Kubernetes方法论之扫盲篇
文章由才云科技翻译,如若转载,必须注明转载自“才云科技”。查看原文请点击“原文链接”。
随着容器逐渐受到企业的注意,焦点慢慢被转移到了容器编排工具上。复杂的工作负载在生产过程中需要成熟地被调度,编排,弹性扩容和管理工具。有了Docker,管理运行在主机操作系统上的容器以及它的生命周期变得十分容易了。因为容器化的工作负载运行在多个主机上,我们需要一些工具在上面管理单个的容器和单个的主机。
Docker数据中心,也就是Mesosphere DC/OS和Kubernetes起重要作用的地方。他们可以让开发者和操作者处理多个机器就如同处理跑在集群上的单个机器一样。开发运维组人员通过应用程序编程接口(API),命令行接口(CLI)或者专业工具来提交工作到容器编排引擎(COE),这个引擎负责管理应用程序的生命周期。
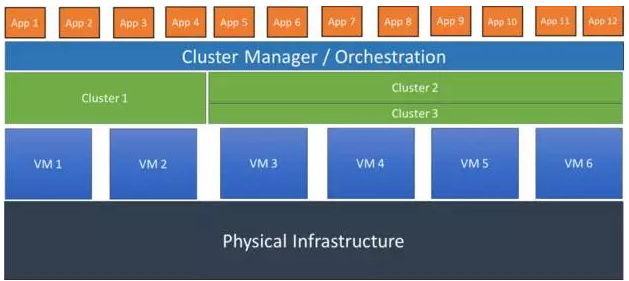
COE的集群化版本作为CaaS来交付,容器作为一种服务。CaaS的例子包括谷歌GCE,RackSpace的Carina,亚马逊EC2 容器服务,Azure容器服务和Joyent Triton。
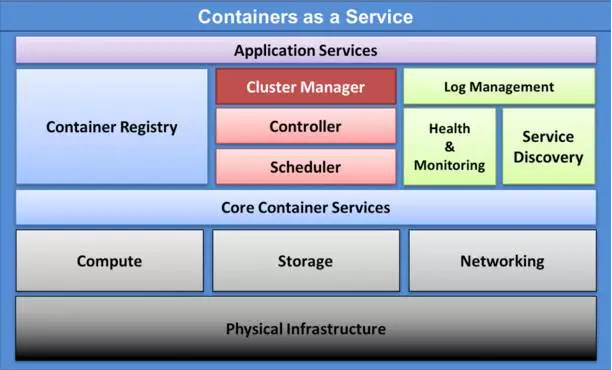
Kubernetes,作为一个开源集群管理工具和容器编排引擎,是谷歌内部数据中心管理工具Borg的简化版本。在2015的KubeCon(Kubernetes的首次会议)庆祝了其新功能1.1版本的发布。
我写了一篇用Hadoop的商业实现来对比COE市场格局的文章。有很多初创公司和成立的平台在为COE尝试捕捉企业市场。Kubernetes脱颖而出,归功于它来自谷歌网络级的工作负载运行经验的成熟性。基于我的个人经验,我在尝试着调出可以令Kubernetes为容器标准化的功能。
PODs:新虚拟机
容器和微服务有一个独特的属性——他们一次只运行一个进程,有且仅有一个。虚拟机运行在全栈LAMP应用程序上是司空见惯的事,但是同样的应用程序不得不被分裂成至少两个容器——一个用PHP运行Apache,另外一个运行MySQL。如果将Memcached和Redis扔到堆栈里,他们同样需要运行在分别的容器中。
这个模式使得配置发生了变化。例如,缓存容器应该跟网页容器紧密相关。当网页层通过运行额外的容器扩容,缓存容器也需要被扩容。当request到一个网页容器的时候,就会在相应的容器缓存里检查数据设置;如果没有找到的话,数据库查询就被放到MySQL里了。这个设计被一起调用来配对网页和缓存容器,然后将他们一起存在本地主机上。
如果Kubernetes是新的操作系统,那么pod就是新的进程
在Kubernetes中pod就是可以轻松地给多个当作单个部署单元的容器贴上标签。他们在同一个主机上协作,分享同一个资源,比如说网络、存储系统和节点存储。每个pod得到一个pod组里面所有容器共享的专用IP地址。到那时也并非完全如此——每个运行在同一个pod里面的容器都有着相同的主机名字,所以他们可以被定为为一个单元。
当一个pod被扩容的时候,所有在里面的容器被扩容为一个组。这个设计弥补了虚拟化应用和容器化应用之间的不同。然而当保留每个容器运行一个进程的时候,我们可以轻松地将容器归到一个组,使之作为一个单元。所以,一个pod在微服务和Kubernetes的情况下就是一个新的虚拟机。即使只有一个容器需要被配置,它也要按照作为一个pod来打包。
