用Docker和Kubernetes将MongoDB作为微服务来运行
想要在你的手提电脑上尝试MongoDB吗?执行一个命令,然后拥有一个轻量级,独立的沙箱;再执行一个命令,删除你完成之后所有的痕迹。是不是需要一个在多个环境中都跟你的应用程序堆栈一样的应用程序?创建一你自己的容器镜像,然后让你的开发,测试,操作和支持团队搭建一个跟你环境完全一样的克隆版本。
容器正在彻底改革整个软件生命周期:从最早的技术实验到贯穿开发,测试,配置到版本支持的概念验证。
编排工具是管理多个容器如何被创建、如何升级、如何发挥高可用性的。编排工具也可以控制多个容器之间的连接关系来达到 用多个容器来搭建一个复杂的应用的效果。
齐全的功能,简单的工具和强大的API令容器和编排功能成为运维团队的最爱,运维团队将这些功能整合到持续集成(CI)和持续交付(CD)工作流程之中。
这篇帖子深入研究了当你们尝试在容器中运行和编程MongDB时所面临的挑战,然后阐述了这些挑战如何克服。
MongoDB注意事项
用容器和编排工具运行MongoDB介绍了一些额外注意事项:
MongoDB数据库是有状态的。在容器运行失败,并且重新调度之后,数据丢失是不合需要的(可以通过从replica set中的其他节点恢复数据,但是需要耗费时间)。为了解决这个问题,Kubernetes中的数据卷这种抽象功能就可以被用来映射在容器中原本是MongoDB数据目录,变成了一个持久数据目录位置,在这个位置,数据的存活比容器运行失败、重新调度要长。
在副本集合中的MongoDB数据库节点必须要互相交流——重新调度之后也要交流。在副本集合之中的所有节点必须知道他们所有的peers,但是当一个容器重新调度之后,它很可能会用不同IP地址重新启动。比如,所有在一个Kubernentes pod里面的容器共享一个IP地址,pod一旦重新调度,这个IP地址也会改变。有了Kubernetes,这个现象就可以通过将每个MongoDB与Kubernetes Service关联来解决,使用的是Kubernetes DNS Service来为通过重新调度保持不变的servi ce提供hostname。
一旦但个MongoDB节点在运行(每个都在自己的容器中),副本集合必须要初始化,而且每个节点都要添加。这大概就需要一些额外的逻辑性来提供现成的编制工具。尤其,在intended副本集合中,一个MongoDB节点必须被用来执行rs.initiate和rs.add命令。
如果编制框架提供自动的容器重调度(如同Kubernetes一样),那么这就能够增加MongoDB的弹性,因为运行失败的副本集合构建可以自动重新创建,因此可以实现恢复完整的冗余控制水平无需任何人工干预。
值得注意的是,编制工具可能监控容器的状态的同时,也可能监控在容器内运行的应用程序,或者备份他们的数据。这就意味着使用强大的监控功能,备份像MongoDB Cloud Manager解决方法都是不可能的,包括使用Mongo DB Enterprise Advanced也是不可能的。考虑一些创建自己的镜像,镜像可以包括自己喜欢包括MongoDB和MongoDB自动化代理的版本。
使用Docker和Kubernetes实现MongoDB副本集合
在之前的小节也讲过,像MongoDB 这样的分布式数据库,在使用像Kubernetes这样的编制框架时,需要一些额外的警示。这个小节会讲到下个层次的细节,展示如何实施。
我们从在单个Kubernetes集群中创建整个MongoDB副本集合开始(这个正常的话,会在单个的数据中心——不会提供地理性备援)事实上,基本上不会有被改变到在多个集群上面运行的,这些步骤之后会讲到。
每个副本集合的构件都将作为自己的pod被运行,伴随着暴露外部IP地址和端口的服务。这个“固定的”(fixed)IP地址十分重要,因为外部应用程序和其他副本集成构件可以在pod重新调度的时候保持不变,继续依赖它。
下图阐述了这些pods之中的一个,以及相关的Replication Controller和service。
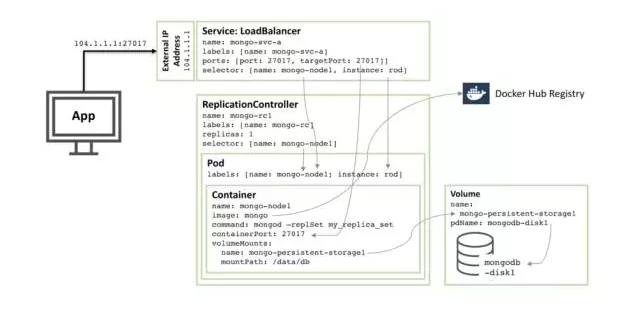
逐步通过描述的资源配置,我们有:
从核心开始,这里有叫做mongo-node1的单个容器,mongo-node1包含了一个叫做 mongo的镜像,它就是在Docker Hub上面集群的公开的MongoD B容器镜像。容器在集群里面暴露端口27107。
