Spark迷思
标签: spark 迷思 | 发表时间:2016-03-27 11:28 | 作者:
出处:http://www.iteye.com
目前在媒体上有很大的关于Apache Spark框架的声音,渐渐的它成为了大数据领域的下一个大的东西。证明这件事的最简单的方式就是看google的趋势图:
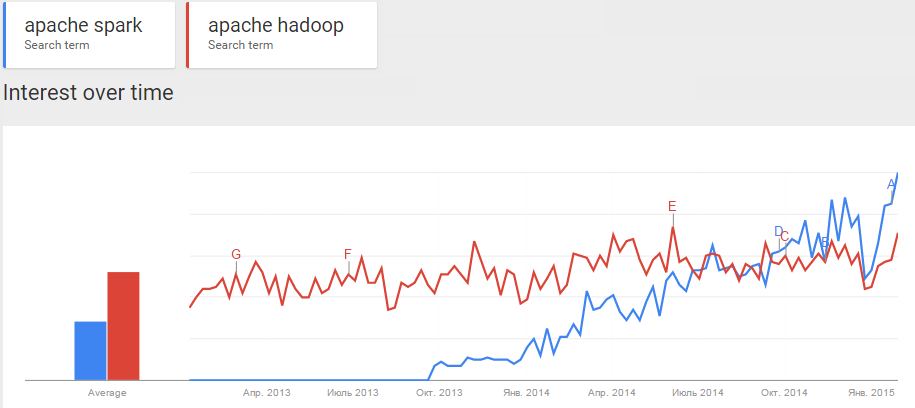
上图展示的过去两年Hadoop和Spark的趋势。Spark在终端用户之间变得越来越受欢迎,而且这些用户经常在网上找Spark相关资料。这给了Spark起了很大的宣传作用;同时围绕着它的也有误区和思维错误,而且很多人还把这些误区作为银弹,认为它可以解决他们的问题并提供比Hadoop好100倍的性能。
这篇文章将为希望在自己系统接入Spark的技术员们讲解大家对它的一些主要误区。我要说的是这些误区主要是源于市场上一些专家的谣传和过度简单化。Spark的文档也很清楚了反驳了这些专家的观点,但是需要我们去大量阅读。因此,下面我所提到的 误区 主要包括以下几个方面:
- Spark是一项基于内存的技术
- Spark的执行速度比Hadoop快10到100倍
- Spark在市场上引入了一种全新的数据处理方式

排在第一位的也是最重要的误区是Spark是一项“基于内存”的技术。不是的,从来没有任何一个Spark开发者官方的声明过这种特性。这是基于对Spark计算过程的误解。
但是这里让我们回到开始的问题。到底什么样的技术才能称之为内存技术?我认为是能够允许我们将数据存储在内存中并有效处理这些数据的技术。而我们在Spark中看到了什么?它并没有选项可以让我们将数据存放在内存中;虽然Spark有可插拔式的连接器可以连接到很多持久化存储系统HDFS、Tachyon、HBase、Cassandra等等,但是就是没有自带将数据存储到内存或者硬盘上的代码。而它所能做的只是缓存数据而不是持久化数据;缓存数据是很容易会被通过连接器连接的数据源删除或者更新的。
其次,有些人针对我们以上的观点抱怨说,Spark是在内存中处理数据的啊。当然是在内存中处理,因为你没有选择来使用其他方式来处理数据;所有在OS API上的操作都只是允许我们将数据从块设备上加载到内存中或将内存中的数据卸载至块设备上。我们不能直接使用HDD而不将HDD上的数据加载到内存中,所以现代操作系统上的所有数据处理都是在内存中进行的。
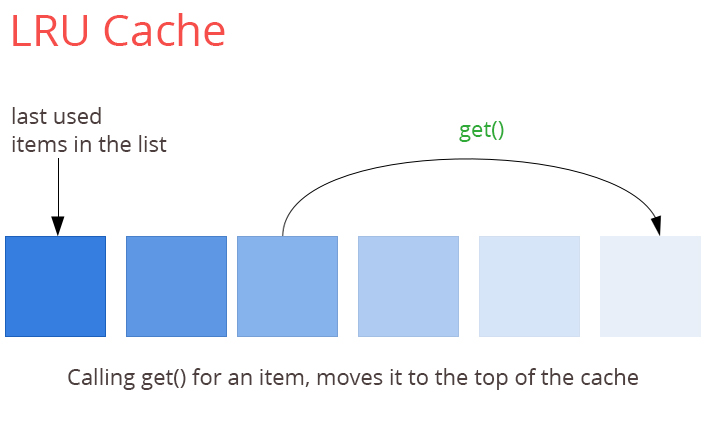
事实上,Spark对于内存缓存允许我们使用LRU(最近最少使用)回收算法。您可能仍然认为它是基于内存的技术,至少我们在处理数据时它是在内存中的。但是让我们再看看RDBMS(关系型数据库系统)市场,这里举两个例子:Oracle和PostgreSQL。你认为它们是怎么处理数据的?它们使用共享内存段来作为表page内存池,而且所有的数据读写都是有这个内存池服务的,而且这个内存池也是使用LRU规则来释放并不是脏数据的表page内存(而且如果有太多脏的page时会出发检查点来处理)。所以总的来说,现代数据库也利用基于内存的LRU算法来满足它们的需求。那么为什么我们不说Oracle和PostgreSQL为基于内存的数据库呢?还有就是关于Linux IO,你知道所有传递给操作系统的IO操作的缓存也同样是基于LRU的缓存吗?
甚至,你知道Spark在内存中处理所有transformation吗?你可能感到很失望,Spark的核心“shuffle”会将数据写入磁盘中,如果我们在我们的Spark SQL语句中使用了group by语句或者我们刚刚讲RDD转换为PairRDD并且通过键来调用聚合操作,那么我们正在强制Spark将数据根据key的哈希值分发到各个数据节点。Shuffle处理包含两个阶段,就是通常所说的“map”和“reduce”:“map”阶段仅仅计算key的哈希值(或者是自定义的其他分割函数)并将结果输出N个单独的文件到本地磁盘上,其中N就是“reudce”端的分区数;“Reduce”端拉取“map”端的计算结果并将其合并新的分区,因此如果我们的RDD有M个分区,则我们将它转换为一对RDD时会在集群中生成M*N个文件,这些文件包含RDD中的所有数据;有一些优化手段可以减少生成的文件数量;此外还有一些工作来预排序这些文件并且在“reduce”端“合并”这些文件,但这并不能改变如果我们想要处理数据就得将数据放入HDD的事实。
所以,Spark并不是一项基于内存的技术。这是一项可以让我们有效的利用基于内存的LRU方法在内存存满时将数据卸载至硬盘中;而且它没有内置持久化功能(内存、硬盘都没有),它会在shuffle过程中将所有数据放到本地文件系统中。
下一个误区是“Spark执行速度比Hadoop快10到100倍”。这里我们引用一篇早先发表的文章: http://laser.inf.ethz.ch/2013/material/joseph/LASER-Joseph-6.pdf 。这篇文章声称Spark的目标是支持迭代的任务,典型的机器学习。但是如果我们参考Apache网站上Spark的主页时就会再次发现一个让我们眼前一亮的例子:
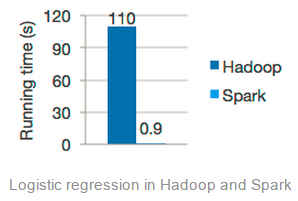
此外,上图中这个例子是关于机器学习算法“logistic回归分析”的。那么什么是机器学习中最主要的部分呢?那就是在同一个数据集上的多次的反复迭代。而这里正是Spark的内存中缓存LRU算法的真正亮点;当我们反复的连续多次扫描同一组数据时,我们只需要在第一次使用这些数据的时候才去读取它,其后都是从内存中读取这些数据,这种做法真的很好;但不幸的是,他们用比较奇怪的方式来运行这些脚本:虽然在Hadoop上运行这些脚本但却没有使用HDFS的缓存功能( http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/CentralizedCacheManagement.html) 。当然他们没有义务一定要这样去做,但是我认为就是这个不同会导致性能下降3到4倍(更高效的实现方式是不将中间数据放入HDD,这样任务启动更快)。

