新浪微博混合云架构实践挑战之镜像分发实战
相信大家通过前面几篇的介绍,对微博DCP系统的架构已经有了一些了解,今天我们来聊一聊微博混合云在镜像分发方面的一些实践经验。
由于微博的业务特点,经常会面对突发的几倍于往常峰值的流量,比如重大新闻、娱乐圈的热点事件等。要想能相对平稳的应对这种峰值,我们必须具有快速且大批量甚至翻倍的扩容能力。要具备这种能力,除了要对整个系统的架构设计进行改造之外,对于我们的分发系统(无论是Docker还是非Docker,扩容本质都是分发)也是一个很大的挑战。
整体架构
前几篇讲到,私有云(内网)和公有云(阿里云)是为了满足不同的场景,所以他们对于镜像仓库服务的需求也会有所不同:
-
内网镜像仓库的压力主要来自日常发布以及弹性调度,带宽压力相对平稳。
-
内网的环境要比阿里云复杂的多,各个业务间的操作系统版本,软件版本,配置等都存在很大差异。
-
阿里云镜像仓库的压力是由当次需要扩容的机器数量决定的,无法预先估计出来。
-
阿里云的环境是可定制的、纯净的、统一的。
基于以上几点,我们在内网和阿里云也采用了不同的部署架构,如下图:
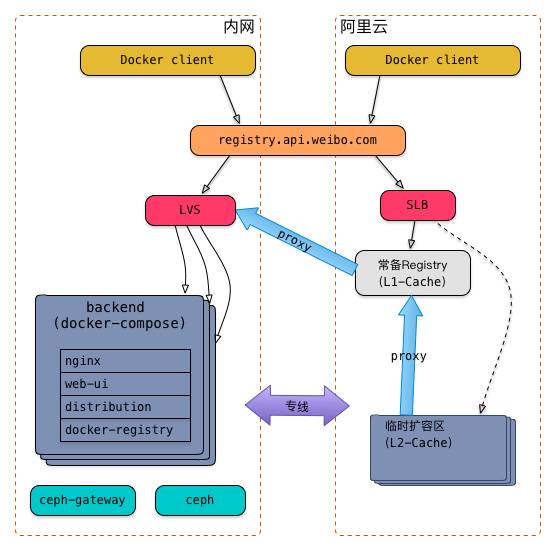
为了消除差异,在内网和阿里云,使用了相同的域名,分别指向内网的LVS和阿里云的SLB;其余的细节我们稍后再讲。
目前来看这个架构解决了我们面临的两个主要问题:
一:阿里云的分发能力问题
关于阿里云中的镜像分发,主要有两个痛点:
-
镜像体积大:微博平台的业务以Java为主,众所周知,Java的运行时环境是比较重的,我们一般的业务镜像体积都在700M以上。
-
全量Pull:每次扩容都是新的机器,所以每台机器都要拉取完整的镜像,而不是增量Pull。
其实这两个痛点可以归为一点,就是扩容带来的带宽压力非常大。以扩容50台为例,估算一下总带宽消耗:50 * 700M = 35GB = 280Gb;理论上,1台千兆网卡的机器可以在280/60 ≈ 5分钟内分发完,但实际上会出现大量Pull失败的情况。
为此,我们利用镜像仓库内置的proxy机制,构建了一套可以弹性扩容的多级缓存架构(上图中右侧部分)
-
我们将镜像仓库服务也作为一个特殊的服务池来管理,其操作系统镜像是定制的;
-
部署一台镜像仓库作为常备服务,同时也作为一级缓存,提高镜像仓库服务本身的扩容速度;
-
当需要在阿里云上进行大批量业务扩容时,会先按照一定比例扩容镜像仓库服务(这个比例是和镜像大小、机器硬件配置、所处网络环境等相关的,在我们的场景中是 1:20),作为二级缓存。
对镜像仓库的操作系统镜像,我们也做了一些优化,如下:
-
支持指定一个镜像列表进行预热:可以通过环境变量(docker run的-e参数)将当次扩容需要的业务镜像列表传入镜像仓库容器内;这样,镜像仓库就可以支撑多种业务同时扩容;
-
内置了JDK,Tomcat等常用的基础镜像,减少预热镜像的耗时;
-
预热完毕后,自动调用阿里云SLB接口,添加后端节点,之后就可以对外提供服务了。
阿里云镜像仓库临时扩容区的生命周期如下图:
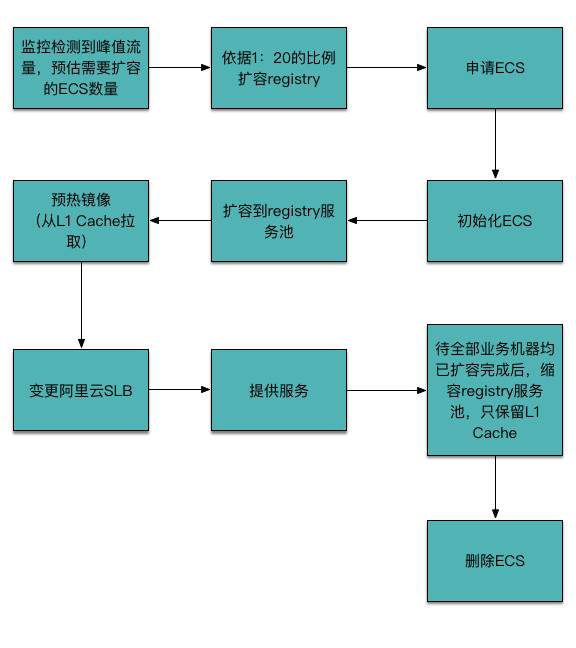
注意,预热这一步是很关键的,如果不预热,所有请求都会逐级回穿(而不是等待),结果可想而知。
备注:1:20是反复测试后得出的比例——即在只有1台镜像仓库的情况下,最大能供20台机器同时拉取700M的镜像,时间在2分钟以内;数量再多的话,就会出现拉取失败的情况。
目前,这套架构保证了在阿里云中10分钟扩容1000个节点的能力,并且同时降低了成本和专线的带宽压力。
