分布式系统设计系列 -- 基本原理及高可用策略
【分布式系统中的概念】
三元组
其实,分布式系统说白了,就是很多机器组成的集群,靠彼此之间的网络通信,担当的角色可能不同,共同完成同一个事情的系统。如果按”实体“来划分的话,就是如下这几种:
1、 节点 -- 系统中按照协议完成计算工作的一个逻辑实体,可能是执行某些工作的进程或机器
2、 网络 -- 系统的数据传输通道,用来彼此通信。通信是具有方向性的。
3、 存储 -- 系统中持久化数据的数据库或者文件存储。
如图
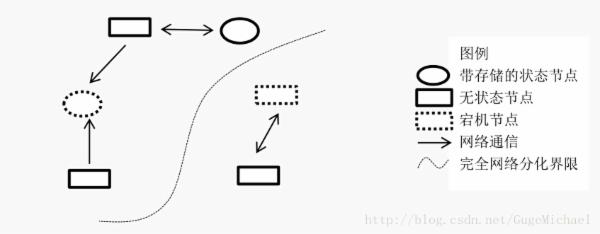
状态特性
各个节点的状态可以是 “无状态”或者“有状态的”.
一般认为,节点是偏计算和通信的模块,一般是无状态的。这类应用一般不会存储自己的中间状态信息,比如Nginx,一般情况下是转发请求而已,不会存储中间信息。另一种“有状态”的,如mysql等数据库,状态和数据全部持久化到磁盘等介质。
“无状态”的节点一般我们认为是可随意重启的,因为重启后只需要立刻工作就好。“有状态”的则不同,需要先读取持久化的数据,才能开始服务。所以,“无状态”的节点一般是可以随意扩展的,“有状态”的节点需要一些控制协议来保证扩展。
系统异常
异常,可认为是节点因为某种原因不能工作,此为节点异常。还有因为网络原因,临时、永久不能被其他节点所访问,此为网络异常。在分布式系统中,要有对异常的处理,保证集群的正常工作。
【分布式系统与单节点的不同】
1、从linux write()系统调用说起
众所周知,在unix/linux/mac(类Unix)环境下,两个机器通信,最常用的就是通过socket连接对方。传输数据的话,无非就是调用write()这个系统调用,把一段内存缓冲区发出去。但是可以进一步想一下,write()之后能确认对方收到了这些数据吗?
答案肯定是不能,原因就是发送数据需要走内核->网卡->链路->对端网卡->内核,这一路径太长了,所以只能是异步操作。write()把数据写入内核缓冲区之后就返回到应用层了,具体后面何时发送、怎么发送、TCP怎么做滑动窗口、流控都是tcp/ip协议栈内核的事情了。
所以在应用层,能确认对方受到了消息只能是对方应用返回数据,逻辑确认了这次发送才认为是成功的。 这就却别与单系统编程,大部分系统调用、库调用只要返回了就说明已经确认完成了。
2、TCP/IP协议是“不可靠”的
教科书上明确写明了互联网是不可靠的,TCP实现了可靠传输。何来“不可靠”呢?先来看一下网络交互的例子,有A、B两个节点,之间通过TCP连接,现在A、B都想确认自己发出的任何一条消息都能被对方接收并反馈,于是开始了如下操作:
A->B发送数据,然后A需要等待B收到数据的确认,B收到数据后发送确认消息给A,然后B需要等待A收到数据的确认,A收到B的数据确认消息后再次发送确认消息给B,然后A又去需要等待B收到的确认。。。 死循环了!!