压力测试在企业领域的悠久历史教会了我一件事:从来不要相信压力测试。对于任何两个有竞争关系的系统我们都能找到一系列例子来证明系统A比系统B快,同样也能找到很多文章来证明系统B比系统A快。我们所能相信的(当然也要保持怀疑态度)的是独立的第三方压测工具,如TCP-H;因为它们是独立的,所以会覆盖尽可能多的场景来展示真实的性能情况。
总的来说,Spark比Hadoop快主要是因为:
- 任务启动更快。Spark使用线程,而MR则重新启动了新的JVM。
- Shuffle阶段更快。Spark在shuffle期间仅仅将数据放入HDD一次;而MR做了两次。
- 工作流更快。传统的MR工作流是一系列MR job,每个job在迭代时都会讲数据存入HDFS;而Spark支持DGA和管道操作,这样就可以让我们执行复杂的工作流而不用将中间数据持久化(除非要进行shuffle)。
- 缓存。对于这点持怀疑态度,因为目前HDFS也可以使用缓存,但总的来说Spark缓存还是非常好的,尤其是它的SparkSQL部分会将数据缓存在面向列的表单中。
以上所有这些使得Spark性能比Hadoop要好,对运行时间比较短的任务来说能达到Hadoop的100倍;但在真实的生产环境中不会超过2.5到3倍。
最后的一个被很少提及的误区是:“Spark在市场上引入了一种全新的数据处理方法”。事实上,Spar没有引入任何新的改革。虽然他们在实现高效的LRU缓存和pipeline上的想法很好,但他们并不是前无古人的。如果我们打开思维去思考这个问题,我们可能会发现所实现的几乎和早先MPP数据库中所引入的概念完全一样:查询的管道式执行、没有中间数据会持久化、对表的页数据进行LRU缓存。如你所见,Spark的核心和其之前的技术并没有不同。当然,有一个很大的进步就是Spark用开源的方式实现了这些,并且通过互联网社区免费提供给了用户,而对于企业来说可以在不降低性能的前提下不用再去支付企业级的MPP技术费用。
最后,我建议大家不要相信我们从媒体上所听到的任何事情;相信相关方面的技术专家,他们通常是我们最好的提问者。
1. 本文由程序员学架构翻译
2.原文地址:http://0x0fff.com/spark-misconceptions/
2. 转载请务必注明本文出自:程序员学架构(微信号: archleaner )
3. 更多文章请扫码:

ITeye推荐
- —软件人才免语言低担保 赴美带薪读研!—
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