二:内网环境不统一问题
由于Docker版本的更新非常快,且向后兼容性不够好。随着使用Docker的时间越来越长,我们的生产环境上运行的Docker版本也越来越多,从1.2到1.8都有。在Docker 1.6发布时,原有的镜像仓库项目(docker-registry)被标记为Deprecated,迁移到了新的distribution项目,它使用Go实现,API也和原来有很大的不同。Docker 1.6以下的版本只支持旧版的API,1.6及以上的版本默认使用新的API和镜像仓库交互,并支持fallback到旧版API。
为此,我们同时保留了docker-registry和distribution两个服务,并使用docker-compose编排了一组能够和我们已有的所有版本Docker正常交互的服务,大致的结构如下:
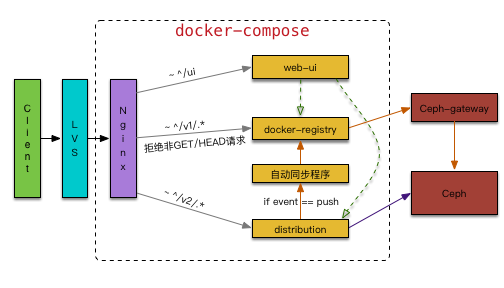
如图中所示,在Nginx层通过配置将来自不同版本Docker的请求转发给相应的后端;为了避免镜像同步的问题,拒绝来自Docker 1.6以下的所有push请求,同时利用内置的notification机制实现镜像的自动同步(单向)。
对于存储层,我们对比了Glusterfs、Swift、Ceph之后,最后选用了Ceph。原因有几个:配置简单,社区更活跃,支持块存储。在保证了高吞吐量的同时,也解决了单点问题,一旦distribution服务器出现问题,只要Ceph还在,就可以快速重建出来。
这里值得一提的是,distribution本身就是一个Ceph客户端,可以直接和Ceph交互,配置也很简单;而docker-registry则需要通过ceph-gateway来访问Ceph,配置要复杂一些。
备注:最新版本的distribution中已经把Ceph相关的配置和rados驱动代码都移除了,只能通过部署一套Swift gateway的方式来间接访问Ceph。
Docker及其工具本身的问题
当然,除了上面两个和微博环境相关的问题之外,还有一些Docker本身及其周边工具的问题。
上面提到,Docker的版本更新非常快,而且经常有颠覆性的更新(比如1.6 和 1.10),这也反映出整个Docker社区是比较激进的,所以很多使用上的细节的东西需要我们在实践中一点点去积累经验,同时关注Docker社区的动态,才能更加得心应手的使用这项技术。
这里列举几个我们碰到的相对比较重大的问题(和镜像仓库相关的):
proxy机制的缓存失效问题
先来看一下镜像仓库proxy机制(官方一般叫pull through cache)的原理:
一个distribution可以被配置为另一个distribution(官方或私有都可以)的proxy(只读的,即只能pull,不能push),在config.yml中添加如下配置即可:
-
proxy:
-
remoteurl: http://10.10.10.10
配置好之后,当一个Docker pull请求过来时,会检查本地是否已经存在被请求的镜像;如果没有,则会穿透到配置的后端,并同时缓存在本地,这样后面的请求就不会再穿透了。
缓存默认的有效期为一周(可通过修改代码的方式调整,需要重新编译);超过有效期之后,会由一个scheduler协程来删除被缓存镜像的所有layer的文件及元数据。当一个镜像缓存过期之后,这个镜像的pull都会失败,并提示image not found。
问题的原因在于distribution检测缓存有效的逻辑有问题,具体这里就不详述了,感兴趣的同学可以参考这个issue或者阅读源代码。
