什么是即时编译(JIT)!?OpenJDK HotSpot VM剖析
重点
- 应用程序可以选择一个适当的即时编译器来进行接近机器级的性能优化。
- 分层编译由五层编译构成。
- 分层编译提供了极好的启动性能,并指导编译的下一层编译器提供高性能优化。
- 提供即时编译相关诊断信息的JVM开关。
- 像内联化和向量化之类的优化进一步增强了性能。
OpenJDK HotSpot Java Virtual Machine被人亲切地称为Java虚拟机或JVM,由两个主要组件构成:执行引擎和运行时。JVM和Java API组成Java运行环境,也称为JRE。
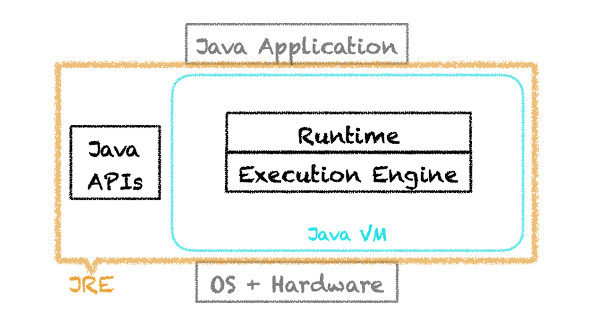
在本文中,我们将探讨执行引擎,特别是即时编译,以及OpenJDK HotSpot VM的运行时优化。
JVM的执行引擎和运行时
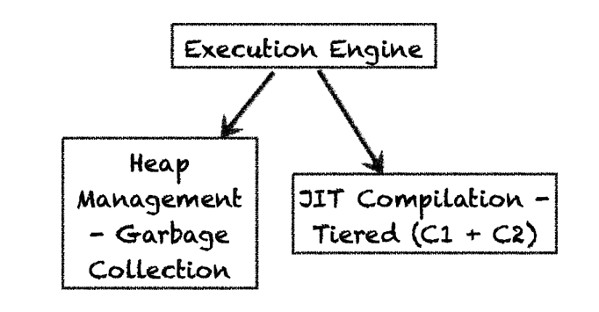
执行引擎由两个主要组件构成:垃圾回收器(它回收垃圾对象并提供自动的内存或堆管理))以及即时编译器(它把字节码转换为可执行的机器码)。在OpenJDK 8中,“ 分层的编译器 ”是默认的服务端编译器。HotSpot也可以通过禁用分层的编译器(-XX:-TieredCompilation)仍然选择不分层的服务端编译器(也称为“C2”)。我们接下来将了解这些编译器的更多内容。
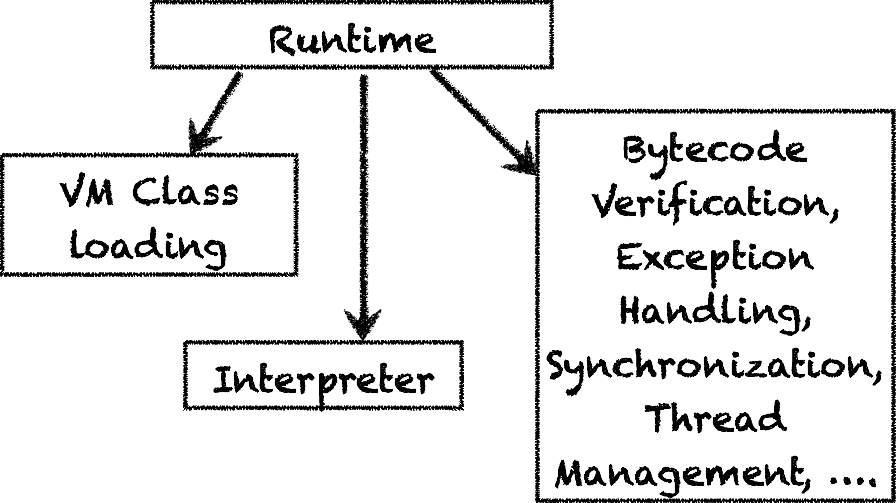
JVM的运行时掌控着类的加载、字节码的验证和其他以下列出的重要功能。其中一个功能是“解释”,我们将马上对其进行深入地探讨。你可以点击 此处 了解JVM运行时的更多内容。
自适应的即时编译和运行时优化
JVM系统为Java的“一次编写,随处运行”的能力提供背后的支撑。一个Java程序一旦编译成字节码就可以通过JVM实例运行了。
OpenJDK HotSpot VM转换字节码为可通过“混合模式”执行的可执行的机器码。使用“混合模式”,第一步是解释,它使用一个描述表把字节码转换为汇编码。这是个预定义的表,也称为“模版表”,针对每个字节码指令都有对应的汇编码。
解释在JVM启动时开始,是字节码最慢的执行形式。Java字节码是平台相关的,但解释并编译成的可执行的机器码肯定是平台无关的。为了更快更有效(并适应潜在的平台)地生成机器码,运行时会启动即时编译器例如即时编译器。即时编译器是一个自适应优化器,针对已证明为性能关键的方法予以优化。为了确定这些性能关键的方法,JVM会针对以下关键指标持续监控这些代码:
- 方法进入计数,为每个方法分配一个调用计数器。
- 循环分支(一般称为循环边)计数,为每个已执行的循环分配一个计数器。
如果一个具体方法的方法进入计数和循环边计数超过了由运行时设定的编译临界值,则认定它为性能关键的方法。运行时使用这些指标来判定这些方法本身或其调用者是否是性能关键的方法。同样,如果一个循环的循环分支计数超过了之前已经指定的临界值(基于编译临界值),那么也会认定它为性能关键的。如果循环边计数超过它的临界值,那么只有那个循环是编译过的。针对循环的编译优化被称为栈上替换(OSR),因为JVM是在栈上替换编译的代码的。
OpenJDK HotSpot VM有两个不同的编译器,每个都有它自己的编译临界值:
- 客户端或C1编译器,它的编译临界值比较低,只是1500,这有助于减少启动时间。
- 服务端或C2编译器,它的编译临界值比较高,达到了10000,这有助于针对性能关键的方法生成高度优化的代码,这些方法由应用的关键执行路径来判定是否属于性能关键方法。
分层编译的五个层次