其实,这就是著名的“ 拜占庭将军 ”问题:
http://baike.baidu.com/link?url=6iPrbRxHLOo9an1hT-s6DvM5kAoq7RxclIrzgrS34W1fRq1h507RDWJOxfhkDOcihVFRZ2c7ybCkUosWQeUoS_
所以, 通信双方是“不可能”同时确认对方受到了自己的信息 。而教科书上定义的其实是指“单向”通信是成立的,比如A向B发起Http调用,收到了HttpCode 200的响应包,这只能确认,A确认B收到了自己的请求,并且B正常处理了,不能确认的是B确认A受到了它的成功的消息。
3、不可控的状态
在单系统编程中,我们对系统状态是非常可控的。比如函数调用、逻辑运算,要么成功,要么失败,因为这些操作被框在一个机器内部,cpu/总线/内存都是可以快速得到反馈的。开发者可以针对这两个状态很明确的做出程序上的判断和后续的操作。
而在分布式的网络环境下,这就变得微妙了。比如一次rpc、http调用,可能成功、失败,还有可能是“超时”,这就比前者的状态多了一个不可控因素,导致后面的代码不是很容易做出判断。试想一下,用A用支付宝向B转了一大笔钱,当他按下“确认”后,界面上有个圈在转啊转,然后显示请求超时了,然后A就抓狂了,不知道到底钱转没转过去,开始确认自己的账户、确认B的账户、打电话找客服等等。
所以分布式环境下, 我们的其实要时时刻刻考虑面对这种不可控的“第三状态”设计开发,这也是挑战之一 。
4、视”异常“为”正常“
单系统下,进程/机器的异常概率十分小。即使出现了问题,可以通过人工干预重启、迁移等手段恢复。但在分布式环境下,机器上千台,每几分钟都可能出现宕机、死机、网络断网等异常,出现的概率很大。所以,这种环境下,进程core掉、机器挂掉都是需要我们在编程中认为随时可能出现的,这样才能使我们整个系统健壮起来,所以”容错“是基本需求。
异常可以分为如下几类:
节点错误:
一般是由于应用导致,一些coredump和系统错误触发,一般重新服务后可恢复。
硬件错误:
由于磁盘或者内存等硬件设备导致某节点不能服务,需要人工干预恢复。
网络错误:
由于点对点的网络抖动,暂时的访问错误,一般拓扑稳定后或流量减小可以恢复。
网络分化:
网络中路由器、交换机错误导致网络不可达,但是网络两边都正常,这类错误比较难恢复,并且需要在开发时特别处理。 【这种情况也会比较前面的问题较难处理】
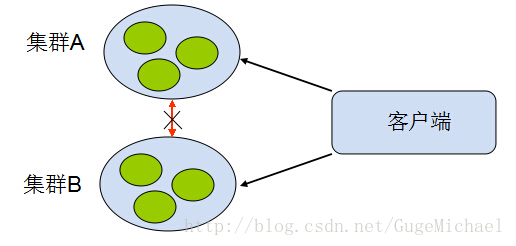
【分布式系统特性】
CAP是分布式系统里最著名的理论,wiki百科如下
Consistency (all nodes see the same data at the same time)
Availability (a guarantee that every request receives a response about whether it was successful or failed)
Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
(摘自 :http://en.wikipedia.org/wiki/CAP_theorem)
早些时候,国外的大牛已经证明 了CAP三者是不能兼得 ,很多实践也证明了。
