深度学习:推动NLP领域发展的新引擎
文 / 雷欣,李理
从2015年ACL会议的论文可以看出,目前NLP最流行的方法还是机器学习尤其是深度学习,所以本文会从深度神经网络的角度分析目前NLP研究的热点和未来的发展方向。
我们主要关注Word Embedding、RNN/LSTM/CNN等主流的深度神经网络在NLP中的应用,这已经是目前主流的研究方向。此外,已经在机器学习或其它领域比较热门的方法,比如Multi-Model、Reasoning、Attention and Memory等,很有可能是未来NLP研究的热点,我们将着重关注。
Word Embedding在Word2vec被Mikolov提出之后,由于它能把一个词表示成一个向量(可以理解为类似隐语义的东西),这样最小的语义单位就不是词而是词向量的每一维了。比如我们训练一个模型用来做文本分类,如果训练数据里都是用“计算机”,但测试数据里可能用的是“电脑”,用词作为最基本单位(比如Bag of Words),我们学出来的模型会做出错误的判断。但是如果我们用一个很大的未标注的语料库来训练一个Word2vec,我们就能知道“计算机”和“电脑”语义是相似的,因此它们的词向量也会是类似的,比如100维的词向量某一维和计算机相关,那么“计算机”和“电脑”的词向量在这一维度都会比较大,用它作为基本单位训练模型后,我们的模型就能利用这一维特征正确地实现分类。当然如果数据量足够大,可以把模型的参数和词向量一起训练,这样得到的是更优化的词向量和模型。
但是Word2vec忽略了一些有用的信息,比如词之间的关系(句法关系)、词的顺序、以及没有利用已有的外部资源。针对这些问题,有很多改进的工作。
引入词的关系最常见的思路就是用Dependency Parser,把抽取出来的Relation作为词的Context。
改进Bag of Words有人认为词(Word)的粒度也太大,可以到Character级别的,或者Morpheme级别的。
外部资源和知识库Word2vec只使用了词的上下文的共现,没有使用外部的资源如词典知识库等,因此也有不少工作对此进行改进。
RNN/LSTM/CNNRNN相关的模型如LSTM基本上算是解决结构化问题的标准方法了,相比于普通的FeedForward Network,RNN是有“记忆”能力的。
普通的神经网络只会在学习的时候“记忆”,也就是通过反向传播算法学习出参数,然后就不会有新的“记忆”了。训练好了之后,不管什么时候来一个相同的输入,都会给出一个相同的输出。对于像Image Classification这样的问题来说没有什么问题,但是像Speech Recognition或者很多NLP的Task,数据都是有时序或结构的。比如语音输入是一个时序的信号,前后帧的数据是相关的;而NLP的很多问题也都是序列或者层次的结构。
RNN拥有“记忆”能力,如图1所示,前一个输出是会影响后面的判断的。比如前一个词是He,那么后面出现is的概率比出现“are”的概率高得多。最简单的RNN直接把前一个时间点的输出作为当前输入的一部分,但是会有Gradient Vanishing的问题,从而导致在实际的模型中不能处理Long Distance的Dependency。目前比较流行的改进如LSTM和GRU等模型通过Gate的开关,来判断是否需要遗忘/记忆之前的状态,以及当前状态是否需要输出到下个时间点。比如语言模型,如果看到句子“I was born in China, …. I can speak fluent Chinese. ”,如果有足够的数据,LSTM就能学到类似这样东西:看到“I was born in”,就记住后面的单词“China”,当遇到“speak”时,就能知道后面很可能说“Chinese”。而遇到“Chinese”之后,其实就可以“忘掉”“China”了。
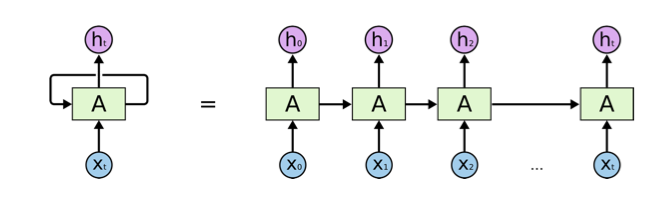
图1 RNN拥有“记忆”能力
CNN(LeNet)最早是Yann Lecun提出用来解决图像识别的问题的一种深度神经网络。通过卷积来发现位置无关(Translational Invariance)的Feature,而且这些Feature的参数是相同的,从而与全连接的神经网络相比大大减少了参数的数量,如图2所示。

图2 CNN深度神经网络
最近CNN相关的改进模型也被用于NLP领域。今年的ACL上有很多RNN/LSTM/CNN用来做机器翻译(Machine Translation)、语义角色标注(Sematic Role Labeling)等。
