有赞统一日志平台初探
【编者的话】从2015年初入职有赞以来,一直致力于后端服务开发,主要设计开发了监控系统Hawk,但这不是本次要分享的点。一个月前,负责日志平台Track的小伙伴寻求梦想出去创业了,有幸接手了日志平台,这对本人确实是个不小的挑战,也同样是个学习成长的机会。此次就借着梳理日志平台的机会,给大家分享一下有赞统一日志平台的架构设计。 一、引言
自有赞成立以来,发展迅猛,业务增长很快,业务系统数量大,每天都会产生大量的系统日志和业务日志(据统计,平均每秒产生日志1.1万条,峰值1.5万条,每天的日志量约9亿条,占用空间2.4T左右)。
在信息化时代,日志的价值是无穷的。为了对系统进行有效的监控、维护、优化、改进,都离不开对日志的收集和分析,而这些日志散落在各个服务器上,无论对运维同学、还是业务开发同学,抑或是数据部门的同学而言,查阅或分析日志是一大痛点,实时收集分布在不同节点或机器上的日志,供离线或在线查阅及分析来提升工作效率的需求异常迫切,在此背景下,于是有赞统一日志平台就应运而生了。
在互联网高速发展的今天,有那么多优秀的日志收集系统,诸如Kafka、Flume、Scribe、Chukwa、ELK等。对于如何选型在此不做讨论,而且本人才疏学浅,也未做深入调研和性能分析对比测试,还不够资格讨论。相信前人的选择是有其理由的,接下来我们来看看秉着“短平快”的互联网精神,构建的这套适合有赞业务系统的统一日志平台。
二、总体设计
废话不多说,直接上总体架构图,如图2-1所示: 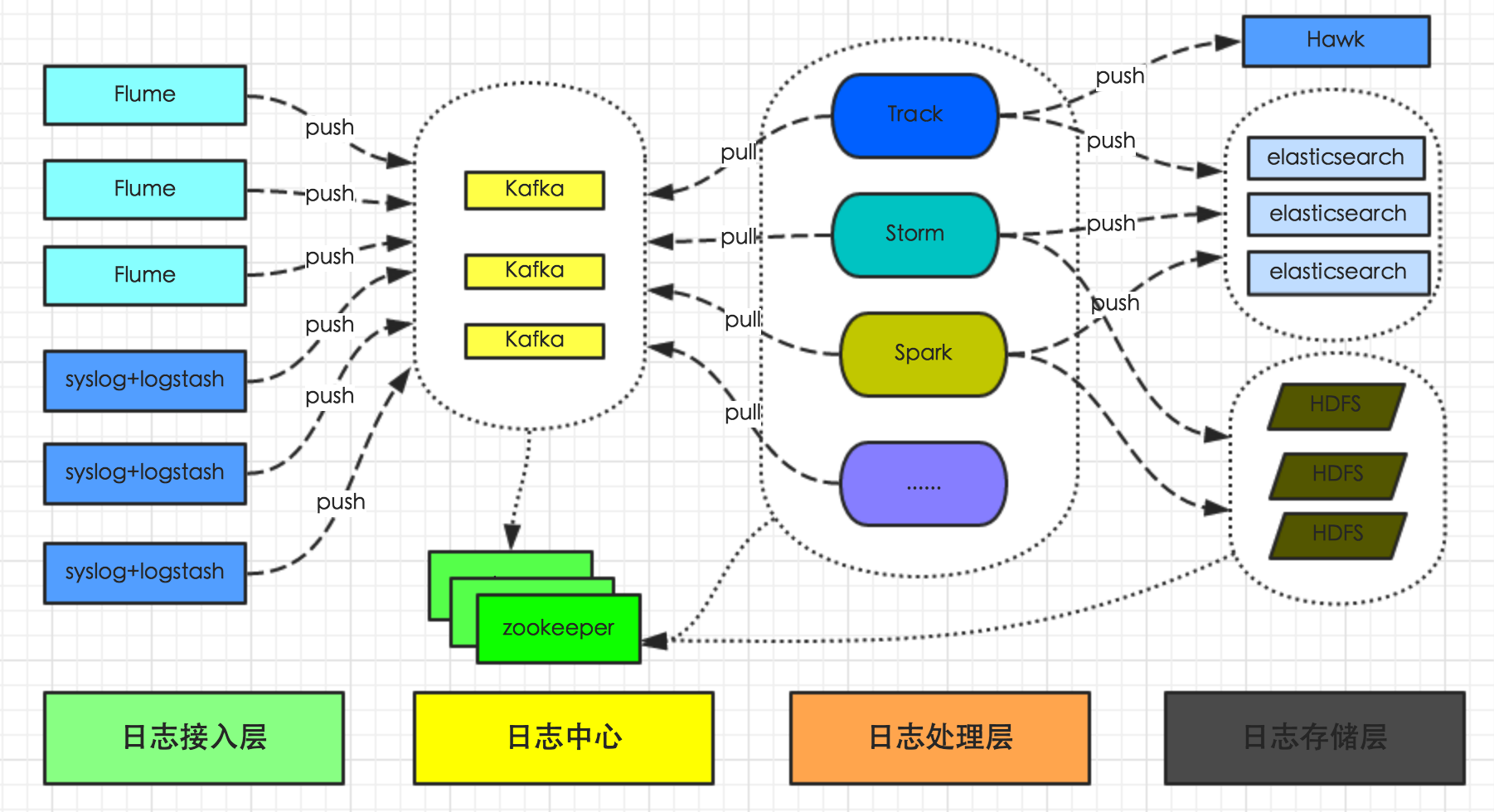 图2-1 总体架构图
图2-1 总体架构图
有赞统一日志系统,负责收集所有系统日志和业务日志,转化为流式数据,通过flume或logstash上传到日志中心(kafka集群),然后供Track、Storm、Spark及其它系统实时分析处理日志,并将日志持久化存储到HDFS供离线数据分析处理,或写入ElasticSearch提供数据查询,或写入Hawk发起异常报警或提供指标监控查询。
三、模块分解
从上面总体架构图中,我们可以看到整个日志平台架构分为四层,从左到右依次是日志接入层、日志中心、日志处理层、日志存储层。
3.1 日志接入层