官方就这个问题做过一次修复,但并不彻底。在官方彻底修复之前,我们的解决办法是,将缓存有效期设置的长一点(一个月),同时定期(一个月)清除一次缓存目录,再重启distribution容器。
使用HTTPS协议时,X-Forwarded-Proto头的设置问题
有时候,出于安全或使用规范等原因,我们会自己搭建一套支持HTTPS协议访问的镜像仓库服务;业界普遍的做法是把证书配置在Nginx层,并且转换为HTTP协议,再传给后端,我们也是这么做的。
这里有一点需要注意:原理上,无论是Docker pull还是push,其实都是一系列的HTTP请求。而对于Docker push,distribution会根据”X-Forwarded-Proto”这个Header值来判断下一次返回给client的Location是HTTP协议还是HTTPS协议。所以要保证在请求到达distribution端时,X-Forwarded-Proto头的值是正确的,是客户端最开始发起请求的协议。否则在开启镜像仓库的权限控制后,会有push失败的情况。
当整个HTTP调用栈中存在多层Nginx或类似的反向代理程序时,尤其要注意这个问题。比如,在我们的两层Nginx中,分别是这样配置的:
LVS层:
location / { ... proxy_set_header X-Forwarded-Proto $scheme; ... } docker-compose层:
location / { ... # proxy_set_header X-Forwarded-Proto $scheme; ... } 使用了阿里云SLB之后,docker pull会等待一段时间才开始拉取镜像
在将阿里云的registry域名指向SLB之后,发现一个奇怪的现象,每次从域名去docker pull都会等待一段时间才开始拉取镜像,而直接按IP拉取则没有问题,如下:
docker pull registry.api.weibo.com/busybox:latest // 等待大约20秒才开始下载镜像 docker pull 10.75.0.52/busybox:latest // 正常
经过一番调查,发现Docker daemon在收到pull命令后,会先检测指定的地址是否是一个合法的服务提供者;检测时,会按照https+v2、https+v1、http+v2、http+v1的顺序逐个请求;而阿里云的SLB对于未监听的端口,默认行为是不回包,所以客户端只能等待超时。
我们的解决办法是给SLB添加了TCP的443端口,这样客户端很快就知道这个distribution并不提供HTTPS服务,从而立即fallback到HTTP协议。
注:此问题在Docker 1.6.2版本中存在,至于后面的版本有没有做修复,有兴趣的同学可以自行试验。
总结
镜像仓库服务作为微博混合云基础设施中的一部分,其分发能力和稳定性至关重要。我们采取的架构方案是综合考虑了微博的业务特点、成本、历史遗留问题等诸多因素而设计的,并不一定适合于大家。同时,为了解决需要先扩容镜像仓库的问题,缩短总扩容耗时,我们也在开发一套基于BitTorrent协议的镜像分发方案,希望能和业界同行多交流学习。 ▽
延展阅读(点击标题):
-
新浪微博混合云架构实践挑战之弹性调度揭秘
-
微博混合云架构实践之不可变基础设施
-
日活1亿+:看新浪微博混合云DCP的架构实战
本文系InfoQ原创首发,未经授权谢绝转载。

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

