数据压缩的技术,涉及到计算机视觉特征提取,涉及到机器学习和视觉挖掘。特征和视觉有关的主要是局部描述子,如果大家对模式识别知道一点的话,里面有个非常好的描述词叫“SIFT特征”,这个特征它有一些特点,它可以保持平移不变、旋转不变、伸缩尺度不变等,有这个特征在识别里面是蛮有用的。但是这个特征有点毛病,一个是专利问题,另外是耗费存储比较大,耗费计算时间比较大。
这个在目前互联网上和视频监控里已经有一些应用,这是我们搭的验证系统,左边是摄像头实时对着马路,中间是这个系统,经过这个系统,右边的这个是车的车牌号、是哪个摄像头的、颜色等等马上就出来了。所以这套系统只要一上线,将来做布控是非常简单的事。
总结
总结一下,对多媒体大数据、对智慧城市或智能城市有三个挑战问题:压缩问题、模式识别问题、视觉搜索问题。针对这些问题,压缩主要是靠提高编码压缩的效率来应对;识别问题我们要想法做好编码,做些ROI的支持,把这些信息尽可能包含进去,使得后面丢失的信息更少一点;视觉搜索的问题可以采用紧缩的描述形式,使得搜索的速度更快,现在这个系统基本上是100万张图片可以在1秒之内完成搜索,这个速度是非常快的。
这个领域关注的人没有像金融那么多,但是它对整个系统的影响是比较大的,所以也请做系统的人稍微留心一下,另外也需要和做数据科学的其他领域多交流沟通,使得这个系统融入真的大数据平台里。谢谢大家!
更多精彩内容,请关注直播专题 2015中国大数据技术大会(BDTC) ,新浪微博 @CSDN云计算 ,订阅 CSDN大数据 微信号。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