本人就不挑战权威了,感兴趣的同学可以自己Google。本人以自己的观点总结了一下:
一致性
描述当前所有节点存储数据的统一模型,分为强一致性和弱一致性:
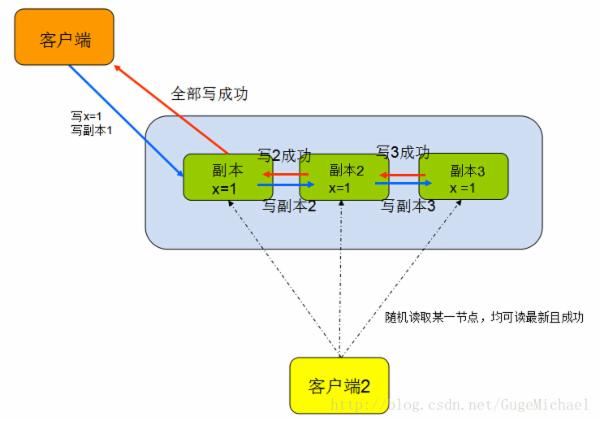
强一致性描述了所有节点的数据高度一致,无论从哪个节点读取,都是一样的 。无需担心同一时刻会获得不同的数据。是级别最高的,实现的代价比较高
如图:
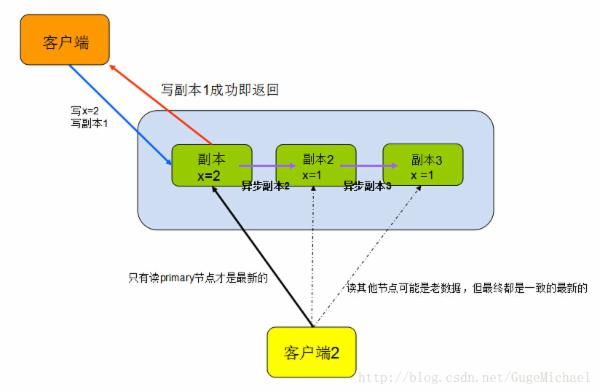
弱一致性又分为单调一致性和最终一致性:
1、 单调一致性强调数据是按照时间的新旧,单调向最新的数据靠近,不会回退 ,如:
数据存在三个版本v1->v2->v3,获取只能向v3靠近(如取到的是v2,就不可能再次获得v1)
2、 最终一致性强调数据经过一个时间窗口之后,只要多尝试几次,最终的状态是一致的 ,是最新的数据
如图:
强一致性的场景,就好像交易系统,存取钱的+/-操作必须是马上一致的,否则会令很多人误解。
弱一致性的场景,大部分就像web互联网的模式,比如发了一条微博,改了某些配置,可能不会马上生效,但刷新几次后就可以看到了,其实弱一致性就是在系统上通过业务可接受的方式换取了一些系统的低复杂度和可用性。
可用性
保证系统的正常可运行性,在请求方看来,只要发送了一个请求,就可以得到恢复无论成功还是失败(不会超时)!
分区容忍性
在系统某些节点或网络有异常的情况下,系统依旧可以继续服务。
这通常是有负载均衡和副本来支撑的。例如计算模块异常可通过负载均衡引流到其他平行节点,存储模块通过其他几点上的副本来对外提供服务。
扩展性
扩展性是融合在CAP里面的特性,我觉得此处可以单独讲一下。扩展性直接影响了分布式系统的好坏,系统开发初期不可能把系统的容量、峰值都考虑到,后期肯定牵扯到扩容,而如何做到快而不太影响业务的扩容策略,也是需要考虑的。(后面在介绍数据分布时会着重讨论这个问题)
【分布式系统设计策略】
1、重试机制
一般情况下,写一段网络交互的代码,发起rpc或者http,都会遇到请求超时而失败情况。可能是网络抖动(暂时的网络变更导致包不可达,比如拓扑变更)或者对端挂掉。这时一般处理逻辑是将请求包在一个重试循环块里,如下:
int retry = 3; while(!request() && retry--) sched_yield(); // or usleep(100)
此种模式可以防止网络暂时的抖动, 一般停顿时间很短,并重试多次后,请求成功!但不能防止对端长时间不能连接 (网络问题或进程问题)
2、心跳机制
心跳顾名思义,就是以固定的频率向其他节点汇报当前节点状态的方式。收到心跳,一般可以认为一个节点和现在的网络拓扑是良好的。当然,心跳汇报时,一般也会携带一些附加的状态、元数据信息,以便管理。如下图:
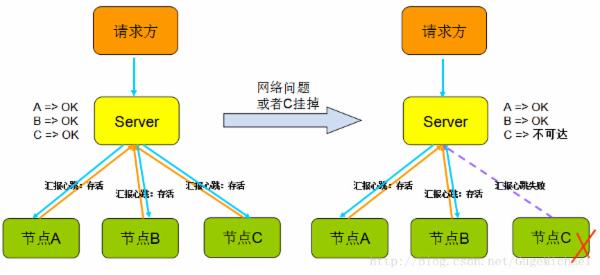
但心跳不是万能的,收到心跳可以确认ok,但是收不到心跳却不能确认节点不存在或者挂掉了,因为可能是网络原因倒是链路不通但是节点依旧在工作。
所以切记 ,”心跳“只能告诉你正常的状态是ok,它不能发现节点是否真的死亡,有可能还在继续服务。(后面会介绍一种可靠的方式 -- Lease机制)
3、副本