Multi-model Deep Learning这是当下的一个热门,不只考虑文本,同时也考虑图像,比如给图片生成标题(Caption)。当然这和传统的NLP任务不太一样,但这是一个非常有趣的方向,有点像小朋友学习看图说话。
这样的实际应用非常多,比如像Facebook或者腾讯这样的社交平台每天都有大量的图片上传,如果我们能给图片生成标题或者摘要,就可以实现图片的文本搜索以及语义分析。
图3来自Google DeepMind的论文,根据图片自动生成Caption,很好地为图片做了文本摘要。

图3 根据图片自动生成Caption(图片来自Google DeepMind的论文Show and Tell: A Neural Image Caption Generator)
Reasoning, Attention and Memory前面说RNN/LSTM是试图模拟人类大脑的记忆机制,但除了记忆之外,Attention也是非常有用的机制。
Attention最早Attention是在《Recurrent Models of Visual Attention》这篇文章提出来的,它的主要思想是:人在看一个视觉场景时并不是一次看完,而是把注意力集中在某个区域,然后根据现有的数据决定下一次把注意力放到哪个地方(笔者的理解:比如我们看到的图片是一条蛇,我们先看到蛇的头部和它弯曲的角度,根据我们对于蛇的先验知识,那么我们可能推断它的身体在右下的某个地方,我们的注意力可能就会直接跳到那个部分)。
这篇文章提出的RAM(Recurrent Attention Model)模型:它把Attention当成一个顺序决策问题,决策Agent能够与视觉环境交互,并且有一个目标。
这个Agent有一个传感器能探测视觉场景的一部分,它通过这些局部数据抽取一些信息,但是它可以自主控制传感器的运动,也能做出决策来影响环境的真实状态。每次行动都会有奖励/惩罚(可能是延迟的,就像下棋一样,短时间看不出好坏,但多走两步就能看出来了),而Agent的目标就是最大化总的奖励。这个模型优化的目标函数是不可导的,但可以用强化学习来学出针对具体问题的策略(笔者的理解:比如识别一条蛇,我可能有一种探测路径,但识别章鱼,我可能有另一种路径)。
另外,关于Attention,Google DeepMind的一篇论文《DRAW:A Recurrent Neural Network For Image》有一段非常好的解释:
引用
当一个人绘画或者重建一个视觉场景时,他能自然地用一种顺序迭代的方式,每次修改后重新评估它。粗糙的轮廓逐渐被更精确的形状代替,线条被锐化,变暗或者擦除,形状被修改,最终完成这幅图画。
从上面的分析可以看出,Attention除了模仿人类视觉系统的认知过程,还可以减少计算量,因为它排除了不关心的内容。而传统的模型如CNN,其计算复杂度就非常高。另外除了计算减少的好处之外,有选择地把计算资源(注意力)放在关键的地方而不是其它(可能干扰)的地方,还有可能提高识别准确率。就像一个人注意力很分散,哪都想看,反而哪都看不清楚。
Attention最早是在视觉领域应用,当然很快就扩展到NLP和Speech。
- 用来做机器翻译:Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. 2015. In Proceedings of ICLR.
- 做Summary:Alexander M. Rush, Sumit Chopra, Jason Weston. A Neural Attention Model for Sentence Summarization. 2015. In Proceedings of EMNLP.
- Word Embedding: Wang Ling, Lin Chu-Cheng, Yulia Tsvetkov, et al. Not All Contexts Are Created Equal: Better Word Representations with Variable Attention. 2015. In Proceedings of EMNLP.
- Speech领域:Attention-Based Models for Speech Recognition. Jan Chorowski*, University of Wroclaw; Dzmitry Bahdanau, Jacobs University, Germany; Dmitriy Serdyuk, Université de Montréal; Kyunghyun Cho, NYU; Yoshua Bengio, U. Montreal. 2015. In Proceedings of NIPS.
