从HashiCorp Nomad对上百万容器进行调度所学到的经验
Docker在2013年三月实现了开源发布,它的出现让软件开发行业对于现代化应用的打包以及部署方式发生了巨大的变化。紧随着Docker的发布,各种具有竞争性、致敬性以及支持性的容器技术纷纷涌现,为这一领域带来了极大的关注度,同时也引起了人们的反思。这一系列文章将解答读者的各种困惑,对如何在企业中实际使用容器进行分析。
这一系列文章首先将对容器背后的核心技术进行观察,了解开发者目前如何使用容器,随后将分析在企业中部署容器的核心挑战,例如如何将容器技术与持续集成和持续交付管道进行集成,并对监控方式进行改进,以支持不断变化的负载,以及使用短期容器的潜在需求。本系列文章的总结部分将对容器技术的未来进行分析,并探讨无核化技术(unikernels)目前在处于技术前沿的组织中所扮演的角色。
本文是本系列文章“ 实际应用中的容器 —— 远离炒作 ”中的其中一篇。你可以通过RSS订阅该系列文章,以获取更新的通知。
以 Nomad 、 Mesos 和 Kubernetes 为代表的调度器的目标是让组织能够以更快的步调部署更多的应用程序,同时提高资源的使用率。调度器可将应用程序与基础设施进行分离,因此在一个host上可运行多个应用,而不再受到一个host仅运行一个应用的限制。这就提高了集群中资源的利用率,并节省基础设施方面的成本。
高效的调度器需要具备三种品质。第一项是能够满足多个开发团队要求同时部署应用的需求。第二项是能够快速地在跨全球的基础设施范围内分发应用。最后一项则是重新调度应用程序,让有故障的节点重新成为健康的节点,提供集群范围的应用程序可用性管理,以及自恢复的能力。、
由HashiCorp的设计的 百万级容器挑战 (Million Container Challeng)是用于检测其调度器产品Nomad在5000个host上对100万容器进行调度的效率的一种测试手段。这一挑战的目的是观察Nomad在超大规模部署的情况下的表现,并对其进行优化。现代化企业配备的数据中心规模之大是前所未有的,他们所使用的工具也必须满足客户的需求。在完成这一测试并进行了性能优化之后,Nomad在Google Cloud上可做到在5分钟之内对跨5000个host上的100个容器进行调度。本文将描述从对100万个容器进行调度的实现中所学到的知识。
(点击放大图像)
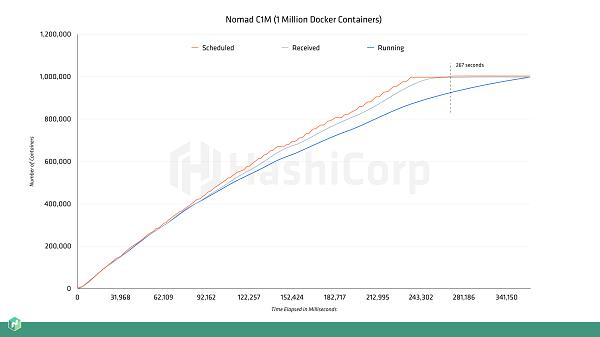
乐观并发调度器能够以线性增长率扩展调度的吞吐量
调度器一般来说可以分为三个类别:集中式(monolithic)调度器、基于offer的调度器,以及状态共享(shared state)调度器。集中式调度器在一个单一的、中心化的地方处理调度逻辑,通常会绑定在一台单一的机器上。基于offer的调度器(例如Mesos)同样在一个单一的地方进行调度决策,但可以通过将资源分配给多个各自具备任务的框架而实现并行化。而状态共享调度器则在多个地方处理调度决定,通过并发控制,以并行方式进行调度而获得统一的状态。
Nomad是一种乐观并发的共享状态调度器,这意味着所有服务器都可以并行地参与调度决策。主节点将提供额外的协调功能,这是实现并发决策,并确保客户端不会产生过量订阅所不可缺少的。在这次百万级容器挑战中,共有5台Nomad服务运行在Google Cloud上的n1-standard-32实例上,形成了一个CPU总数达到160的Nomad服务器集群。主节点使用了一半的CPU核进行调度工作,因此总共可以并行进行140个调度决策。这种并行性使得Nomad能够在总时间5分钟的挑战中做到每秒大约对3750个容器进行调度。
在对Nomad的设计进行分析之前,有必要解释一下Nomad的术语: 作业 (job)是指对提交至调度器的某项工作的声明,而作业是由多个 任务 (task)所组成的。一个任务即是指将要运行的应用程序,在这示例中即表示通过一个Docker容器运行一个简单的Go服务。
Nomad的乐观并发设计受到了Google Omega 的启发,后者引入了并发、共享状态、以及无锁乐观并发控制等方式,以应对在其上一代调度器 Borg 中所遇到的挑战。并发性使调度器实现了伸缩性,体现在为大量任务(容器或应用程序)找到居所,以及为多个开发团队提供服务。多个开发团队可同时提交作业,而调度器则能够并行地处理这些作业的任务。对于那些无法实现并行调度的调度器来说,一旦某个团队提交了一项作业,就会阻塞其他团队同时对其他作业进行调度的操作。在像Google这样规模的公司中,开发者提交作业以及机器获取作业的数量都是非常庞大的,因此这种类型的并行设计就显得非常关键。Nomad的出现受益于一些最新的研究成果,它最终为开源社区带来了一个顶尖水准的调度器。
