分析tpserver启动时偶发CPU飚升,甚至hsf线程池满
该文章来自阿里巴巴技术协会( ATA )精选集
序言
aliexpress(中文:速卖通)是个快速成长的国际化电商平台,肩负开拓海外市场的重任。
随着业务飞速膨胀(多语言、多币种、海外仓、分站、无线、区域化),网站代码也在不停增长,同时也在不停涌现新应用。
而本文的主角tpserver担当aliexpress的交易流程核心服务这一职责,虽然它最近才经历了一次拆分(逆向流程被剥离了出来),但还背负了各种历史包袱。
简单说就是tpserver提供33个接口的hsf服务,监听16种notify消息,1种metaq消息。
通俗一点就是从下单开始,后续所有交易流程都由这一个系统提供服务,维护每一个订单的生命周期。
背景
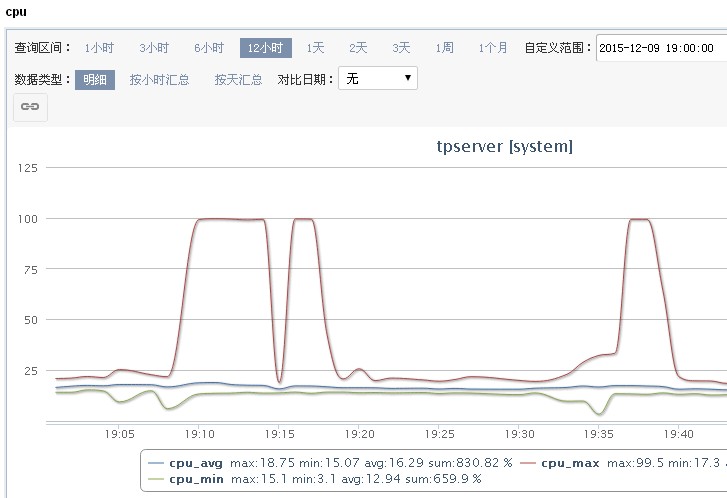
一般应用都存在重启时cpu偏高的现象,因为应用需要做初始化,虚拟机会装载很多类,二期很多各种各样的资源需要缓存起来,tpserver也不例外,以前最多就占40%的cpu。
随着为了保障2015双十一大促,tpserver做了集群拆分,拆出了下单专用的核心集群tpservercore,然后原来普通集群tpserver的机器就减少了,应用容量一般维持在30%的水位。
随着统一升级tddl、hsf等等,重启时的CPU也一路走高到100%,偶尔会出现线程池满。这个时候外围应用调用tpserver普通集群会出现较多超时,一般经过1分钟内的消化,应用渐渐稳定,各项指标也都会恢复正常。
期间联系tddl、集团内部JVM、hsf的相关同学一块从tddl,jvm预编译、hsf优雅上下线都排查实施了一遍,结果还是没有彻底解决这个问题。
由于是偶发、会自动恢复,随着大促最后冲刺,这个事情就放了下来。多次发布tpserver的同学形成了默契,发布tpserver的时候每批都暂停5分钟,这样异常也受控。
就这样一直推到了2015-12-09下午,突然接到tpserver很多线程池满的报警,一问了解到有同学正在连续发布tpserver,于是再次排查。
排查
一般HSF线程池满的快速排查方法
1,确认是不是由于消费的外部服务或DB的rt变长或网络抖动引起
——这种就是要翻看各个监控或/home/admin/logs/hsf/hsf.log来确认,比较繁琐,但也是比较容易处理:通知相关服务同学跟进
2,本机存在性能较差的代码
——这种得靠分析jstack导出的线程堆栈了, 链接文章介绍得非常详细,建议有兴趣的同学仔细阅读 。
但像tpserver这种随机爆发+一会就自动恢复,就要拼手快了!之前很多同学分析过很多次就是没有拿到有价值的堆栈,因为登上去执行jstack的时候,应用已经恢复了。
这个时候要吐槽一下hsf,其提供了在线程池满的时候会自动生成一份/home/admin/logs/hsf/HSF_JStack.log文件,但是每次都没拿到问题发生现场。
快速排查结论
经过查看各类监控与日志文件,确认外部服务与数据库的rt与网络都没有明显变化,看来很可能“本机存在性能较差的代码”。
深入单台机器排查通
如何确认load最高的机器,请使用神器xflush链接
http://xflush.alibaba-inc.com/optimus/#/10/app/detail/tpserver/ecs
(由于xflush暂时无法查看几天前的数据,所以图就不贴了)
挑选一台正在报警的机器,第一次用sudo -u admin jstack -p pid > ~/cpu.tdump,后续就用sudo -u admin jstack -p pid >> ~/cpu.tdump来附加到先前的文件,这样能快速导出多份线程堆栈到一个文件里,利用最近发现的一个工具来分析线程趋势。
利用工具review thread dump
尝试了多台机器后终于发现一点线索,附图
阻塞的线程很多
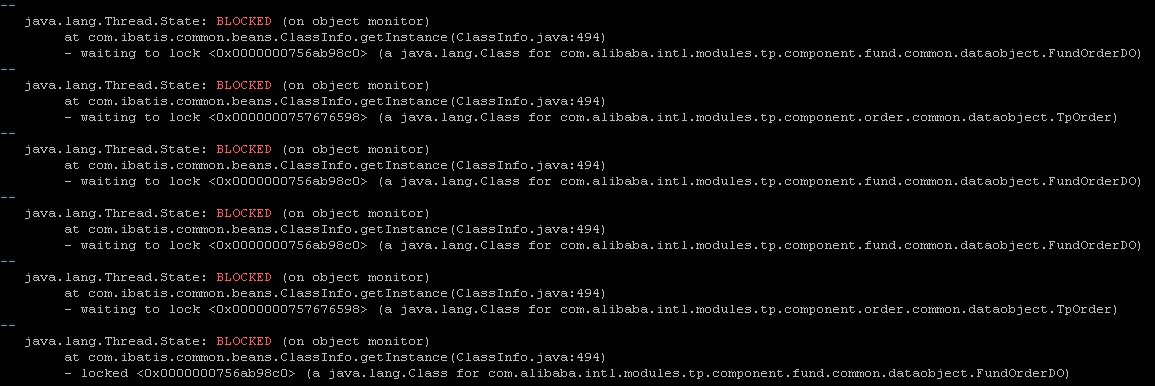
感觉问题就出在
at com.ibatis.common.beans.ClassInfo.getInstance(ClassInfo.java:494)
分析ibatis缓存核心代码
拉代码,直接看方法
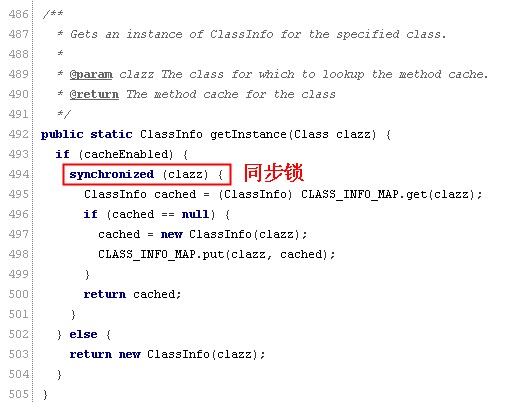
再看CLASS_INFO_MAP的实现

