大数据系列之(一) Streaming模式基础知识
- 作者:Tyler Akidau
- 译者:张磊
- 原文: http://radar.oreilly.com/2015/08/the-world-beyond-batch-streaming-101.html
译者摘要
现在大数据,云计算已经成为互联网的标配,但是现在主流的大数据处理依旧是使用batch模式,batch模式就是将数据按某种规则分成块,然后对整个块跑计算逻辑,缺点是延迟太高(至少是分钟),常用的工具就是Hadoop。在日益变化的需求面前,高延迟越来越不能忍受,因此Streaming模式应运而生,他最大的特点就是低延迟,最快能到毫秒级别,常用的Streaming工具主要是storm,spark等,但是这些工具都有各自的优缺点,功能上不能完全取代batch,这篇文章就是想深入分析什么样的Streaming系统能彻底替代batch,并最终打败batch。
序
尽管现在市场上对streaming越来越关注,但是相对于batch来说,大部分streaming系统还不是很成熟,所以streaming系统正处于积极开发和进步中。
作为一个在分布式steaming系统上工作过5年的从业者(MillWeel, Cloud DataFlow), 我非常荣幸给大家分享streaming系统能解决什么问题,以及batch系统和streaming系统在语义上的区别,这非常重要,会帮助我们更好地使用它。内容众多,我会分成两篇文章来讲述:
- Streaming 101 : 本篇会先讲述一些最基础的知识和澄清一些专业术语,之后我们深入地讲述时间的作用,以及数据处理常用方法,这主要包括batch和streaming两种模式。
- The Dataflow Model : 第二篇用一些实际例子讲述Cload Dataflow, 它综合了batch和streaming两种模式。之后,我回总结现有batch和streaming系统在语义上的相同点和不同点。
下面是一篇很长的文章,不要分心。(译者:原文是nerdy,主要指呆滞但是专注的技术宅)
背景知识
本节讲述一些非常重要的背景知识,帮助理解剩下的部分。
- 术语 : 任何复杂的问题都需要精确的术语。我会尝试把一些被滥用的术语重新定义,所以让大家能明白我用他们的时候在说什么。
- 功能 :我会列举现有streaming系统常见的缺点,然后提出一个我觉得streaming系统应该有的功能,这些功能能够解决现有或者将来数据处理的需求。
- 时间问题(Time Domains) : 介绍两个数据处理中跟时间相关的两个定义,并分析他们是怎么互相联系,然后指出这两个时间给数据处理带来怎样的困难。
术语:什么是streaming?
在我们深入之前,我想先解决:什么是streaming。现在‘Streaming’有很多不一样的意义,让我们误解streaming到底能解决什么问题,所以我一定要先 精确 定义它。
问题的本质是:很多术语不是告诉我们他们是什么,而是告诉我们他们是怎么实现的,比如Unbounded data processing无穷数据处理和Approximate resulte近似结果处理被认为就是streaming,而实际上只是streaming常常用来解决这类问题,其实batch也能解决。没有精确定义的streaming被人们狭隘的认为streaming只是拥有某些常被称做‘streaming’的特性,比如近似结果。一个设计合理的streaming系统是可以提供 correct正确 , consistent一致 并且 repeatable可重复计算 的结果,就像现在所有批处理引擎,我觉得 streaming定义 是: 一种能处理无穷数据的数据处理引擎 。(为了这个定义更完整,我必须强调它包含了我们常说的streaming和micro-batch)。