通过引进分层编译,OpenJDK HotSpot VM 用户可以通过使用服务端编译器改进启动时间获得好处。分层编译有五个编译层次。在第0层(解释层)启动,仪表在这一层提供了性能关键方法的信息。很快就会到达第1层,简单的C1(客户端)编译器,它来优化这段代码。在第一层没有性能优化的信息。下面来到第2层,在此只有少数方法是编译过的(再提一下是通过客户端编译器)。在第2层,为这些少数方法针对进入次数和循环分支收集性能分析信息。第3层将会看到由客户端编译器编译的所有方法及其全部性能优化信息,最后的第4层只对C2自身有效,是服务端编译器。
分层编译器以及代码缓存的效果
当使用客户端编译(第2层之前)时,代码在启动期间通过客户端编译器予以优化,此时关键执行路径保持预热。这有助于生成比解释型代码更好的性能优化信息。编译的代码存在在一个称为“代码缓存”的缓存里。代码缓存有固定的大小,如果满了,JVM将停止方法编译。
分层编译可以针对每一层设定它自己的临界值,比如-XX:Tier3MinInvocationThreshold, -XX:Tier3CompileThreshold, -XX:Tier3BackEdgeThreshold。第三层最低调用临界值为100。而未分层的C1的临界值为1500,与之对比你会发现会非常频繁地发生分层编译,针对客户端编译的方法生成了更多的性能分析信息。于是用于分层编译的代码缓存必须要比用于不分层的代码缓存大得多,所以在OpenJDK中用于分层编译的代码缓存默认大小为240MB,而用于不分层的代码缓存大小默认只有48MB。
如果代码缓存满了,JVM将给出警告标识,鼓励用户使用 –XX:ReservedCodeCacheSize 选项去增加代码缓存的大小。
理解编译
为了可视化什么方法会在何时得到编译,OpenJDK HotSpot VM提供了一个非常有用的命令行选项,叫做-XX:+PrintCompilation,它会报告什么时候代码缓存满了,以及什么时候编译停止了。
举例如下:
567 693 % ! 3 org.h2.command.dml.Insert::insertRows @ 76 (513 bytes) 656 797 n 0 java.lang.Object::clone (native) 779 835 s 4 java.lang.StringBuffer::append (13 bytes)
上面的输出格式为:
timestamp compilation-id flags tiered-compilation-level class: method <@ osr_bci> code-size <deoptimization>
在此,
timestamp(时间戳) 是JVM开始启动到此时的时间
compilation-id(编译器id) 是内部的引用id
flags(标记) 可以是以下其中一种:
%: is_osr_method (是否osr方法@ 针对OSR方法表明字节码)
s: is_synchronized(是否同步的)
!: has_exception_handler(有异常处理器)
b: is_blocking(是否堵塞)
n: is_native(是否原生)
tiered-compilation(分层的编译器) 表示当开启了分层编译时的编译层
Method(方法) 将用以下格式表示类和方法 类名::方法
@osr_bci(osr字节码索引) 是OSR中的字节码索引
code-size(代码大小) 字节码总大小
deoptimization(逆优化)表示一个方法是否是逆优化,以及不会被调用或是僵尸方法(更多详细内容请见“动态逆优化”一节)。
基于以上关键字,我们可以断定例子中的第一行