- 其它的应用,比如Multimodel,Image的Caption生成:Kelvin Xu, Jimmy Ba, Ryan Kiros, et al. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. 2015. In Proceedings of ICML. Karl Moritz Hermann, Tomáš Kočiský, Edward Grefenstette, et al. Teaching Machines to Read and Comprehend. 2015. In Proceedings of NIPS.
前面最早的Attention Model是不可导的,只能用强化学习来优化,也被叫做Hard Attention,也就是把注意力集中在离散的区域;后来也有Soft的Attention,也就是在所有的区域都有Attention,但是连续分布的。Soft的好处是可导,因此可以用梯度下降这样的方法来训练模型,和传统的神经网络更加接近。但坏处就是因为所有的区域都有值(非零),这就增加了计算量。用个不恰当的比方,一个是稀疏矩阵,一个是稠密的矩阵,计算量当然差别就很大。
也有一些工作尝试融合Soft和Hard Attention的优点。
Memory的扩展前面说到RNN,如LSTM,有Memory(记忆),很多模型对此也进行了拓展。
比如Neural Turing Machine (Neural Turing Machines. Alex Graves, Greg Wayne, Ivo Danihelka. arXiv Pre-Print, 2014),NTM用一句话描述就是有外部存储的神经网络。如图4所示。
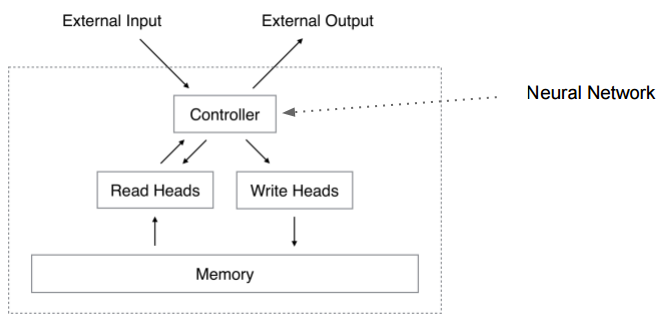
图4 NTM
Turing Machine有一个Tape和一个读写头,Tape可以视为Memory,数据都放在Tape上,TM的控制器是一个“程序”,它读入Tape上的输入,然后把处理结果也输出到Tape上。此外Turing Machine还有个当前的State。
而NTM的控制器是一个神经网络(Feedforward的或者Recurrent的如LSTM),其余的都类似,只是把古董的Tape换成了现代的寻址更方便的Memory,Input和Output也分离出去的(看起来更像是现代体系结构下的计算机)。
我们传统的编程其实就是编写一个Turing Machine,然后放到Universal Turing Machine上去运行(UTM和TM是等价的,UTM是能运行TM的TM)。传统的编程比如写一个“Copy”程序,我们知道输入,也知道期望的输出,那么我们人脑来实现一个程序,我们用程序这种“语言”来表达我们的想法(算法)。
而NTM呢?它希望给点足够多的输入/输出对(训练数据),Controller(神经网络)能学习出“程序”来。
程序真的可以“学习”出来吗?程序员怎么“证明”它写的算法的正确性呢?
关于人类学习的归纳和演绎的争论。我觉得人类的学习都是归纳的,我们每天看到太阳从西边出来,因此“归纳”出太阳从西边出来这个结论,但是我们永远无法证明(演绎)出这个结论。演绎似乎只有“上帝”(或者数学家,哈哈,他们是上帝他们定义一些公理,然后不断演绎出整个体系,比如欧氏几何的五大公理演绎出那么多定理)才有的特权,他定义了宇宙的运转规律,然后一切都在这个规律下运作(演绎)。而人类似乎只能猜测上帝定义的规律,然后用这个猜测的规律进行演绎。如果没有发现破坏规律的现象,那么万事大吉,否则只能抛弃之前的猜测,重新猜测上帝的想法。但是上帝创造的规律能被受这个规律约束的智慧生命发现吗?也许得看上帝在创造这个规律时的心情?