下面是一些经常和‘streaming’联系在一起的几个术语,我分别为他们给出了更精确,更清楚的定义,我建议整个工业界都应该采纳它们:
- Unbounded Data无穷数据 :一种持续产生并且无穷的数据,他们经常被称为‘streaming data’流数据,但是用streaming和batch去描述数据是错误的,正如我刚才说的,这两个词隐喻只能用某种类型 执行引擎 去处理这类数据。数据只分成两类:无穷和有限,不能说数据是streaming或者batch。我建议当我说infinite ‘streaming’ data无穷流的数据请直接用unbounded data无穷数据,当我们说finite batch data有限‘batch’数据时直接用bounded data有限数据。(译者:作者只是强调streaming和batch不能用来描述数据,它们只是数据处理的方式。)
- Unbounded data processing无穷数据处理 :一种用来处理无穷数据的方式。我自己也常常使用streaming来代表这种方式,但是不对的,batch也能实现它。因此,为了减少误解,我不会用streaming来代替它,我会直接使用无穷数据处理这个术语。
- 低延迟,近似结果 :他们经常跟流处理引擎连在一起。批处理系统通常不是设计用来解决低延迟近似结果,这是现状,不代表它不可以。事实上,批处理引擎是可以提供近似结果的。因此,低延迟就是低延迟(译者:延迟是指从系统收到消息,到完成整个消息计算的时间差),近似结果就是近似结果(译者:很多计算开销很大,近似结果用很少的开销就能提供可控的精度的正确性,比如yahoo最近开源的 Sketches 就能解决unique users count),不要用streaming流处理引擎去代表他们。
到此,我已经定义了什么是流处理引擎:一种用来处理无穷数据的引擎,对于其他术语,我不会用streaming来替代他们。我们已经在Cloud Dataflow中使用这些术语了,我建议其他人也可以采用它们。
(译者:在下面的文章中,我会直接用streaming和batch来代替流处理引擎和批处理引擎,这样可以少敲几个字,敲字很辛苦)
泛化streaming的功能
下面让我们看看streaming到底能做什么和不能做什么,特别是设计合理的streaming能做什么。长久以来,streaming被工业界狭隘地认为是提供低延迟,近似结果,批处理是用来提供正确结果的,比如 Lambda Architecture (译者注:下文我会用Lambda架构表示,我理解为啥叫它Lambda)。
如果你熟悉Lambda架构,你应该知道这个架构最基本的思想就是使用批处理引擎和流处理引擎,执行一样的计算,流处理引擎提供低延迟不精确结果(可能是使用近似算法,或者流处理就不准备提供正确性),之后批处理引擎提供正确的结果,覆盖流处理引擎的结果。起初,这个架构,由 Nathna Marz, Storm创始人 提出,真的获得不少成功,因为这个想法在当时看来真是不错,那时候流处理引擎还不令人满意,批处理引擎也不能像我们预期的那样发展得很好,Lambda架构却提供一种短期解决方案,并且很多项目真的用了。Lambda架构也存在缺点:维护成本高,你需要维护两套独立的系统,而且需要在最后合并他们的结果。