567 693 % ! 3 org.h2.command.dml.Insert::insertRows @ 76 (513 bytes)
的timestamp是567,compilation-ide是693。该方法有个以“!”标明的异常处理器。我们还能断定分层编译处于第3层,它是一个OSR方法(以“%”标识的),字节码索引为76。字节码总大小为513个字节。请注意513个字节是字节码的大小而不是编译码的大小。
示例的第2行显示:
656 797 n 0 java.lang.Object::clone (native)
JVM使一个原生方法更容易调用,第3行是:
779 835 s 4 java.lang.StringBuffer::append (13 bytes)
显示这个方法是在第4层编译的且是同步的。
动态逆优化
我们知道Java会做动态类加载,JVM在每次动态类加载时检查内部依赖。当不再需要一个之前优化过的方法时,OpenJDK HotSpot VM将执行该方法的动态逆优化。自适应优化有助于动态逆优化,换句话说,一个动态逆优化的代码应恢复到它之前编译层,或者转到新的编译层,如下图所示。(注意:当在命令行中开启PrintCompilation时会输出如下信息):
573 704 2 org.h2.table.Table::fireAfterRow (17 bytes) 7963 2223 4 org.h2.table.Table::fireAfterRow (17 bytes) 7964 704 2 org.h2.table.Table::fireAfterRow (17 bytes) made not entrant 33547 704 2 org.h2.table.Table::fireAfterRow (17 bytes) made zombie
这个输出显示timestamp为7963,fireAfterRow是在第4层编译的。之后的timestamp是7964,之前在第2层编译的fireAfterRow没有进入。然后过了一会儿,fireAfterRow标记为僵尸,也就是说,之前的代码被回收了。
理解内联
自适应优化的最大一个好处是有能力内联性能关键的方法。通过把调用替换为实际的方法体,有助于规避调用这些关键方法的间接开销。针对内联有很多基于规模和调用临界值的“协调”选项,内联已经得到了充分地研究和优化,几乎已经挖掘出了最大的潜力。
如果你想投入时间看一下内联决策,可以使用一个叫做-XX:+PrintInlining的JVM诊断选项。在理解决策时 PrintInlining 会提供很大的帮助,示例如下:
@ 76 java.util.zip.Inflater::setInput (74 bytes) too big @ 80 java.io.BufferedInputStream::getBufIfOpen (21 bytes) inline (hot) @ 91 java.lang.System::arraycopy (0 bytes) (intrinsic) @ 2 java.lang.ClassLoader::checkName (43 bytes) callee is too large
在这里你能看到该内联的位置和被内联的总字节数。有时你看到如“too big”或“callee is too large”的标签,这表明因为已经超过临界值所以未进行内联。第3行的输出信息显示了一个“intrinsic”标签,让我们在下一节详细了解一下intrinsics(内部函数)。
内部函数