Collections.synchronizedMap(new HashMap())是一个通用的多线程安全方案,但是性能只能说一般,问什么呢,见源码


看来这么多线程被BLOCKED就是阻塞在要获取上面两个锁上面。
简单介绍一下几个数据集合类的差异
他们是 HashMap 、 HashTable 、 Collections SynchronizedMap 、 ConcurrentHashMap 。其中 HashMap 线程不安全, HashTable 、 Collections SynchronizedMap 、 ConcurrentHashMap 都线程安全。 | 对比项 / 类别 | Hashtable | Collections$SynchronizedMap | ConcurrentHashMap |
| ---- | ---- | ---- | ---- |
| 读需要锁 | 是 | 是 | 不需要 |
| 读锁对象 | this,也就是整个数据集 | 默认是this,也可以是定制对象,不管怎样还是相当于锁整个数据集 | 片段 |
| 写需要锁 | 是 | 是 | 不需要 |
| 加锁范围 | this,也就是整个数据集 | 默认是this,也可以是定制对象,不管怎样还是相当于锁整个数据集 | 片段 |
| 读写互斥 | 是 | 是 | 否 |
| 写同时并发读的影响 | 阻塞读,唤醒后拿到最新的整个表格 | 同Hashtable | 无阻塞,读取到当时最新的数据 |
验证
1,分析锁情况
再到tdump文件里验证,随便找一个被阻塞的线程

查找获得这个锁的线程,被阻塞在第二个锁

再查找获得这个第二个锁的线程

果然正在执行!
2,利用工具查看线程趋势
这里给大家介绍一个简单的tdump查阅工具samuraism
http://samuraism.jp/samurai/en/index.html 图例: 
可以看到在第一次tdump里就是由于线程"HSFBizProcessor-8-thread-123“阻塞了其他线程