作为一个在 强一致 流处理引擎工作多年的从业人员,我不同意Lambda架构的出发点,而且我特别喜欢 Jay Kreps’ Questioning the Lambda Architecture 这篇文章,它很有远见地质疑了双引擎的必要性,并且给出很强的理由。Kreps使用repeatability可重放的消息队列系统 kafka 去解决repeatability可重放问题,然后他提出一种新的架构:Kappa架构:基本思想就是只使用一套合理设计的引擎。虽然我不认为这个概念需要一个新的名字,但是我非常赞同他的思想。
(译者:可重放是指你可以随时回到一个时间点顺序读取任何信息,kafka能做到这点,但现实是kafka也有开销,比如你的model需要一年的历史数据,你会让kafka存下一年的数据?基本上不会,你应该把数据存在开销更低的系统,比如hadoop,但是streaming系统可以读取回这些历史数据)
现在我们应该更近一步,我认为:设计合理的streaming是可以提供比batch更多的功能,到那时我们不再需要batch。(译者:当前所有streaming比batch占用更多的资源,从商业上说batch一定会持续存在直到streaming能更加高效利用资源)Flink就是利用这个想法创造了一个完全的streaming系统,并且支持batch模式,我非常喜欢它。
随着streaming系统越来越成熟,它将提供一种无穷流处理的框架,并且让Lambda架构消失在历史中。我相信它已经在发生。如果我想彻底打败batch,我们需要完成两件事:
正确性:这让streaming和batch能够等同。
本质上,正确性取决于consistent一致的存储。steaming需要一种类似checkpointing持久化存储,正如Kreps在它这篇文字所写,这种存储在机器挂掉的情况也能保证一致性。当几年前Spark streaming首次出现时,它在streaming世界里就是一致性的代名词。一切都在向前发展,仍有很多streaming系统不提供强一致性,我实在是不理解为啥at-most-once仍然存在,但是实际情况它还在。(译者:如果at-most-once指的是系统保证这个消息最多被处理一次,其他方式是:at-least-once至少一次和exactly-once只有一次,作者想表达的是最多一次就是系统会丢数据,除非你不关心正确性,否则这种方式就不该存在。但实际是上实现三种方式的开销不一样,随着系统越来越成熟,可能三种开销就不会那么大,到那时候估计就没人愿意使用最多一次的方式了。)
重要的事情再说一次:强一致性必须要exactly-once处理,否则无正确性可言,而且只有这样才能追上并且最终超越batch系统。除非你毫不在乎结果的正确性,否则我真诚地建议你放弃任何不提供强一致性的streaming系统,不要浪费时间在他们身上。
如果你真的想学习如何给streaming系统设计强一致性,我推荐你可以读读 MillWheel 和 Spark Streaming 的论文,这两篇论文都花费了很长的时间讲述一致性。本文时间有限,就不在此详述了。 (译者:还没读,看完会给大家分享下)
时间工具:这让streaming超越batch。
当我们处理无穷无序数据时,时间工具是一切的基础。当前,越来越多的需求要求我们处理无穷无序数据,而现有batch系统(包括大多数streaming系统)都缺乏必要的工具去解决这个困难。我会用本文剩下的部分和下一篇文章着重解释它。(译者:无序是难点,大部分分布式系统都不可能提供顺序保证,这里时间工具是指系统提供api,让我们自己控制超时以及如何按时间分块,下面会有详述。)
我们首先会了解时间问题中重要的概念,而且深入分析什么是无穷无序数据的时间差,之后我会用剩下的部分讲解batch和streaming系统处理有限和无穷数据的常用方法。
Event Time和 Processing Time
