如何区分数据科学家,数据工程师与数据分析师
原作者: firedata | 来自: 数据人网
在我看来,神经网络总是众多机器学习模型当中最让人感到兴奋的其中一个模型。它不仅因为含有一个功能强大的反向传播算法,而且这模型的复杂度(回想一下深度学校当中很多的隐含层)和结构是来源于人脑结构。
然而,神经网络也并不总是很受欢迎,部分原因在于在某些情况下,它们的计算成本很高,而且,与诸如感知向量机(SVMs)这样的简单模型进行比较的时候,它们不见得能产生一个更好的结果。不过,我们再次谈起神经网络的时候,它还是很流行的,也很容易引起人们的注意。
在这篇文章中,我们将要使用neuralnet包来创建神经网络模型,并创建一个线性回归模型来与此进行比较。
数据集
我们将调用MASS包来使用Boston数据集。Boston数据集就是关于Boston郊区的房价的数据集。我们的目标就是通过使用其它可行的连续变量来预测为个人所有的房屋的房价的中位数。
set.seed(500)
library(MASS)
data <- Boston
首先,我们需要确认任何数据都不含有缺失值,而我们则要对此数据集进行一定的修正。
apply(data,2,function(x) sum(is.na(x)))
crim zn indus chas nox rm age dis rad tax ptratio
0 0 0 0 0 0 0 0 0 0 0
black lstat medv
0 0 0
很好,没发现任何缺失值。现在,我们要把这个数据集,以随机的方式把它们划分为训练数据集和测试数据集,然后在此创建一个线性模型,并使用测试数据集进行测试。在这里,我们将使用glm()函数而不是lm()函数,那是因为后面我们要对线性模型进行交叉检验的时候,glm()函数会更有效。
index <- sample(1:nrow(data),round(0.75*nrow(data)))
train <- data[index,]
test <- data[-index,]
lm.fit <- glm(medv~., data=train)
summary(lm.fit)
pr.lm <- predict(lm.fit,test)
MSE.lm <- sum((pr.lm – test$medv)^2)/nrow(test)
Sample(x,size)函数简单的输出了一个向量,它是从x向量当中,基于一个特定的大小随机选出来的一个模型。在默认情况下,抽样时我们无需对此进行转换:index就能很好体现这个样本就是随机抽样了。
由于我们要处理线性回归模型,我们将要使用均值方差(MSE)作为一个指标来预测我们模型的拟合程度有多少。
对拟合一个神经网络模型做相应的准备
在拟合一个神经网络模型之前,我们需要做一些准备工作。毕竟,神经网络的训练和调试不是这么容易的。
第一步,我们需要对数据集进行预处理。在训练神经网络模型之前,对数据集进行准则化处理是一个不错的选择。我不想在这里强调这一步有多么的重要:基于你的数据集,如果没有对数据集进行准则化处理,这可能会导致一些对分析毫无意义的结果的出现,使得训练过程进行的很艰难(大多数情况下,算法在到达最大允许迭代次数之前,是不会聚合的)。当然,你可以使用不同的方法来分析这个数据(z准则化、最大最小测试等等)。这里,我采用最大最小值得方法,并基于区间[0,1]来测量数据。通常来说,基于区间[0,1]或[-1,1]进行测量似乎能得到更好的结果。
因此,在进行下一步操作之前,我们先测量和分离数据集:
maxs <- apply(data, 2, max)
mins <- apply(data, 2, min)
scaled <- as.data.frame(scale(data, center = mins, scale = maxs – mins))
train_ <- scaled[index,]
test_ <- scaled[-index,]
记住,scale函数返回的结果是一个矩阵。因此,我们需要把它强制转换成数据框的格式。
参数
我目前所获悉的,就是目前还没有一个绝对的准则能让我们知道我们要用多少层和多少个神经元,就算目前已经有一些被大部分人所接受的一些重要准则可以进行辅助也不能解决这样的问题。通常来说,如果所有的都需要,一个隐含的层就可以进行大量使用了。一旦我们能确认神经元的数量,它应当处在输入层和输出层之间,通常情况下,输入层占其中的2/3。最少,我那些短暂的进行一次又一次测试的经历似乎是最好的答案,因为我们无法保证这里的任何一条规则都能在最好的情况下符合你的模型。