第二次tdump里是由于线程"HSFBizProcessor-8-thread-457“阻塞了其他线程
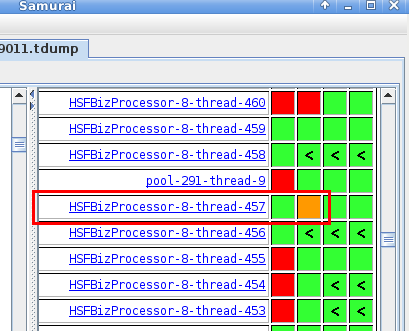
3,查看四次tdump的趋势
拆分之前连续四次的tdump文件为四个文件,统计趋势

被阻塞的线程逐渐减少
结论
由于ibatis的ClassInfo存在性能瓶颈,而tpserver暴露的相关依赖数据库的服务又很多,而且外部对tpserver的服务访问量又不断在增长,当超过这个阀值后,就会触发ibatis的ClassInfo两个锁冲突,降低应用的qps,提升相关请求的rt,使得消费方出现服务超时异常,影响用户。
措施
既然知道了原因,那解决起来就比较顺手了,主要从几个方面入手:提升性能、降低并发、绕过耗时,
提升性能的方法可以有:
这其实是ibatis的一个性能bug 链接
修改方式 链接 :
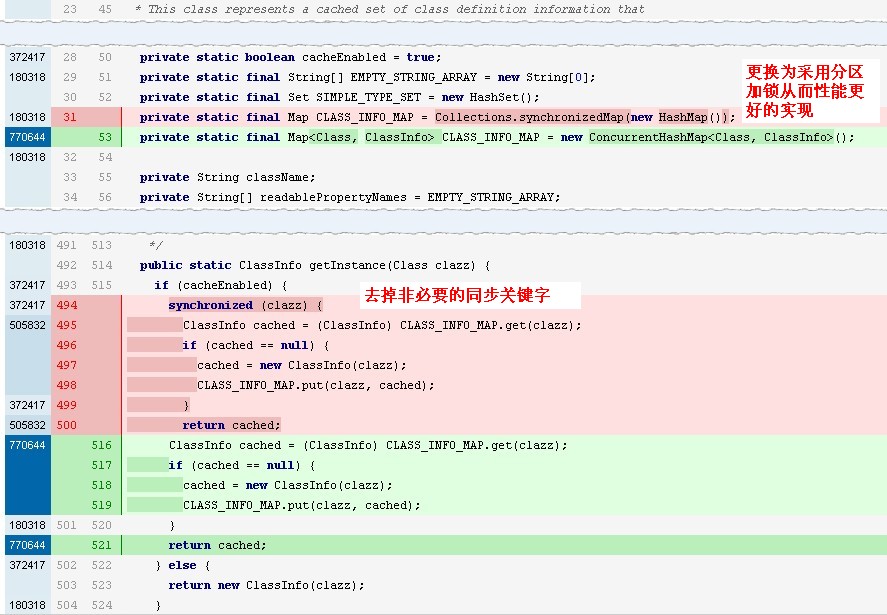
由于ibatis已经没有维护,无bug的版本已经迁移为mybatis,所以就有两个策略
1,迁移到mybatis二方包
迁移需要做一定的修改,见mybatis官方文档,存在较大工作量。
2,path现有ibatis二方包
在现有ibatis的版本下,直接path修改,然后发布一个全新path版本的二方包。
降低并发的方法可以有:
3,扩容tpserver普通集群
这个简单有效,但是明显不符合优秀工程师的原则!!!
4,拆分tpserver
依照领域模型将tpserver内各个业务拆分开来,这样压力会分摊到各个子系统,ClassInfo的并发得到有效降低。
绕过耗时的方法可以有:
5,应用预热
在应用内部spring容器初始化之后,提前访问并发量大相关表的查询服务,确保ibatis建立起需要缓存的相关class信息,最后再注册hsf服务。
以上方法不是依赖各种流程,就是需要投多资源,所以先走起方法1的流程,流程通过后升级应用依赖。然后方法5可以立即实施并发布到线上。
剩下的方法可以借着其它机会在后续再逐步推进。
验证
依照方法5的指导思想,添加预热代码后上线发布,如下图,效果很好!!!当然也有副作用,tpserver的启动时间又延长了30秒!!!

后续展望
- 各种第三方lib的升级速度得提上来了
- 按照领域与服务分层拆分庞大的tpserver
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