- Event time发生时间 :事件实际触发时间(译者:我常叫client time,比如你了解手机app5分钟活跃度,那Event time就是你实际用手机的时间,由手机app打的时间戳)
- Processing time处理时间 :时间被系统获知的时间(译者:我常叫server time,当事件进入这个系统的时间,大部分是应用层收到消息后加的时间戳。)
(译者:下面我会直接用event time 和processing time)
很多需求都不关注event time,这样的生活会简单很多,但是还是有不少需求是关心的,比如为带时序的用户行为建立特征,大多数付费应用和很多异常检查。(译者:广告的attribution就是带时序的行为,你只能在看过广告后点击)
完美情况下,Event time和processing time应该永远是相等的,事件发生后立即被处理。现实是残酷的,两者的时间差不仅不是0,而是一个与输入,执行引擎和硬件相关的函数。下面几个是经常影响时间差:
* 有限的共享资源:比如网络阻塞,网络分区,不独占条件下的共享CPU
* 软件:分布式系统逻辑,竞争
* 数据本身的特征:包括key的分布,吞吐量差异,无序(比如:很多人在坐飞机时关闭飞行模式使用手机,等手机网络恢复后手机会把事件发给手机)
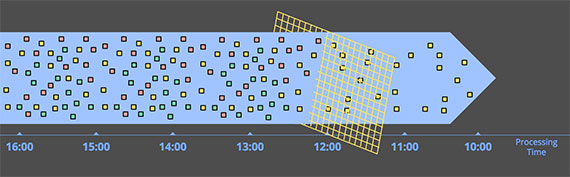
下图就是一个真实的event time和processing time差异图:

黑色点线代表两个事件完全一致。在这个例子中,系统延迟在中间到最低点。横向距离差代表两个时间的时间差,基本上这个时间差都是由延迟导致。
这两个时间没有固定的相关性(译者:不能简单的用一个函数去计算),所以如果你真的关心event time,你就不能用processing time去分析你的数据。不幸的是大多数现有系统都是用processing time去处理无穷数据,他们一般都会将输入按processing time用一些临时的分界线拆分小块去处理。
如果你们系统关心正确性,那就千万不能用processing time去分块,否则一部分消息会因此被分到错误的块,无正确性而言。我们会在下面看到更多这样的例子。
即使我们用event time作为分界线,其实也不能实现正确性。如果event time和processing time之间没有一个可预测的关系,你怎么能确定你已经收到所有消息?(比如:你要统计5分钟的数据,你怎么能保证收到所有5分钟的数据)现在大部分数据处理系统都依赖某种“完整性”,但是这么做让他们处理无穷数据遇到严重的困难。(译者:完整性一般都是用超时来实现,等一段时间发现没有了就放弃)
我们应该设计工具能够让我们生活在这种不确定性中(译者:不确定性是指时间差不能预测)。当新数据到底时,我们可以获取或者修改老数据,所有系统都应该自然而然去优化“完整性”,而不是认为它至少可有可无的语义。(译者:优化完整性的意思是系统能够提供api控制超时。)
在我们深入如何实现类似Cloud Dataflow数据模型前,我们先了解一个更有用的话题:常见数据处理方式。
数据处理方式
现在我们可以开始谈一些重要的数据处理模式了:batch和streaming(我把micro-batch归到streaming中,因为两者差异在这里不是很重要)。
有限数据
处理有限数据很简单,大多数都已经熟悉。在下图中,左边是一个完整数据集,中间是数据处理引擎(一般是batch,当然一些设计合理的streaming也可以),比如 MapReduce ,右边则是处理的结果:
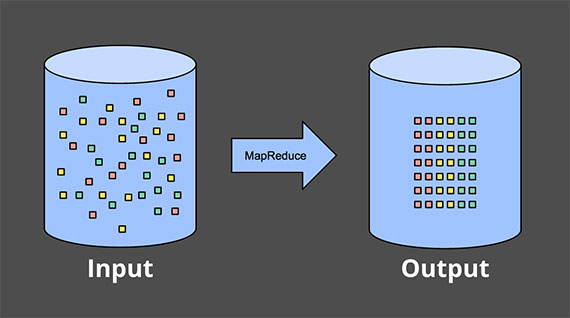
更让我们感兴趣的是无穷数据,我们会先分析传统的batch,然后分析常见streaming或者micro-batch。