副本指的是针对一份数据的多份冗余拷贝,在不同的节点上持久化同一份数据,当某一个节点的数据丢失时,可以从副本上获取数据。数据副本是分布式系统解决数据丢失异常的仅有的唯一途径。当然对多份副本的写入会带来一致性和可用性的问题,比如规定副本数为3,同步写3份,会带来3次IO的性能问题。还是同步写1份,然后异步写2份,会带来一致性问题,比如后面2份未写成功其他模块就去读了(下个小结会详细讨论如果在副本一致性中间做取舍)。
4、中心化/无中心化
系统模型这方面,无非就是两种:
中心节点,例如mysql的MSS单主双从、MongDB Master、HDFS NameNode、MapReduce JobTracker等,有1个或几个节点充当整个系统的核心元数据及节点管理工作,其他节点都和中心节点交互。这种方式的好处显而易见, 数据和管理高度统一集中在一个地方,容易聚合,就像领导者一样,其他人都服从就好。简单可行。
但是缺点是模块高度集中,容易形成性能瓶颈,并且如果出现异常,就像群龙无首一样。
无中心化的设计,例如cassandra、zookeeper,系统中不存在一个领导者,节点彼此通信并且彼此合作完成任务。好处在于如果出现异常,不会影响整体系统,局部不可用。缺点是比较协议复杂,而且需要各个节点间同步信息。
【分布式系统设计实践】
基本的理论和策略简单介绍这么多,后面本人会从工程的角度,细化说一下”数据分布“、"副本控制"和"高可用协议"
在分布式系统中,无论是计算还是存储,处理的对象都是数据,数据不存在于一台机器或进程中,这就牵扯到如何多机均匀分发数据的问题,此小结主要讨论"哈希取模",”一致性哈希“,”范围表划分“,”数据块划分“
1、哈希取模:
哈希方式是最常见的数据分布方式,实现方式是通过可以描述记录的业务的id或key(比如用户 id),通过Hash函数的计算求余。余数作为处理该数据的服务器索引编号处理。如图:
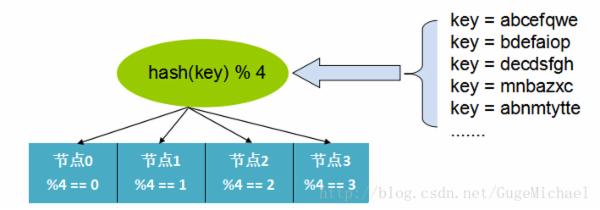
这样的好处是只需要通过计算就可以映射出数据和处理节点的关系,不需要存储映射。难点就是如果id分布不均匀可能出现计算、存储倾斜的问题,在某个节点上分布过重。并且当处理节点宕机时,这种”硬哈希“的方式会直接导致部分数据异常,还有扩容非常困难,原来的映射关系全部发生变更。
此处,如果是”无状态“型的节点,影响比较小,但遇到”有状态“的存储节点时,会发生大量数据位置需要变更,发生大量数据迁移的问题。这个问题在实际生产中, 可以通过按2的幂的机器数,成倍扩容的方式来缓解 ,如图:
 不过扩容的数量和方式后收到很大限制。下面介绍一种”自适应“的方式解决扩容和容灾的问题。
不过扩容的数量和方式后收到很大限制。下面介绍一种”自适应“的方式解决扩容和容灾的问题。
2、一致性哈希:
一致性哈希 -- Consistent Hash 是使用一个哈希函数计算数据或数据特征的哈希值,令该哈希函数的输出值域为一个封闭的环,最大值+1=最小值。将节点随机分布到这个环上,每个节点负责处理从自己开始顺
时针至下一个节点的全部哈希值域上的数据,如图:
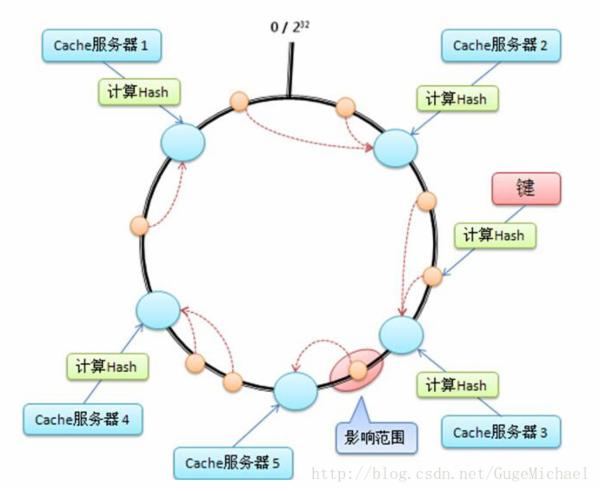
################################################3