(点击放大图像)
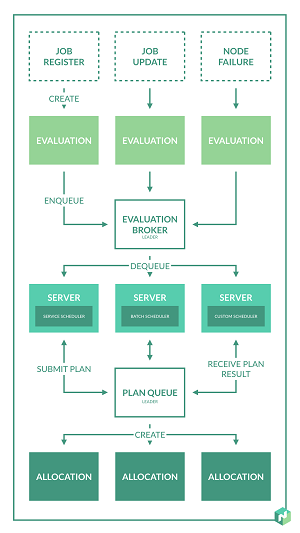
如果读者想了解Nomad的调度设计的更多信息, 请阅读开源网站上对其架构详细的描述 。
贪心调度算法与扩散调度算法之间的权衡
调度算法共有两种主要的算法,即 贪心 (bin pack)算法与扩散(spread)算法。Nomad所使用的是贪心算法,这意味着它会尝试用尽当前节点的全部资源,随后再将新的任务传递至某个不同的节点。与之相反,扩散算法会尽量保证所有节点的使用率保持均衡。贪心算法的优点在于它可支持更多不同的工作量,最大化资源的利用和使用率,这最终将使基础设施的成本降至最低。而扩散算法的优点在于它能够将风险进行分散,如果某台机器产生了故障,该算法可减少响应及恢复的复杂性。如果某台机器仅运行一至两个任务,那么为这些任务找到新的节点非常容易。与之相反,如果某个发生故障的机器运行着200个任务,那么调度器就必须为这200个任务找到新的位置。
使用贪心算法时,随着节点上处理的任务越多,之后的任务就越有可能汇聚到这个节点上,直到这台机器的能力达到极限为止。这种方式确保了某个节点将最大化地处理任务,之后调度器才会将新的任务发送至某个新的节点上。此外,如果需要为某个占用大量资源的任务找到合适的节点,这种方式也能更方便地找到一个具有足够可用资源的节点,也能够更方便地关闭某些没有使用的机器。
简单的作业规范使对作业提交的管理具有可伸缩性
使调度器具备对上百万容器进行调度的能力只是整个挑战中的一部分。另一个挑战在于能否让开发者方便地提交大规模的作业。Nomad的作业规范采用了一种声明式的风格,非常易于使用。
在下面这个示例中,“bench-docker-classlogger”这个作业在定义中表示它希望Nomad能够为“classlogger_tg_1”这个任务组调度20个实例,在该任务组中包含了“classlogger_1”这个任务。这个任务对应着一个Docker镜像,它需求20MHZ的CPU、15M的内存以及10M的磁盘空间。当这个作业被提交至Nomad后,它会在整个服务器集群中调度20个可用资源的实例,在这些位置运行20个Docker镜像。如果实例数量从20提升至50,那么Nomad只需再调度30个任务即可。
作业的规范还允许开发者对于任务可在何种类型的host上进行调度加以限制。举例来说,某个开发者希望将某些任务限制在Windows机器上、某个规格的机器、或将所有作业分散在不同的host上运行。最后,重启策略这部分定义了Nomad如何对失败的任务进行重启。在这个示例中,该Nomad作业设置了一个重启管理器,可防止某个任务在5分钟内重启超过3次。
job "bench-docker-classlogger" { datacenters = ["us-central1"] group "classlogger_tg_1" { count = 20 constraint { attribute = "${node.class}" value = "class_1" } restart { mode = "fail" attempts = 3 interval = "5m" delay = "5s" } task "classlogger_1" { driver = "docker" config { image = "hashicorp/nomad-c1m:0.1" network_mode = "host" } resources { cpu = 20 memory = 15 disk = 10 } } } } 重要的是,作业规范是声明式的,它定义了被提交作业的理想状态。用户只需表示需要运行该作业,而无需表达应当在何处运行该作业。Nomad的职责是确保实际的状态满足了用户所设想的状态。这就使对大型群集与大量作业提交的管理变得简单许多,因为用户不必再设法让实际状态去匹配理想状态,Nomad已经自动地完成了这一工作。
无论是在开发者还是机器在层面,可伸缩性都是必须考虑到的部分。在机器层面上,Nomad的乐观并发设计使大规模化变得可能。而在开发者或组织层面上,简单的作业规范使作业的提交很容易实现大规模化。
在进行大规模的容器调度时,服务发现是必不可少的
要使在5000个host上调度100个容器的能力体现出实用性,你必须做到在这些容器已确定位置后发现他们的具体位置。从逻辑上说,以手动方式对这种规模的服务配置进行更新是不可能的,因此必须借助自动化方案的力量。