无穷数据 —— batch
虽然batch从字面上看不像用来处理无穷数据,但是从它出生就已经被业界使用了。大家都能想到,只要我们能把无穷数据分块,我们就能用batch引擎出处理。
固定窗口
最常见的方法就是把数据拆分成固定大小的块,然后依次处理各个块数据。特别是日志数据,我们可以自然而然把数据拆分成以时间为单位的树状结构,这个很直观,因为基本上就是按event time分块。
实际上,大部分系统仍然要处理完整性问题:如果一些事件由于网络延迟到达,怎么办?如果消息是全球的,但是存在一个公共地方,怎么办?如果事件来自手机,怎么办?我们可能需要用一些特别的办法解决它们:比如延迟事件处理直到所有数据都到达,或者重新计算整个数据集只要有新的数据到达。
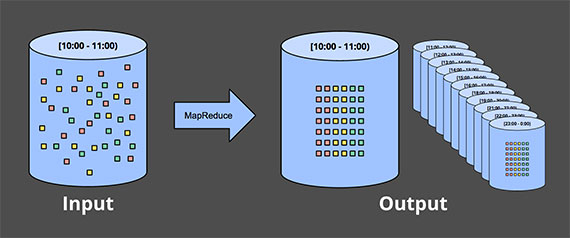
** Sessions 序列 **这个比简单分块复杂,我们需要把事件拆的更细。Sessions一般是指把事件按活跃间隔拆分。如果在batch中计算sessions,你会出现一个Session横跨多个块,比如下图红色部分。当然,当你增加每个batch的时间间隔,这种横跨多个batch的概率会降低,但是它会带来更高的延迟。另外一个方法是增加额外的逻辑出处理这种情况,代价是逻辑复杂。
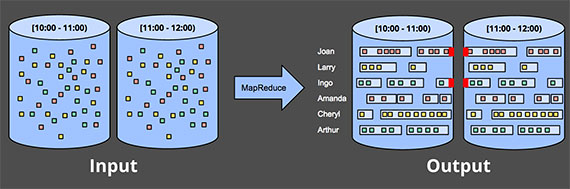
两者都不是完美的方法,更好的方法是用streaming的方式处理session,我们下面会讲。
无穷数据 —— streaming
streaming从开始就是设计用来处理无穷数据,这跟大多数batch引擎不太一样。正如我们上面说的,大多数分布式系统的数据不只是无穷,还是一些其他让人讨厌的特性:
- 无序数据 :意味着你需要处理时序问题,如果你关心event time。(译者:所有事件从绝对时间上看,一定都是有顺序的,如果一切都是单机,你一定定保证顺序。)
- event time时间差 :你不能保证在X+Y时能看到大部分X发生的数据,这里Y是固定的数值。(译者:还是强调消息到底的不确定性)
因此出现了一批处理这类数据的方法,我大致把他们分为4类:
- Time-agnostic 时间无关的逻辑
- Approximation 近似算法
- Processing time分块
- Event time分块
我们简单分析下他们
Time-agnostic
这类处理逻辑完全跟时间没关心,只是更数据本身有关,batch和streaming在处理这种逻辑时没有本质区别,所以大部分streaming都支持。当然batch引擎也支持,你可以用任意方法把数据分块,再依次处理。下面是一些实际例子:
Filtering过滤
最基础的逻辑,比如你在处理web日志,你想要某些域名的数据,你可以在每个事件到底的时候丢掉那些不想要的,跟无穷,无序,时间差一点关系都没有。
Inner-joins
当join两类数据时,你只关系两者都到达的情况,如果一方先到,你可以把它存起来,等第二个到底之后取回前一个,然后计算。当然你想回收一些单个事件占用的资源,那就是跟时间有关了。(译者:超时回收)
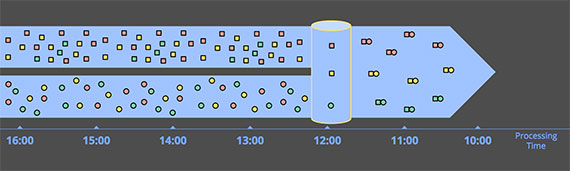
当然如果要支持某些outer-join,就存在数据完整性问题:当你看到一方时,你怎么知道另一方是否还会来?你肯定不知道,除非你设计超时,超时又跟时间相关,本质上又是另一种形式的分块,我们会详细分析。
近似算法
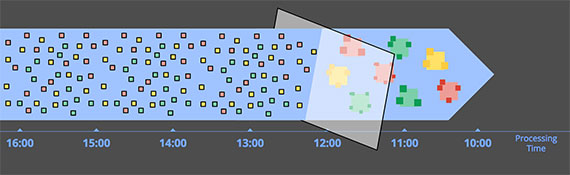