一致性哈希的优点在于可以任意动态添加、删除节点,每次添加、删除一个节点仅影响一致性哈希环上相邻的节点。 为了尽可能均匀的分布节点和数据,一种常见的改进算法是引入虚节点的概念,系统会创建许多虚拟节点,个数远大于当前节点的个数,均匀分布到一致性哈希值域环上。读写数据时,首先通过数据的哈希值在环上找到对应的虚节点,然后查找到对应的real节点。 这样在扩容和容错时,大量读写的压力会再次被其他部分节点分摊,主要解决了压力集中的问题 。 如图:
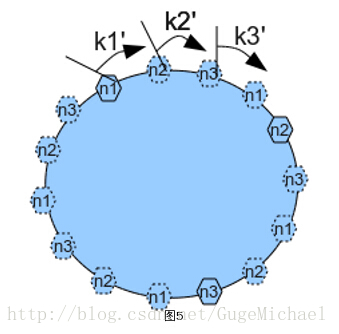
3、数据范围划分:
有些时候业务的数据id或key分布不是很均匀,并且读写也会呈现聚集的方式。比如某些id的数据量特别大,这时候可以将数据按Group划分,从业务角度划分比如id为0~10000,已知8000以上的id可能访问量特别大,那么分布可以划分为[[0~8000],[8000~9000],[9000~1000]]。将小访问量的聚集在一起。
这样可以根据真实场景按需划分,缺点是由于这些信息不能通过计算获取,需要引入一个模块存储这些映射信息。这就增加了模块依赖,可能会有性能和可用性的额外代价。
4、数据块划分:
许多文件系统经常采用类似设计,将数据按固定块大小(比如HDFS的64MB),将数据分为一个个大小固定的块,然后这些块均匀的分布在各个节点,这种做法也需要外部节点来存储映射关系。
由于与具体的数据内容无关,按数据量分布数据的方式一般没有数据倾斜的问题,数据总是被均匀切分并分布到集群中。当集群需要重新负载均衡时,只需通过迁移数据块即可完成。
如图:
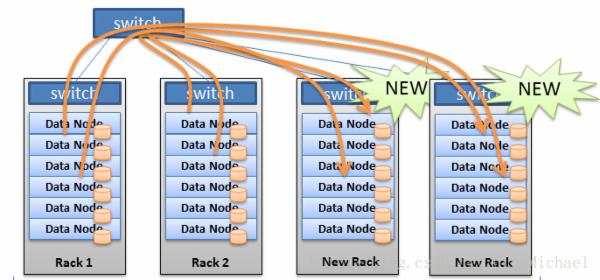
大概说了一下数据分布的具体实施,后面根据这些分布,看看工程中各个节点间如何相互配合、管理,一起对外服务。
1、paxos
paxos很多人都听说过了,这是唯一一个被认可的在工程中证实的强一致性、高可用的去中心化分布式协议。
虽然论文里提到的概念比较复杂,但基本流程不难理解。本人能力有限,这里只简单的阐述一下基本原理:
Paxos 协议中,有三类角色:
Proposer:Proposer 可以有多个,Proposer 提出议案,此处定义为value。不同的 Proposer 可以提出不同的甚至矛盾的 value,例如某个 Proposer 提议“将变量a设置为x1” ,另一个 Proposer 提议“将变量a设置为x2” ,但对同一轮 Paxos过程,最多只有一个 value 被批准。
Acceptor: 批准者。 Acceptor 有 N 个, Proposer 提出的 value 必须获得超过半数(N/2+1)的 Acceptor批准后才能通过。Acceptor 之间对等独立。
Learner:学习者。Learner 学习被批准的 value。所谓学习就是通过读取各个 Proposer 对 value的选择结果, 如果某个 value 被超过半数 Proposer 通过, 则 Learner 学习到了这个 value。从而学习者需要至少读取 N/2+1 个 Accpetor,至多读取 N 个 Acceptor 的结果后,能学习到一个通过的 value。
paxos在开源界里比较好的实现就是zookeeper(类似Google chubby),zookeeper牺牲了分区容忍性,在一半节点宕机情况下,zookeeper就不可用了。可以提供中心化配置管理下发、分布式锁、选主等消息队列等功能。其中前两者依靠了Lease机制来实现节点存活感知和网络异常检测。