因为这是一个用处不大的实例,我们将根据这个规则对两个层进行隐藏。其中,输入层有13个输入值,两个隐藏层分别有5个和3个神经元,而输出层,因为我们是做回归分析,所以,只有一个输出值。
现在,我们拟合一下这个网络:
library(neuralnet)
n <- names(train_)
f <- as.formula(paste(“medv ~”, paste(n[!n %in% “medv”], collapse = ” + “)))
nn <- neuralnet(f,data=train_,hidden=c(5,3),linear.output=T)
记住这么两点:
1.基于某些原因,公式y~.不可以在neuralnet()函数当中使用。首先,你必须要写一个完整的公式,并把它当作是一个参数用到拟合函数当中。
2.隐藏的变量可以使用一个数值型向量来设定每个隐藏层的神经元数目,而参数linear.output用于指定我们是否要进行回归分析,此时,我们设定参数linear.output=TRUE,或者,分类,linear.output=FALSE。
nerualnet包提供了一个很好的作图工具:
plot(nn)
这是模型的图像,里面通过设定权重进行连接:
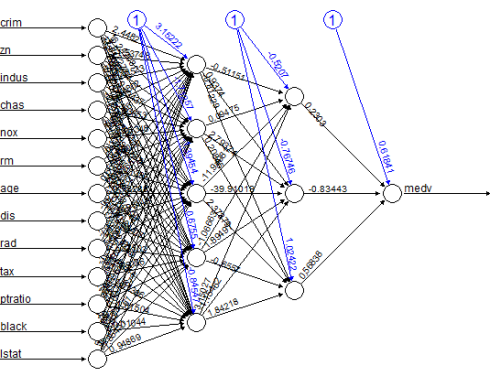
图中的黑线表示每一层与其相关权重直接的关系,而蓝色线表示拟合过程中,每一步被添加到蓝色线上的误差项。而这些误差可以表示一个线性模型的误差区间。
这个网络本质上就是一个黑匣子。因此,对于它的拟合效果、权重和模型说太多。不过,我们可以确信,这个训练算法实现了聚合的效果。因此,我们可以使用这个模型进行分析。
使用神经网络预测私有房屋的价格
现在,我们可以对测试集里的值进行预测并计算它的均值方差(MSE)。记住,神经网络会输出一个准则化预测。所以,我们需要重新对它进行测量和分析,以便于做一些有意义的比较。
pr.nn <- compute(nn,test_[,1:13])
pr.nn_ <- pr.nn$net.result*(max(data$medv)-min(data$medv))+min(data$medv)
test.r <- (test_$medv)*(max(data$medv)-min(data$medv))+min(data$medv)
MSE.nn <- sum((test.r – pr.nn_)^2)/nrow(test_)
现在,我们比较它们俩的均值误差。
print(paste(MSE.lm,MSE.nn))
[1] “21.6297593507225 15.7518370200153”
显然,在预测私人房屋价格的时候,神经网络模型的性能优于线性模型。再次说明,我们任然要小心就是因为它的结果就是基于上面训练数据集分组时的性能。下面,做完图以后,我们会进行一个快速的交叉检验来使得结果更具有说服力。
基于测试数据集的神经网络和线性模型的第一步可视化操作的图像如下:
par(mfrow=c(1,2))
plot(test$medv,pr.nn_,col=’red’,main=’Real vs predicted NN’,pch=18,cex=0.7)
abline(0,1,lwd=2)
legend(‘bottomright’,legend=’NN’,pch=18,col=’red’, bty=’n’)
plot(test$medv,pr.lm,col=’blue’,main=’Real vs predicted lm’,pch=18, cex=0.7)
abline(0,1,lwd=2)
legend(‘bottomright’,legend=’LM’,pch=18,col=’blue’, bty=’n’, cex
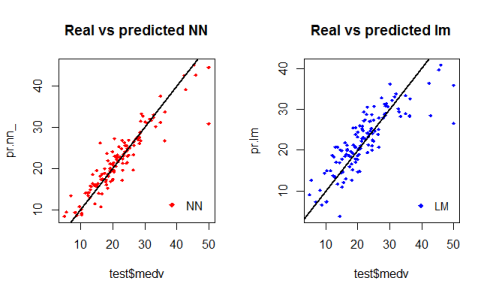
通过对其图像进行检验,我们可以得知,由神经网络所作出的预测(一般情况下)要比那些线性模型所拟合出来的预测让散点更加靠近拟合线(一条完美的准线,它表示MSE为0。因此,这种预测的结果是理想的)。
plot(test$medv,pr.nn_,col=’red’,main=’Real vs predicted NN’,pch=18,cex=0.7)
points(test$medv,pr.lm,col=’blue’,pch=18,cex=0.7)
abline(0,1,lwd=2)
legend(‘bottomright’,legend=c(‘NN’,’LM’),pch=18,col=c(‘red’,’blue’))
也许,下面的这个图像所做出来的比较更有用。