第二大类就是近似算法,比如近似Top-N,streaming K-kmeans等等。近似算法的好处是开销低,可以处理无穷数据。坏处是这类算法数量有限,而且实现复杂,近似的本质限制他们的使用,不可能所有场景都能用近似。这些算法大多数都有一些时间特征,比如decay,当然他们大多用processing time。另一个很重要的特点就是他们都提供可控的错误率。如果错误率可以根据数据到达的顺序预测出来,这些错误率就可以忽略不计,即便是无穷数据,这点很重要,你最好能记住这点。
近似算法让人很兴奋,但本质上是另一种形式的时间无关算法。
分块
剩下两个方法都是讲如何将数据按时间分块。我想先讲明白啥是windowing,它就是把无穷或者有限数据按分界线拆分成有限的块。下图是三种不同的分块策略:
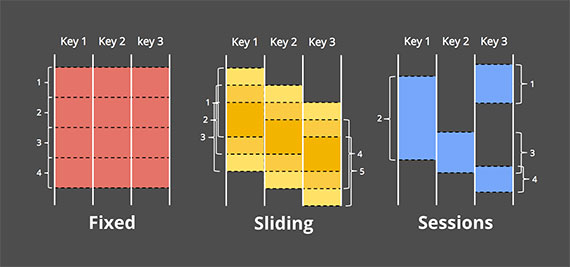
- Fixed windows 固定窗口 :按时间分成固定大小的块。
- Sliding windows 滑动窗口 :更一般的固定窗口,滑动窗口一般都是固定长度加上固定时间段。如果段小于长度,滑动窗口就是重叠的,否则就是sampling窗口,只使用部分数据。跟fixed窗口一样,大部分滑动窗口都是对齐的,有时候我们用不对齐的方式优化性能。
- Sessions 序列 :动态窗口,用不活跃段将所有事件分成一个个session,所以session是一串连续的事件,不活跃段都是用超时时间。session一般用来分析用户行为数据,取决于实际时间情况,不能预先计算。sessions是经典的不对齐窗口,因为没有两个人的数据是完全相同的。
我们会看看用processing time和event time去分窗口到达有什么不同,当然从processing time开始,因为它更常用。
** Processing time分块 **
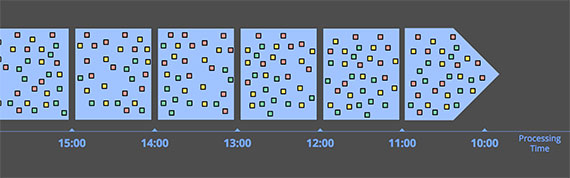
系统只需要保存来的数据直到一段时间完成。比如:5分钟分块,系统可以保存5分钟的数据,然后认为所有数据都到了,发给下游处理就行。这种方式有下面几个很好的特性:
- 简单 :你不需要管时间是否乱,只需要保存来的数据,到时扔给下游
- 完整性 :系统能清楚的知道数据是否完整,没必要处理“晚来”的数据。
- 如果你想推断一些关于上游的情况,只需要用processing time。 : 监控系统就是最好的例子,比如你想知道一个全球化web service的QPS,使用processing time计算QPS是最好的方法。
当然processing time也有缺点: 如果数据含有event time,并且你想用processing time来分块解决,那么这些数据必须是有序的。 不幸的是分布式上游大部分无法保证有序。
一个简单的例子:手机app想了解用户使用情况。如果一个手机断网一段时间,这段时间的数据不会即时发到服务器端直到手机再次连网。我们无法用processing time分块获得任何有用的信息。
另一个例子:有些分布式上游在正常情况下可以保证event time顺序,但是不代表上游一直能保持一样的时间差。比如一个全球系统,由于网络问题,可能某个州的网络导致很高的延迟,如果你是processing time分块,分块的数据已经不能代表当时的情况了,可能是新旧数据的混合。
我们希望这两个例子都是用event time分块,保证逻辑的正确性。
** Event time分块 **
Event time分块能让我们观察到上游数据在事件发生时的情况,这是最正确的方法。但是,大多数数据处理系统都没能从语义很好的支持它,虽然我们知道任何强一致性的系统(Hadoop或者Spark Streaming)经过一些修改是能解决的。(译者:作者说从语义上支持就是系统能保证按Processing time分块,我常用的工具都没有这样的语义)