2、Lease机制
Lease英文含义是”租期“、”承诺“。在分布式环境中,此机制描述为:
Lease 是由授权者授予的在一段时间内的承诺。授权者一旦发出 lease,则无论接受方是否收到,也无论后续接收方处于何种状态,只要 lease 不过期,授权者一定遵守承诺,按承诺的时间、内容执行。接收方在有效期内可以使用颁发者的承诺,只要 lease 过期,接
收方放弃授权,不再继续执行,要重新申请Lease。
如图:
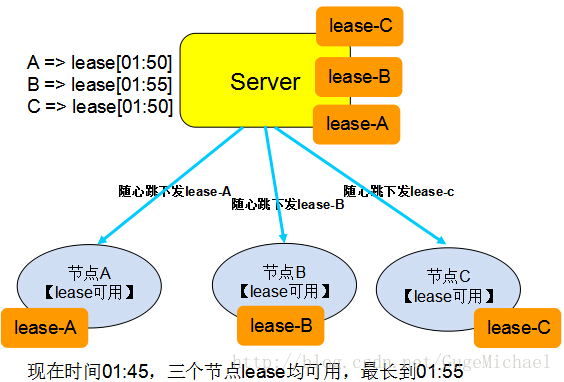
Lease用法举例1:
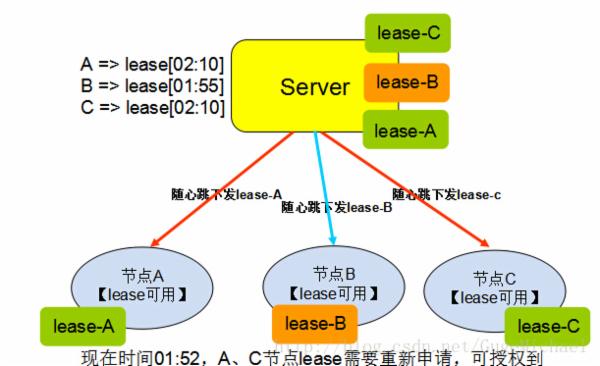
现有一个类似DNS服务的系统,数据的规律是改动很少,大量的读操作。客户端从服务端获取数据,如果每次都去服务器查询,则量比较大。可以把数据缓存在本地,当数据有变动的时候重新拉取。现在服务器以lease的形式,把数据和lease一同推送给客户端,在lease中存放承诺该数据的不变的时间,然后客户端就可以一直放心的使用这些数据(因为这些数据在服务器不会发生变更) 。如果有客户端修改了数据,则把这些数据推送给服务器,服务器会阻塞一直到已发布的所有lease都已经超时用完,然后后面发送数据和lease时,更新现在的数据 。
这里有个优化可以做,当服务器收到数据更新需要等所有已经下发的lease超时的这段时间,可以直接发送让数据和lease失效的指令到客户端,减小服务器等待时间,如果不是所有的lease都失效成功,则退化为前面的等待方案(概率小)。
Lease用法举例2:
现有一个系统,有三个角色,选主模块Manager,唯一的Master,和其他salver节点。slaver都向Maganer注册自己,并由manager选出唯一的Master节点并告知其他slaver节点。当网络出现异常时,可能是Master和Manager之间的链路断了,Master认为Master已经死掉了,则会再选出一个Master,但是原来的Master对其他网络链路可能都还是正常的,原来的Master认为自己还是主节点,继续服务。这时候系统中就出现了”双主“,俗称”脑裂“。
解决这个问题的方式可以通过Lease,来规定节点可以当Master的时间,如果没有可用的Lease,则自动退化为Slaver。 如果出现”双主“,原Master会因为Lease到期而放弃当Master,退化为Slaver,恢复了一个Master的情况。
3、选主算法
有些时候出于系统某些特性,可以在有取舍的情况下,实现一些类似Lease的选主的方案,可见本人另一篇文章:
正文到此结束
- 本文标签: key db 互联网 自适应 支付宝 需求 Nginx 总结 负载均衡 apr 删除 交易系统 消息队列 node 压力 同步 配置 代码 web 锁 DNS Namenode http 数据 Cassandra unix 进程 微博 map message Google mysql 开发 网卡 HDFS core 开发者 TCP 协议 开源 数据库 sql Job 管理 linux value ip 集群 src UI 时间 服务器 性能问题 zookeeper 文章 领导
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