普通的计算机程序读取输入,然后进行一些计算,把临时的一些结果放到Memory里,也从Memory里读取数据,最终把结果输出。只不过需要我们用计算机程序语言来指定其中的每一个操作步骤。而NTM也是一样。它对于每一个输入,都读取一下现有的内存,然后根据现有的内存和输入进行计算,然后更新内存。只不过这些操作是通过输入和输出“学习”出来的。
因为神经网络学习时需要连续可导,所以NTM的内存和我们现在用的计算机内存不同,现在的计算机都是离散的01,而NTM的内存是个连续的值。计算机的写只能是离散的01值,而NTM的写入是连续的实数(当然受限于硬件肯定是有限的浮点数)。而且和前面的Attention相联系,我们会发现它也是一种Soft Attention——对于某个程序,比如Copy,它的Attention是连续的变化规律(假设我们是用一个for循环来复制输入到连续的内存)。文章的作者尝试了一些简单程序,比如Copy、Associative等,NTM(LSTM作为controller)都比LSTM要好不少。不过Binary Heap Sort这种复杂一点的程序,NTM就没有学习出来,它学出来一个HashTable(这是让我等码农失业的节奏吗?)。
你也许会问NTM似乎对应的是TM,那和NLP有什么关系呢?
NLP是人类的语言,比机器的语言复杂。我们可以首先研究一下简单的机器语言,或许会有所启发。
但事实上NTM也可以用来做QA(问答)。
IBM做了著名的Watson,让人觉得似乎机器能真正的理解语言了。不过很多业内人士觉得离我们期望的机器理解语言还差得远,当然他们做了很多很有用的工作。
《Empirical Study on Deep Learning Models for QA》就是IBM Watson团队的尝试。在Facebook的人工构造QA数据集上融合并对比了当下热门三种DL方法:Neural Machine Translation、Neural Turing Machine及Memory Networks。得出的结论是:融合Memory组件和Attention机制在解决QA问题上具有巨大潜力。
我们可以看到在今年NIPS的RAM Workshop上很多用类似NTM这样的模型来做QA或者相关任务的文章。Facebook人工智能研究院(FAIR)在NLP的主要工作都是在RAM上。
Language的复杂性相对于Image和Speech,Language似乎更加复杂一些。
视觉和听觉作为人类与外界沟通最主要的两种感觉,经历了长期的进化。大部分动物都有发达的视觉与听觉系统,很多都比人类更加发达。拿视觉来说,老鹰的视力就比人类发达的多,而且很多动物夜间也有很强的视力,这是人类无法比拟的。但是人类的视觉应该有更多高层概念上的东西,因为人类大脑的概念很多,因此视觉系统也能处理更多概念。比如人类能利用钢铁,对汽车有细微的视觉感受,但是对于一条狗来说可能这些东西都是Other类别,它们可能只关注食物、异性、天敌等。
听觉系统也是如此,很多动物的听觉范围和精度都比人类高得多。但它们关注的内容也很少,大部分是猎物或者天敌的声音。
我觉得人类与大部分动物最大的区别就是社会性,社会性需要沟通,因此语言就非常重要。一些动物群落比如狼群或者猴群也有一定的社会性,像狼群狩猎是也有配合,猴群有严格的等级制度,但是相对于人类社会来说就简单得多。一个人能力相当有限,但是一个人类社会就非常强大,这其实就跟一个蚂蚁非常简单,但是整个蚁群非常智能类似。
作为沟通,人类至少有视觉和听觉两种主要的方式,但最终主要的沟通方式语言却是构建在听觉的基础上的。为什么进化没有选择视觉呢?当然也许有偶然的因素,但是我们可以分析(或者猜测)一下可能的原因。
你也许会说声音可以通过不同的发音来表示更多的概念,而且声音是时序信号,可以用更长的声音表示更复杂的概念。
但这是说不通的,人类能比动物发出更多不同种类的声音,这也是进化的结果。用脸部或者四肢也能表达很多不同的概念,就像残疾人的手语或者唇语,或者科幻小说《三体》里的面部表情交流。如果进化,面部肌肉肯定会更加发达从而能够表示更多表情。
至于时序就更没有什么了,手语也是时序的。
当然声音相对于视觉还是有不少优势的:
声音通过声波的衍射能绕过障碍物,这是光无法办到的(至少人类可见的光波是不行的)
- 衍生的结果就是声音比光传播得远
- 晚上声音可以工作,视觉不行(其实夜视能力也是进化出来的)