下图显示了一个按event time分成一小时的块:
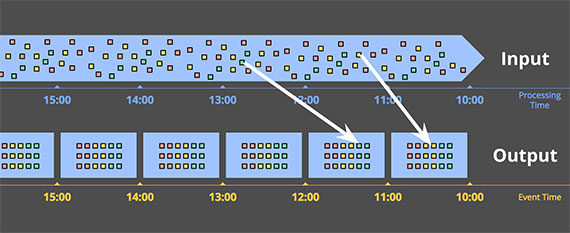
白色的线代表事件的processing time不同于event time。毋容置疑,event time分块一定能保证event time正确性。
另一个好处是你可以创建动态大小的块,比如session,但是不存在session跨越多个固定的块。
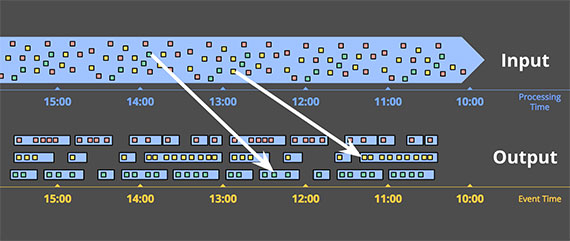
当然,任何事情都是有代价的,包括event time分块。它有两个很明显的缺点,因为块必须比实际长度存活更久:
- Buffering :更长的生命要求我们保存更多的数据。很幸运,现在持久化已经是数据处理系统中最便宜的资源了,相对于CPU,网络带宽和内存来说,因此buffer不是太大的问题,至少比设计强一致性存储和内存cache要容易。很多聚合操作不需要保存整个输入,比如和或者均值。
- Completeness 完整性 :我们都没有好方法知道所有数据都到了,我们如何知道何时发布结果?而且我们没法简单计算“何时”。(译者:发布数据是指让下游感知,比如把数据结果更细到DB)对于大部分情况,系统能使用类似MillWheel的watermarks去可靠地预测数据是否完整(我会在下一章讲)。但是在某些情况下,正确性非常重要,想想计费系统,我们唯一的方法是提供一个方法让系统自己能够控制什么时候发布数据,并且让系统自己能反复修改最终数据。完整性是一个非常有趣的话题,最好能用一些强有力的例子来说明,我会在下一篇分享。
总结
这篇包含太多信息了。如果你读到这里,你应该受到表扬,我们已经完成了一半了,让我们回顾下我们讲了什么,并且知道下一篇讲什么。让人高兴的是这篇无聊些,但是下一篇一定有趣。
回顾
- 澄清术语,特别是streaming的定义只限于执行引擎,而将其他术语,比如unbounded data和近似算法都放在streaming的概念下。
- 分析了设计正确的batch和streaming系统,总结出 streaming是batch的功能超集 ,Lambda架构最终会被streaming取代。
- 提出两个重要的概念,能够帮助streaming追赶并超越batch: 完整性 和 时间工具
- 列出了 event time和processing time 的关系,并且指出两个时间给我们带来的困难,根据完整性的概念,提出系统应该能够拥抱在时间上的变化,提供完整精确的结果。
- 分析了常用数据处理方法,包括bounded和unbounded数据,主要是batch和streaming引擎,并且把unbounded数据处理分成4类: time-agnostic, approximation, windowing by processing time, and windowing by event time 。
下一篇
- 从更高层面分析 数据处理 的概念,主要从4个方面入手: what, where, when, and how 。
- 详细分析如何用Dataflow Model来完成各种不同的需求。他讲帮助你更彻底的理解啥是event time和processing time,也包括一个新的概念:watermarks
- 比较现有数据处理系统,特别是一些最要的特性,让我们更好的选择他们,并且鼓励大家改善他们,帮助我实现我的最终目标:让streaming成为大数据处理的最好形式。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