以HashiCorp的 Consul 或 ZooKeeper 为代表的服务发现工具使服务能够将自身与他们的地址注册在某个中央注册表中。群集中的其他服务则通过这个中央注册表发现他们所需要连接的服务。举例来说,如果在30个host上调度了50个API的任务,那么每个任务都会它将的地址与端口注册在服务注册表中。群集中的其他服务则可以通过这个注册表查询这50个实例的地址与端口,以用于配置及负载均衡。如果某个任务失败了,调度器就可以在不同的地址重新调度它,这个新的地址会在服务注册表中进行更新,整个集群都将收到这个变更信息。而如果某个host产生了故障,调度器就需要改变运行在该host上的所有任务的地址,这些任务都需要在服务注册表中更新他们的信息。
在大规模环境中,一个基于调度器的应用交付工作流更能表现出高度的动态能力。作业的调度能力只是应用交付中的一项挑战而已,整个系统需要具备健壮的服务发现、健康检查以及配置信息,以确保系统的整体处于健康状态。Consul或ZooKeeper这样的服务发现工具对于这些动态系统的维护可谓至关重要。
调度器带来了应用与组织层面上的大规模化
在进行测试的过程中,Nomad也进行了一些技术改进。我们对基数树进行了优化,以进一步提升调度器的性能。我们还为调度器加入了一些健壮的特性,例如重试,以及设定了分配的上限,以应对Docker崩溃的情况。我们也克服了libcontainer中的某些奇怪行为,该问题产生于在单一节点上运行大量容器的情况下。我们将以上这些难以重现的条件都添加至Nomad,任何用户都可以通过最新版本的Nomad重新进行这些测试。容器仍然是一种新兴起的技术,这也是为什么Nomad选择通过VM、 chroot (2)与 raw-exec 中支持容器化的原因。
跨基础设施进行高速调度的实用性不仅体现在集群的大规模化上。大多数公司都设置了大量的团队或组织,他们需要对资源展开竞争。传统的方法是为每个组创建唯一的、分段的集群。虽然这种方式确实提供了隔离性,防止了出现交集的情况,但它往往会导致每个团队的集群利用率不足。
通过将单一集群中的资源作为池提供,公司就能够统一并简化他们的基础设施,同时为团队提供了更大的灵活性。如果某个团队在某一时刻需要使用更多的资源,他们就可以将这部分工作快速地扩展至集群中未使用的部分。正是快速的、集群范围的资源部署才使得这一点成为可能。
能够在5分钟之内对100万个容器进行调度的能力可解决绝大部分企业在可伸缩性方面的要求。Nomad还将继续进行性能改进,但这种改进将是边缘性的,其规模会越来越小。除了性能上的可伸缩性之外,组织上的可伸缩性则是下一个挑战。能够应对quota、安全性、charge back更多问题的特性将使调度器工作流更易于在大型组织中得到应用。
关于作者
 Kevin Fishner 在HashiCorp担任客户成功总监,他在为客户提供HashiCorp的各种开源与商业产品方面有着丰富的经验。虽然他目前是一位工程师,但在求学期间主攻的却是哲学专业。可通过@KFishner访问他的Twitter。
Kevin Fishner 在HashiCorp担任客户成功总监,他在为客户提供HashiCorp的各种开源与商业产品方面有着丰富的经验。虽然他目前是一位工程师,但在求学期间主攻的却是哲学专业。可通过@KFishner访问他的Twitter。
Docker在2013年三月实现了开源发布,它的出现让软件开发行业对于现代化应用的打包以及部署方式发生了巨大的变化。紧随着Docker的发布,各种具有竞争性、致敬性以及支持性的容器技术纷纷涌现,为这一领域带来了极大的关注度,同时也引起了人们的反思。这一系列文章将解答读者的各种困惑,对如何在企业中实际使用容器进行分析。
这一系列文章首先将对容器背后的核心技术进行观察,了解开发者目前如何使用容器,随后将分析在企业中部署容器的核心挑战,例如如何将容器技术与持续集成和持续交付管道进行集成,并对监控方式进行改进,以支持不断变化的负载,以及使用短期容器的潜在需求。本系列文章的总结部分将对容器技术的未来进行分析,并探讨无核化技术(unikernels)目前在处于技术前沿的组织中所扮演的角色。
本文是本系列文章“ 实际应用中的容器 —— 远离炒作 ”中的其中一篇。你可以通过RSS订阅该系列文章,以获取更新的通知。
查看英文原文: Lessons Learned from Scheduling One Million Containers with HashiCorp Nomad
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