日志接入层主要有两种方式,方式1基于rsyslog和logstash,方式2基于flume-ng。
3.1.1
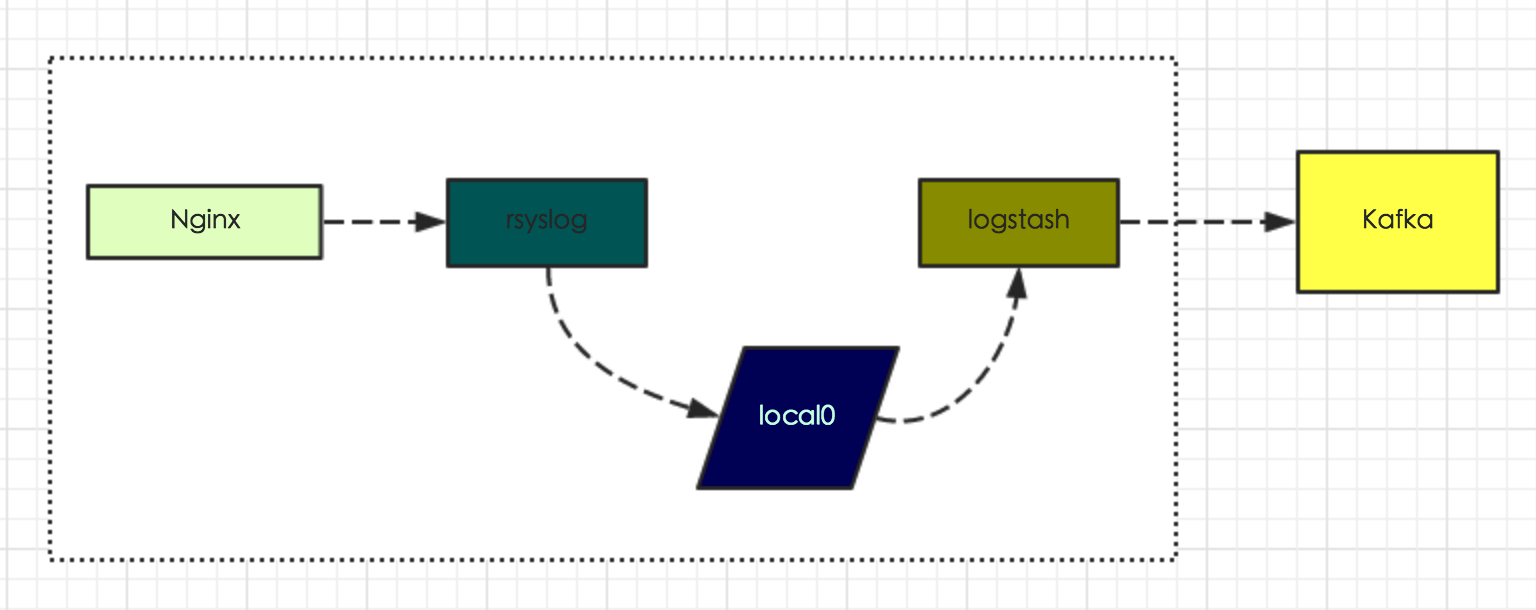 图3-1 日志接入方式1
图3-1 日志接入方式1
对于一些稳定的日志,比如系统日志或框架日志(如nginx访问日志、phpfpm异常日志等),我们添加nginx配置,通过rsyslog写到本地目录local0,然后logstash根据其配置,会将local0中的增量日志上传到日志中心对应的topic中,具体数据流图见图3-1所示:
3.1.2
Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中。轻量,配置简单,适用于各种日志收集,并支持Failover和负载均衡。并且它拥有非常丰富的组件。Flume NG采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和Sink,三者组建了一个Agent。三者的职责如下所示:
Source:用来消费(收集)数据源到Channel组件中,简单说就是搜集数据的入口。
Channel:中转临时存储,保存所有Source组件信息,其实就是个消息队列,可配置多个Chanel。
Sink:从Channel中读取,读取成功后会删除Channel中的信息,简单说就是搜集数据的出口。
在有赞日志平台中,我们只用了Agent层。具体可以见图3-2:
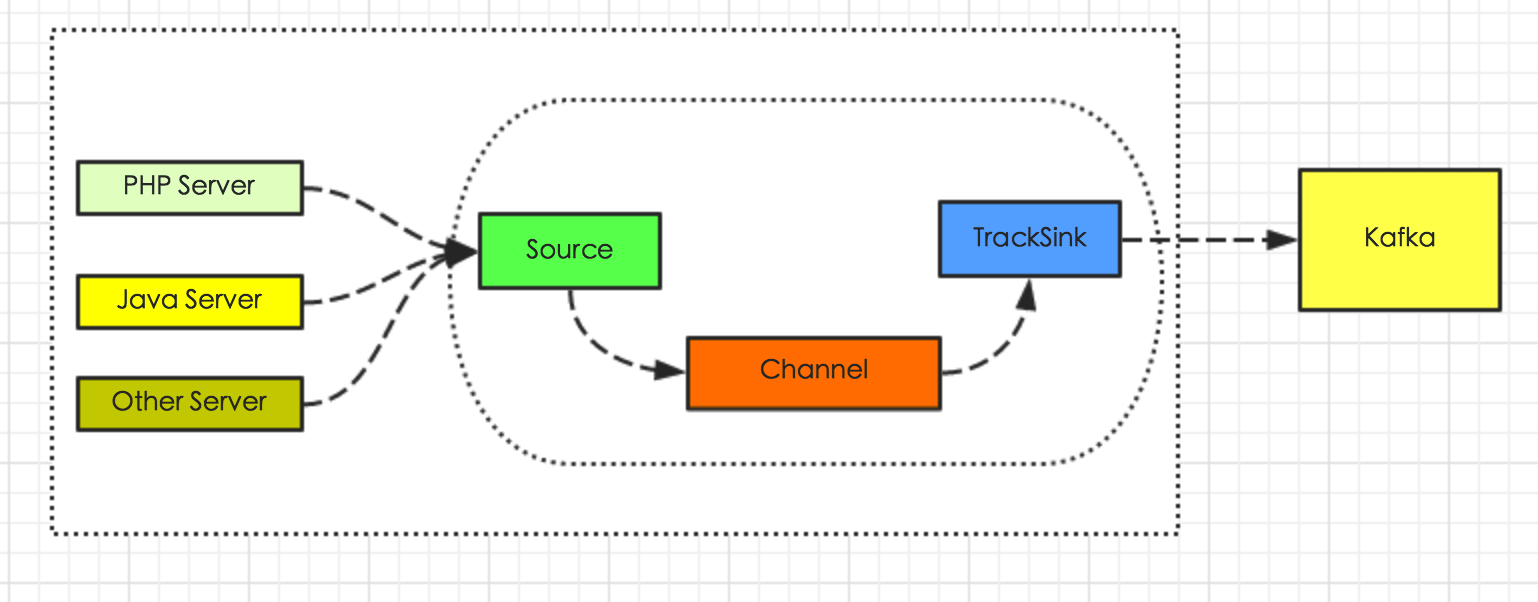
图3-2 日志接入方式2
日志中心的kafka是根据topic存取数据的,所以需要在日志中加入topic字段。为了统一,我们对日志格式做了约定,格式如下:
<158>yyyy-MM-dd HH:mm:ss host/ip level[pid]: topic=track.**** {"type":"error","tag":"redis connection refused","platform":"java/go/php","level":"info/warn/error","app":"appName","module":"com.youzan.somemodule","detail":"any things you want here"} 对于PHP Server,我们在PHP框架中封装了日志SDK,PHP开发的同学只需调用写日志接口,就可以将日志传到Flume中。