通常OpenJDK HotSpot VM 即时编译器将执行为性能关键方法生成的代码,但有时有些方法有非常公共的模式,比如java.lang.System::arraycopy,如前一节中 PrintInlining 输出的结果。这些方法可以得到手工优化从而形成更好的性能,优化的代码类似于拥有你的原生方法,但没有间接开销。这些内部函数可以高效地内联,就像JVM内联常规方法一样。
向量化
讨论内部函数的时候,我喜欢强调一个常用的编译优化,那就是向量化。向量化可用于任何潜在的平台(处理器),能处理特殊的并行计算或向量指令,比如“SIMD”指令(单指令、多数据)。SIMD和“向量化”有助于在较大的缓存行规模(64字节)数据量上进行数据层的并行操作。
HotSpot VM提供了两种不同层次的向量支持:
- 为计数的内部循环配备桩;
- 针对自动向量化的超字级并行(SLP)支持。
在第一种情况下,在内部循环的工作过程中配备的桩能为内部循环提供向量支持,而且这个内部循环可以通过向量指令进行优化和替换。这与内部函数是类似的。
在HotSpot VM中SLP支持的理论依据是 MIT实验室的一篇论文 。目前,HotSpot VM只优化固定展开次数的目标数组,Vladimir Kozlov举了以下一个示例,他是Oracle编译团队的资深成员,在各种编译器优化作出了杰出贡献,其中就包括自动向量化支持。
a[j] = b + c * z[i]
如上代码展开之后就可以被自动向量化了。
逃逸分析
逃逸分析是自适应优化的另一个额外好处。为判定任何内存分配是否“逃逸”,逃逸分析(缩写为EA)会将整个中间表示图考虑进来。也就是说,任意内存分配是否不在下列之一:
- 存储到静态域或外部对象的非静态域
- 从方法中返回;
- 作为参数传递到另一个逃逸的方法
如果已分配的对象不是逃逸的,编译的方法和对象不作为参数传递,那么该内存分配就可以被移除了,这个域的值可以存储在寄存器中。如果已分配的对象未逃逸已编译的方法,但作为参数传递了,JVM仍然可以移除与该对象有关联的锁,当用它比对其他对象时可以使用优化的比对指令。
其他常见的优化
还有一些自适应即时编译器一起带来的一些其他的OpenJDK HotSpot VM优化:
- 范围检查消除——如果能保证数组索引永远不会越界的话,那么在JVM中就不一定必须要检查索引的边界错误了。
- 循环展开——通过展开循环有助于减少迭代次数。这能使JVM有能力去应用其他常见的优化(比如循环向量化),无论哪里需要。
关于作者
 Monica Beckwith,Java/JVM 性能咨询专家,前 Oracle G1 垃圾收集器性能团队 Leader,目前是一位独立咨询师,专注于企业级应用中 Java 虚拟机和垃圾收集器的优化。她发表过很多垃圾收集器和 Java 内存模型方面的文章。之前就职于 Oracle,带领 G1 垃圾收集器性能团队。2013 年 JavaOne 大会明星讲师。你可以通过推特@mon_beck与她取得联系。
Monica Beckwith,Java/JVM 性能咨询专家,前 Oracle G1 垃圾收集器性能团队 Leader,目前是一位独立咨询师,专注于企业级应用中 Java 虚拟机和垃圾收集器的优化。她发表过很多垃圾收集器和 Java 内存模型方面的文章。之前就职于 Oracle,带领 G1 垃圾收集器性能团队。2013 年 JavaOne 大会明星讲师。你可以通过推特@mon_beck与她取得联系。
查看英文原文: What the JIT!? Anatomy of the OpenJDK HotSpot VM
正文到此结束
热门推荐








相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