Pods管理开发和部署之间的分离问题。当开发人员注意于他们的代码的时候,操作人员来决定什么进入pod。他们组装相关的容器,然后通过pod的定义来缝合他们。这就有了最终可移植性,因为在这里容器没有进行特别打包。简单地放这里,一个pod就是多个容器镜像一起管理的密钥清单。
如果Kubernetes是新的操作系统,那么一个pod就是一个新的进程。随着他们变得更加普及,我们会看到开发运维人员将pod密钥清单转换为多个容器镜像。Helm,来自Deis的制造商,是一个用作Kubernetes pods市场的服务的例子。
Service:可轻松发现的端点
整体服务和微服务之间的一个重要的差别就是相关性被发现的方式。整体指的可能就是一个专门IP地址或者一个DNS分录,微服务调用它之前不得不去发现相关性。因为容器和pods可能会搬迁到任何节点。每次一个容器或者一个pod复活,它就会得到一个新的IP地址。这样的话跟踪端点就变得相当难。开发者不得不在发现后端查询services,比如etcd,Consul,ZooKeeper或者Sky DNS。这要求代码级别的修改来让应用程序正确地运行。
Kubernetes内置服务发现功能十分出众。Kubernetes里面的Services为pods一贯保持定义完善的端点。这些端点仍然是一样的,即使当pods被迫迁移到其它节点,或者是复活的时候也都是一样的。
多个pods运行在一个集群的多个节点上面,会被暴露为一个service。这是微服务的基本构件块。Service密钥清单拥有定义和将多个运行为微服务的pods归到一个组的正确标签和选择器。
例如,所有的Apache网页服务器pods运行在集群的任意一个节点上,集群匹配了“frontend”节点,这个网页服务器会成为service的一部分。会带来多个运行在集群上一个端点下的pods的抽象层。这个service有一个IP地址和端口组合,当然,还有一个名字。使用者可以根据IP地址或者service的名字指向service。这个能力使得它将遗留的应用程序移植到容器中十分灵活。
如果多个容器分享同一个端点,他们如何均匀接受通信?这就是负载均衡性能服务流进来的地方。这个功能是Kubernetes和其它COE的关键区别点。Kubernetes有一个轻量级内部负载均衡器,可以路由流量到所有参与服务的pods。
Service可以以这三种方式暴露出来:内部、外部和负载均衡。
内部:比如数据库和缓存端点的一定的服务,不需要被暴露。他们只被其它内部pods使用到应用程序。这些服务通过一个只在集群中可进入的IP地址被暴露,但是没有到暴露到外部世界。Kubernetes通过暴露一个端点来隐藏敏感服务,这个端点对于内部依赖是可用的。这个功能通过隐藏私有pods带来一个额外的安全层。
外部:Service运行网页服务器或者公开可访问的pods,这些通过一个外部端点被暴露出来。这些端点通过特定端口在每个节点上是可得的。
负载均衡器:在云提供商提供一个外部负载均衡的场景下,service可被连接到那里。比如,pods可能会通过一个弹性负载均衡器(ELB)接收流量,或者通过谷歌GCE的HTTP负载均衡器接收。这个功能令第三方负载均衡器整合到Kubernetes service。
Kubernetes负起了接管发现任务和微服务负载均衡器的重任。它将陷在底层基础设施中处理复杂的管道的开发运维人员解救了出来。开发人员也可以使用主机名或者环境变量的标准管理来将注意力集中在他们的代码上,而不需要担心额外的代码(比如注册和发现服务的)。
文章由才云科技翻译,如若转载,必须注明转载自“才云科技”。查看原文请点击“原文链接”。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