同样的,对于Java Server,也封装了日志SDK(基于logback自定义了 TrackAppender ),并集成在Dubbox框架中,业务开发的同学只需在其工程的logback.xml中添加相应的appender配置,指明应用名和日志topic即可将日志异步传到Flume中。对于其它应用或服务(比如基于Go、Node.JS、Python等),如果需要接入日志平台,只需按照以上日志格式组装日志,并将其上传到Flume即可。
细心的同学会发现,在图3-2中,我们用了 TrackSink ,这个是做什么的呢?虽然Flume自带丰富的组件,也包括KafkaSink,但是为什么我们不用呢?考虑到自带的KafkaSink不能按我们需要的topic来分发数据,所以只能自定义实现了Sink来达到写不同topic日志到不同日志中心topic中去的目的。
另外,Flume是通过Supervisor启动的,并且添加了监控报警,但是为了避免日志写失败,在Flume中,我们使用了Failover策略,假如写日志中心失败,则将日志写到本地,保证日志不丢失。
3.2 日志中心
美其名曰日志中心,但实际上只是日志中心缓存,我们只保存最近24小时的日志,需要持久化的日志都会刷入HDFS。至于为什么选用kafka集群来构建日志中心,理由主要如下:
1、分布式架构,可支持水平扩展。 2、高吞吐量,在普通的服务器上每秒钟也能处理几十万条消息(远高于我们的峰值1.5万条/秒)。 3、消息持久化,按topic分区存储,支持可重复消费。 4、日志系统不需要保证严格的消息准确性。 5、数据在磁盘上的存取代价为O(1)。 6、可根据broker配置定期删除过期数据。 3.3 日志处理层和日志存储层
日志处理层,是我们真正做事的地方;日志存储层,则是我们存放日志分析结果的地方。
基于日志中心,可做的事情有很多。只要我们对某topic日志感兴趣,那么便可以将该topic日志消费来满足我们的业务需求。我们可以:
