独特低运营成本海量日志处理系统架构
本文是 WOT2016互联网运维与开发者大会 的现场干货, 新一届主题为 WOT2016企业安全技术峰会 将在2016年6月24日-25日于北京珠三角JW万豪酒店隆重召开!
黄慧攀表示,又拍云主要做CDN,因此网内会有大量日志产出,量级超乎想象。通常在处理类似这样量级的大数据时会用到Hadoop、Spark等流行的解决方案,但又拍云却没有选择这些流行的算法。下面我们就走近又拍云来体会这套执行成本高,但运营成本较低的独特海量日志处理系统架构。
又拍云业务架构概述
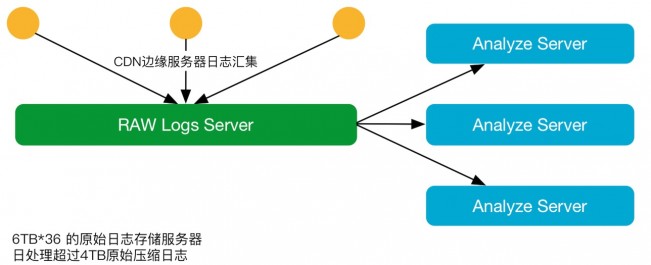
业务架构
黄慧攀表示,又拍云业务架构非常简单原始,把NGS日志全部打出来,CDN边缘有100多个节点,每个节点里面有几十台服务器,乘起来就是几千台服务器的日志。每隔每五分钟把边缘每一台服务器的日志给收集到原始日志服务器,然后再从原始日志服务器里面供给Work,Work里可多可少,大部分是横向扩展。然后分析日志,最终产生统计数据,切割出来一些为客户提供下载日志。在NGS上一个CDN节点是给所有的用户提供访问的,不管是大客户还是小客户,很有可能你们都在用同一台NGS,也就是说它的日志里面会混杂着很多个域名。那么日志处理系统就会面临如何把这些日志按照域名给切分开来?在切分开来数据的基础上,如何做必要的数据统计及分析?
原始日志的收集和存储
黄慧攀表示,又拍云原始数据的收集经历了三个阶段,分别是在2011~2014年、2015年、2016年。
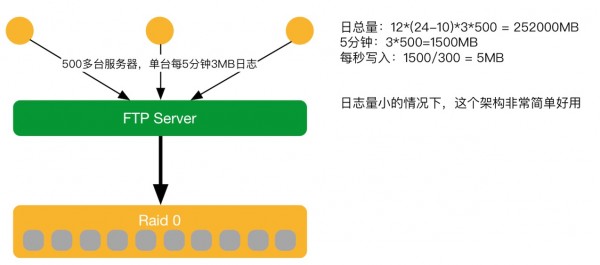
2011~2014年V1
2011~2014年第一阶段。在中心搭一台FTPserver,其他边缘服务器直接把日志FTP上传,之后存起来的一个简单架构。黄慧攀表示,当量级小时,这个架构很好用,简单又成熟。但如果一旦数据量变大,就会出现瓶颈。又拍云在2014年做云存储,CDN卖的不多,访问量不太大,数据量也少,所以这个架构可以应对。
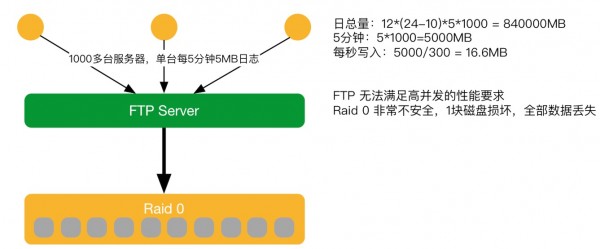
2015年V1显露不足
随着这个业务扩展,又拍云在市场做了很多的工作,接入很多的大客户,导致日志量翻超过10倍之多。那么之前2011年设计的系统只考虑到考虑到10倍的处理能力,所以 FTPserver弊端瓶颈就都显露出来。如在FTPserver没有办法接收这么多的客户端上传,边缘节点太多,连接到FTPserver上,FTP的进程几千个,服务器很快会被卡死,导致数据不能上传。如上图,下面Raid 0非常不安全,1块磁盘损坏,全部数据丢失。虽然边缘日志缓存7天,边缘重新再上报,及时修复没有影响业务。但会导致人有点手忙脚乱也不是很好。
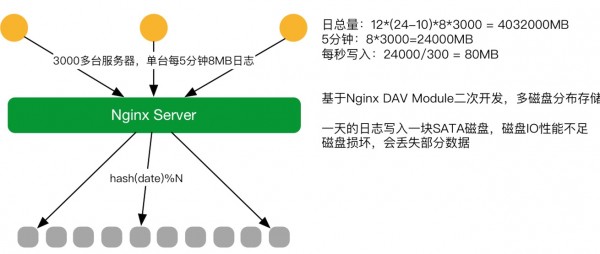
2016年V2
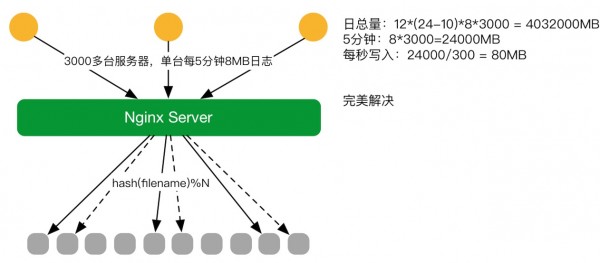
2016年初第二个阶段,对原有系统进行改造。把FTPserver,换成了Nginx Server,Nginx Server文件上传基于DAV Module并做二次开发就可以接受文件的请求。 因原生模块只支持配置一个路径,也就是日志只能固定写入一块磁盘。可服务器不可能用一块盘能存得下,每天有几百G、几个T的数据需要存储,磁盘定会爆掉,当时并没有这么大的磁盘。所以对DAV Module做二次开发,如根据日期,存储机器一块盘是6T能存下一天的日志,第一天用1号盘,第二天用2号盘的模式。
