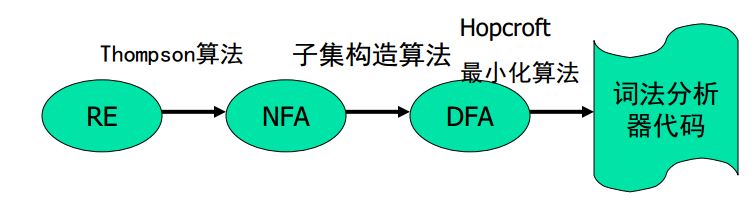
简易正则表达式引擎的实现
正则表达式基本每个程序员都会用到,实现正则表达式引擎却似乎是一个很难的任务。实际上,掌握《编译原理》前端的词法分析部分知识就能够实现一个简单的正则表达式引擎。这里推荐一下网易云课堂的课程。 http://mooc.study.163.com/course/USTC-1000002001?tid=1000003000#/info
基本的正则表达式正则表达式由字符与元字符组成,整个表达式用于描述符合某些特定特征的一类字符串,比如说表达式:abc,它表示 "abc" 这个字符串,由 'a', 'b', 'c' 三个字符按顺序连接在一起。本文要实现的正则表达式比较简单,只实现连接、选择、闭包的功能。定义直接从ppt里截图:

实现的大概步骤如下:
NFA指的是非确定自动机,对任意的字符,有多个状态可以转换。DFA指的是确定自动机,对任意的字符,最多只有一个状态可以转换。
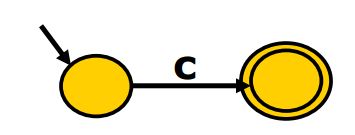
Thompson算法是一个递归算法,先将单个字符转换为nfa,再根据规则将nfa组合起来。单个字符(比如c)的转化如下
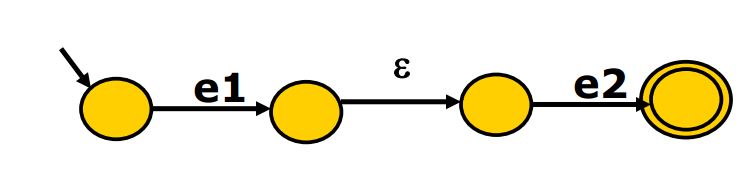
两个字符(比如e1e2)则中间用ε连接
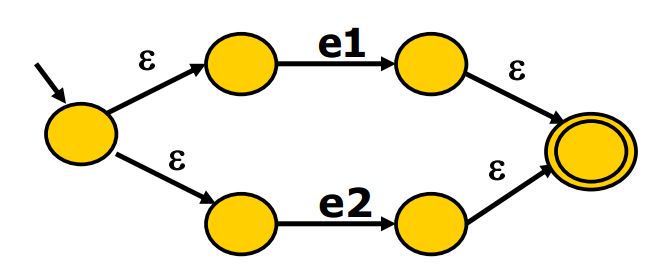
接下来是选择(比如e1|e2)
闭包(比如e1*)比较复杂

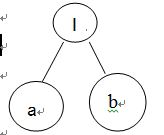
知道了如何将小的nfa组合成大的nfa,那怎么处理正则表达式,将其转换为nfa呢?我们可以像处理四则运算那样,用两个栈来解决,但这只能应对简单情况。还可以用递归下降分析构建抽象语法树,a|b的语法树如下,递归下降分析的具体做法可以看前面推荐的视频或直接看 源码
由于nfa对任意的字符,有多个状态可以转换,我们需要将其转换为dfa。我们的nfa实际上是ε-NFA,有很多ε边,而dfa是没有ε边的,所以我们可以通过子集构造算法去除这些ε边。子集构造算法的大概思路是将从状态A出发接收某个字符能到达的所有状态(包括接收字符后再通过ε边到达)构成一个子集,这个子集所能到达的所有状态又构成一个子集,到最后就能消除ε边,得到dfa。
对于下图的nfa
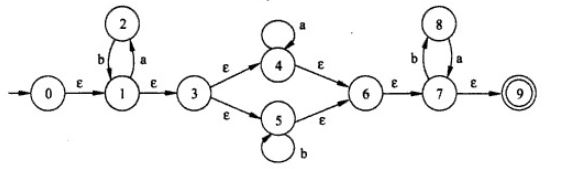
子集构造算法步骤如下

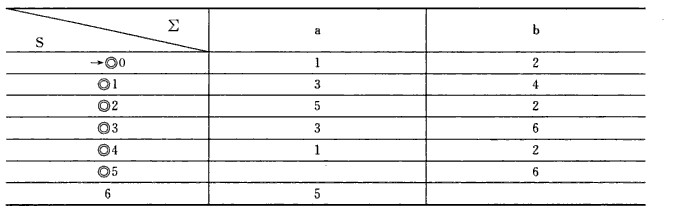
第一列第一行I的意思是从NFA的起始节点经过任意个ε所能到达的结点集合。Ia表示从该集合开始接收一个a所能到达的集合,Ib也就是接收一个b所能到达的状态的集合。
如果Ia和Ib还没出现在I,就把它们填在接下的I里。结果如下

得到dfa后再用Hopcroft算法最小化dfa,这个算法的思想是将等价的状态浓缩为一个结点。比如对于以下dfa
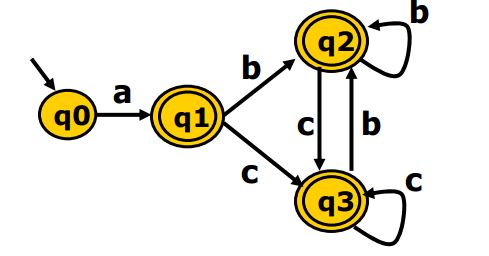
可以简化为

这样我们就完成了整个步骤,对于输入的字符串,如果能沿着dfa走到接收状态,就说明能够匹配。具体源码看 这里 可能有bug,最后的最小化dfa也没有实现,轻喷。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