1、将日志聚合,根据业务不同,建立不同的索引,存入ElasticSearch提供查询。 2、发现异常日志时,发往监控中心,向对应的业务方发起报警,发现和预发问题的实时性提高了。 3、统计一些访问日志或调用日志等指标信息,发往监控中心来掌握相关调用趋势。 4、调用链开始做起来了,系统性能瓶颈一目了然了。 5、用户日志行为可分析了。 这里我们做了不少,但是需要做的还有更多,就不一一例举了。
四、遇到的问题和要做的事情
突然接手如此规模的一个基础产品,遇到的问题还是比较多的:
1、业务日志接入,每一次对接不仅需要开发日志消费模块,解析相应日志,建立相应的索引并写入elasticsearch,还需要开发对应定制的查询页面。由于自己本身对系统不熟悉,另外文档缺失,以及每一次对接的都是“新人”,还时不时可能会遇到各种千奇百怪的问题,需要排查定位并解决问题。这块急需解放,不然一个人真的忙不过来,针对该问题,接下来会抽象出日志消费和elasticsearch读写SDK,供业务接入方自己开发和维护。 2、对于各个组件(如logstash、flume、kafka、elasticsearch等)都未曾接触过的情况下,短时间接手这么一个新产品,需要学习的东西很多,压力还是很大的,但总算熬过来了。 3、缺失的开发测试环境,到写此文章时总算搭建起来了。 4、elasticsearch内存占用高,以及索引的管理与维护,还在优化和考虑中。 5、需要开发更加人性化且更易扩展和维护的运控平台供使用方查询日志。 6、日志收集到Flume增加支持UDP协议。 7、将存储层的HDFS移到日志中心,支持日志同时写入Kafka集群和HDFS集群。 8、是时候做点日志挖掘的事情了。 五、结语
为什么做这次分享?
由于之前交接时间较短,实际只有2天,然后统一日志平台涉及的内容比较多,接手日志平台的这一个多月是痛苦的,然后找崔(有赞CTO)吐槽了一下。结果崔知道我在梳理日志平台,就让我顺便写篇介绍有赞的日志架构的文章,帮助大家了解一下。怎奈我这人脸皮太薄,在对日志平台还不熟悉的情况下,竟然应承下来了,俗话说的好,死要面子活受罪。
最后,好像不做点广告都对不起人民大众,热烈欢迎优秀程序员加我有赞大家庭,无论前端后端,只要想做事会做事就行。有意者请猛戳:加入我们
正文到此结束
热门推荐








相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