2016年V2.1
第二个版本上线之后,发现了磁盘的写入成了瓶颈,磁盘不够快,因为它是SATA磁盘,写不进去这么多数据。这时 第三个版(2.1版本) ,目前正在实用的版本诞生。对DAV Module进行更改,从原来的根据日期改成用文件名。另外在这个基础上做增强,原始日志在上传上来的过程中,同时拷贝到旁边一块盘一份,这样就可以避免单盘故障而导致服务不可用,也不会有数据丢失的问题,尽量的保障业务可以24小时在运行,不需要停下来。这个方案比较完美的解决原始数据的收集问题。
对大量数据进行切割-排序-合并
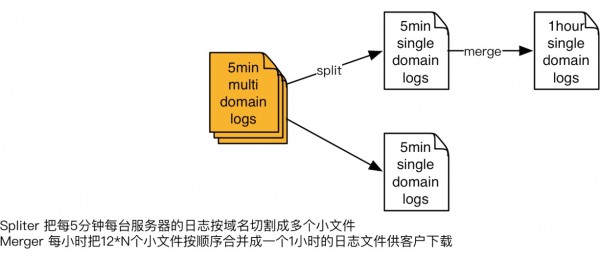
切割-排序-合并
切割。用C写的一个日志切割程序,把每5分钟每台服务器的日志按域名切割成多个小文件,临时的存在SSD磁盘上面去。切割完成之后,还会有线程检查前一个小时是不是切割已经完成。
排序。如想要让排序变得简单,就要在前期做日志收集规划时做好基础。如每五分钟会有一个文件要上传上来,可把文件名做加工(把时日期时间点、哪五分钟的数据)。如一个小时有一千个小文件,在这一千个里面,一定有其中一百个是某一个五分钟的,就直接拿这一百个做排序。做排序时不用把这些数据减压出来,放到其他地方临时存储来做排序。是把这一百个文件打开,到每个文件在里面读,读第一秒,再问另外几个文件有没有,没有就跳下一秒,这样一个一个顺序下来,就按照时间序来读日志,合并到一个具体文件输出,这样的模式是最高效的。因为在处理过程中,就不用把一个具体的文件减压成文本。如把要减压,拿什么机器能够把原始日志给存下来是个问题,因为太大了。
合并。待切割排序完成,就把每小时把12*N个小文件按顺序合并成一个1小时的日志文件供客户下载。
对大量数据进行统计分析

凌晨零点最后一个文件合并出来会启动统计分析的业务流程,就可以综合的拿到一些比较有用的指标,如热门IP分布、URL分布、客户端、来源、状态码计数等数据。
系统架构演变过程中踩过的坑
黄慧攀表示,在系统架构演变过程中遇到了一些坑,把这些分享出来,希望大家不要踩。
第一:SSD inode 数不足,每5分钟切割出来的小文件非常多,要以最小block大小格式化磁盘。
第二:跨网络上传很慢,需要多线路支持;小运营商会改写内容,走HTTPS。
第三:日志存储磁盘SATA容易坏,要分别写入2个磁盘(SSD 也会坏)。
第四:服务器也不稳定,要双集群模式处理,保障业务不中断。
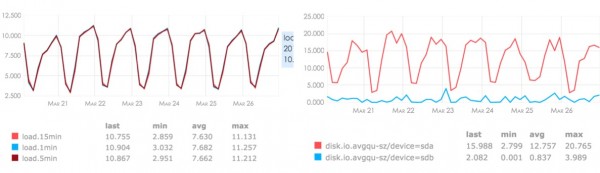
存储服务器和处理服务器的监控图
演讲最后,黄慧攀为大家展示了存储服务器和处理服务器的监控图。他表示,当下这个海量日志处理系统架构基本是非常稳定,集群状态很正常健康,冗余度也比较高。
演讲视频: http://edu.51cto.com/lesson/id-100758.html
【讲师简介】

黄慧攀, 又拍云CTO。他是 aLiLua Web 开发框架的作者,有 14 年互联网从业经验,技术经验涵盖范围比较广,早期以前端 Web 开发为主,后期逐步转到底层研发方向。QCon 、ArchSummit、中华架构师大会讲师,在高性能网络服务、分布式存储系统等方面有较深入的研究。
【责任编辑:wangxueyan TEL:(010)68476606】
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