- 声音是四面八方的,视觉必须直面(当然有些动物的视角能到360度),背对你的人你是看不到他的表情的。
可以做很多分析,但不管怎么样,历史没法重新选择,事实就是人类的进化选择了声音,因此Speech就成了Language的一部分了。
因此单独说Speech而不说Language其实是没有太大意义的。
当然后来Language为了便于保存,又发展出文字这样的东西,而文字却是通过视觉来感受的,不过视觉只是把文字映射到概念而已。一些文字如汉字的象形还是和视觉形象有关联的,不过越到后来越抽象,就和视觉没有太大关系了。
人类思考的方式也是和语言相关的,数学就是一种语言,这是人类抽象现实世界的先进工具。
上面一大堆啰嗦,目的就是想说明Language是和人类的概念紧密相连的,因此远比Image/Vision更复杂。
人类社会之所以能进步,就是通过社会化的分工与协作,让不同的人进化不同的能力,从而使得整个社会全方位发展。而语言文字在其中发挥着至关重要的作用,通过语言文字的传播,人类积累的智慧就可以跨越时空传递。
回到我们的NLP或者NLU或者说机器理解人类语言,为什么我们对机器理解人类语言这么关注呢,因为语言基本等同于智力。机器能够理解语言也就基本能达到人工智能的目标,这也是为什么我们会认为如果机器能够通过图灵测试那么它就是智能的了。
语言其实是人类表达概念或者说知识的一种方式,人类的大脑通过进化已经很适应这种表示方式了。但这种逻辑的表示方式是抽象之后比较上层的表示(大脑神经元层级是怎么表示的还不太清楚)。目前主流的方法是深度神经网络,目的是模拟底层的大脑结构。这种方法是不错的一个想法。之前的NLP使用的方法都是规则的,其实也就是基于逻辑的,现在已经不太主流了。
但是不管用什么方法,现在的现实情况是人类已经使用语言来存储知识和表示概念,机器就得面对这种现实能够学会这种交流方式。因为我们没有时间也不可能让它们进化出另外一种表达方式。当然它们自己交流可以用自己的语言,比如TCP/IP语言,它们学习知识可以和人类那样给定很多输入/输出训练数据学习出来,也可以把训练好的模型直接从一个机器“复制”到另外一个机器,这是人类做不到的——至少目前还做不到。我们不能把爱因斯坦的物理模型复制到我的大脑里,也许未来医学和神经科学高度发达之后可以实现。但是目前来看把机器看成人类能力的拓展更可行。
深度学习的一个方向Representation Learning其实就是有这个想法,不过目前更多关注的是一些具体任务的Feature的表示。更多是在Image和Speech领域,用在Language的较少,Word2vec等也可以看成表示概念的方式,不过这种向量的表示太过简单且没有结构化。更少有工作考虑用神经网络怎么表示人类已有的复杂知识。现在的知识表示还是以几十年前基于符号的形式逻辑的为主。
我们现在甚至有很多结构化的数据,比如企业数据库、维基百科的、Google的Freebase以及内部的Knowledge Graph。但目前都是用人类习惯的表示方式,比如三元组、图或者实体关系。但这样的表示方式是高层的抽象的,大脑里的神经元似乎不能处理,因此现在的Deep Neural Network很难整合已有的这些知识库进行推理等更有用的事情。
总结从上面的分析我们大致可以看到最近NLP的发展趋势:深度神经网络尤其是RNN的改进,模拟人脑的Attention和Memory,更加结构化的Word Embedding或者说Knowledge Representation。我们看到了很多很好的进展,比如NIPS的RAM Workshop,很多大公司都在尝试。但是Language的问题确实也非常复杂,所以也不太可能短期就解决。不过也正是这样有挑战的问题,才能让更多有才华的人投身到这个领域来推动它的发展。
作者简介雷欣,人工智能科技公司出门问问&Ticwatch智能手表CTO,美国华盛顿大学西雅图分校博士,前斯坦福研究所(SRI)研究工程师,前Google美国总部科学家,语音识别领域十多年研究及从业者,领导开发了Google基于深度神经网络的离线语音识别系统。
李理,人工智能科技公司出门问问工程师,擅长NLP和knowledge graph。
正文到此结束
热门推荐








相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