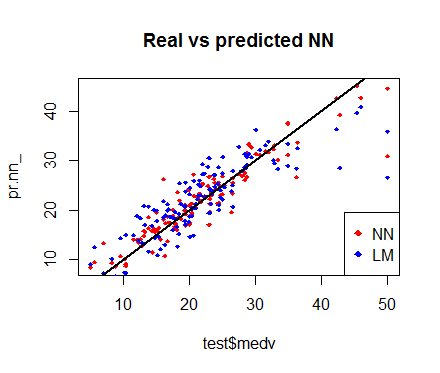
(快速)交叉检验
交叉检验是建立预测模型的另一个重要的步骤。交叉检验的方法有好几种,其基本思想就是重复下面的过程几次:
训练数据集分离
1.完成测试数据集分离
2.基于训练数据集拟合一个模型
3.用测试数据集测试模型
4.计算预测误差
5.重复这个过程K次
然后,计算平均误差,它可以让我们获悉这个模型是怎样运作的。
我们现在要对神经网络使用for循环语句来执行快速交叉检验,并使用boot包的cv.glm()函数来检验线性模型。我目前所知道的是,在R中,目前还没有一个已经构建好的函数来对这种神经网络进行交叉检验。如果你知道R里有这种函数,请你在留言板那里告诉我。下面,我们采用10次交叉检验的方法来验证线性模型的MSE:
library(boot)
set.seed(200)
lm.fit <- glm(medv~.,data=data)
cv.glm(data,lm.fit,K=10)$delta[1]
[1] 23.83560156
对于这个网络,我们要知道我是这样分离这些数据的:重复10次进行随机的90%的训练数据集和10%的测试数据集。而且,我也plyr包里初始化进度条,原因在于我想要关注这个过程的执行情况,因为神经网络的拟合过程可能需要一点时间。
set.seed(450)
cv.error <- NULL
k <- 10
library(plyr)
pbar <- create_progress_bar(‘text’)
pbar$init(k)
for(i in 1:k){
index <- sample(1:nrow(data),round(0.9*nrow(data)))
train.cv <- scaled[index,]
test.cv <- scaled[-index,]
nn <- neuralnet(f,data=train.cv,hidden=c(5,2),linear.output=T)
pr.nn <- compute(nn,test.cv[,1:13])
pr.nn <- pr.nn$net.result*(max(data$medv)-min(data$medv))+min(data$medv)
test.cv.r <- (test.cv$medv)*(max(data$medv)-min(data$medv))+min(data$medv)
cv.error[i] <- sum((test.cv.r – pr.nn)^2)/nrow(test.cv)
pbar$step()
}
拟合过程结束以后,我们可以计算它的MSE均值并把结果进行可视化。
mean(cv.error)10.32697995
cv.error17.640652805 6.310575067 15.769518577 5.730130820 10.520947119 6.121160840
6.389967211 8.004786424 17.369282494 9.412778105
作图代码如下:
boxplot(cv.error,xlab=’MSE CV’,col=’cyan’,
border=’blue’,names=’CV error (MSE)’,
main=’CV error (MSE) for NN’,horizontal=TRUE)
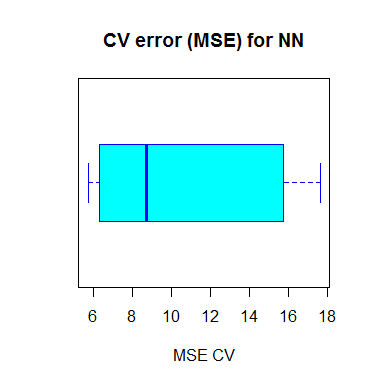
正如你在上图看到的那样,我们求出的这个神经网络的MSE均值为10.33,它比其中一个线性模型所算出来的结果要低,就算这里看起来像是交叉检验中,MSE的具体方差。这或许和数据集的分解方式有关,又或者是网络当中权重的随机准则化有关。通过多次以不同的方式模拟这个过程,你可以得到一个更精确的MSE估计值。
模型最终解读的启示
神经网络和黑匣子有很多相似的地方,它对这些结果的解读比对一些诸如线性模型这样简单模型的结果要难。因此,最终结果将取决于你是怎样用这个网络的,而你有可能用这样的原因进行解释。而且,正如你上面所看到的那样,我们还需要做一些额外的步骤来拟合神经网络,而小小的变动可以引起结果上巨大的不同。
你可以在这里查阅这篇文章来看一下整段代码的要领所在。
注:转载文章均来自于公开网络,仅供学习使用,不会用于任何商业用途,如果侵犯到原作者的权益,请您与我们联系删除或者授权事宜,联系邮箱:contact@dataunion.org。转载数盟网站文章请注明原文章作者,否则产生的任何版权纠纷与数盟无关。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