Kubernetes 数据卷功能被用来在映射 /data/db目录,在连接到叫做mongo-persistent-storage1持久性数据元素;这些依次都是映射到一个创建在Google Cloud 的叫做mongodb-disk1的磁盘里的。这就是MongoDB存储数据的地方,这样,它就会被保存到容器中重新调度。
容器被保存在一个pod中,这个pod上有个标签标着它自己的名字 mongo-node,而且它还提供名字叫做rod的实例。
名字叫做mongo-rc1的Replication Controller被配置用来确保mongo-node1pod的单个实例是一直在运行的。
名字叫mongo-svc-a的 LoadBalancerservice暴露了一个IP地址到外界,还暴露了27017 借口,这个接口可以在容器中被mapped到同一个容器的接口数字。Service使用选择器来识别正确pod匹配pod的标签。外部IP地址和接口会被用于应用程序,以及用于副本集成之间的交流。每个容器都有本地IP地址,但是这些IP地址会在容器被移动或者重新启动的时候改变,而使用副本集合就不会。
下一张图展示了副本集合的第二个构件。
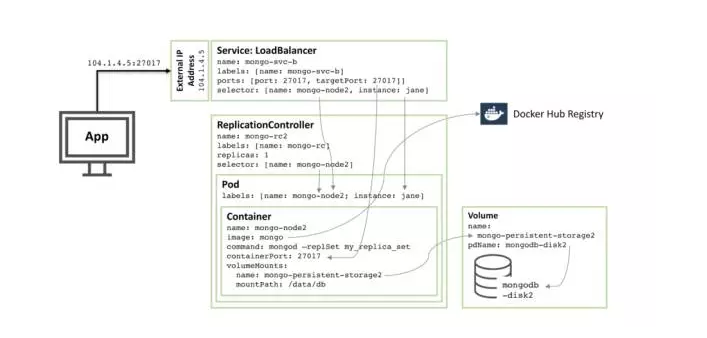
90%的配置都是一样的,只有这些改变了:
磁盘和数据卷名字必须是唯一的,这样mongodb-disk2和mongo-persistent-storage2会被使用。
pod被用来设置instance: jane和 name:mongo-node2的标签,这样新的service就可以从图1中的rodPod区别它(通过选择器)。
Replication Controller被命名为mongo-rc2
Service被命名为mongo-svc-b ,并且有一个唯一的,外部IP地址(在这个实例中,Kubernetes被赋值104.1.4.5)。
第三个副本集合构件也是相同的模式,下图就展示了完整的副本集合:
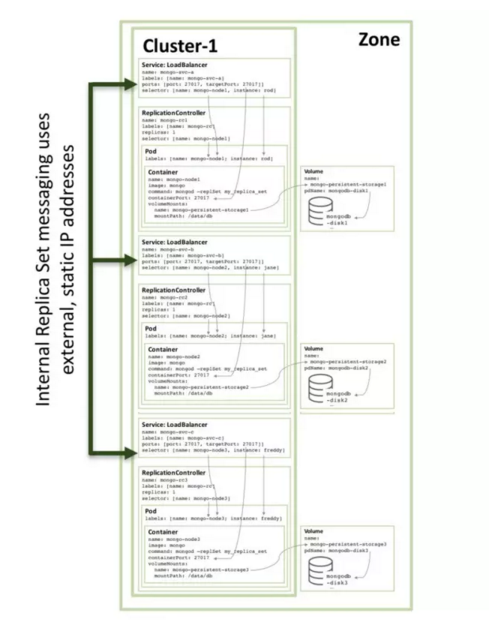
注意,即使在3个或者更多节点的Kubernetes集群上运行像图3所示的配置,Kubernetes可能(通常都会)会调度两个或者更多的MongoDB副本集合构件在同一个主机上。这是因为Kubernetes讲这三个节点看成三个独立的service了。
为了增加冗余(在zone里面),一个额外的headless service被创建。新的service没有提供新的性能来通知Kubernetes说,那三个MongoDB pods来自同一个service,所以KUbernetes尝试在不同的节点上调度他们。
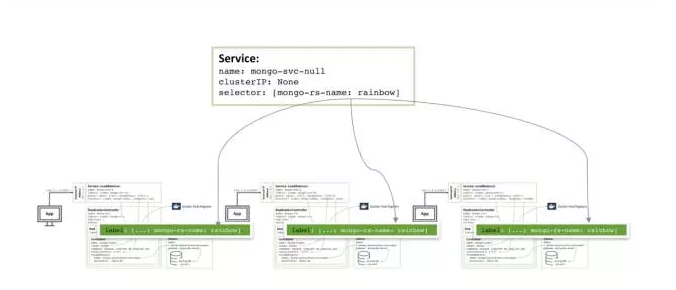
真实的需要编制和开启MongoDB的副本集合的配置文件和命令行可以点击这里查看: https://www.mongodb.com/collat ... ained 。特别是,有些特殊的步骤要求将三个Mongo DB实例组合到一个运行的,强健的副本集合,这个的话,已经在论文中讲了。
多个可用性区域 MongoDB副本集合
所有东西都在同一个GCE集群里面运行,所以副本集合创建的上述东西也还是伴随着风险的,在同一个可用区域也是一样的道理。假设有一个重大事故发生,可用区域离线了,那么MongoDB副本集合就不可用了。如果需要地理性备援,那么那三个pods就应该在三个不同的可用性地带或者区域运行。
令人吃惊的是,为了分别在三个区域内创建相似的副本集合,几乎不需要改变什么——这就要求三个集群。每个集群都需要各自的KubernetesYAML文件,这个文件只定义了pod,Replication Controller和service作为副本集合的一个构件。然后为每个区域都创建一个集群,持久性数据和MongoDB。
下一步
为了了解更多关于容器和编制——两者涉及的技术,以及他们交付的业务利益——阅读这篇论文: https://www.mongodb.com/collat ... ained 就是跟上文提到的那篇论文,在如何get到副本集合上以及在GCE上运行Docker和Kubernetes上提供指导。
加入我们的网络研讨会,一起讨论如何用Docker,Kubernetes和MongoDB来实施微服务,了解更多关于这个话题的东西。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

