超越Spark100倍性能?!不科学呀,它是什么鬼?
2004年,Google的MapReduce论文揭开了大数据处理的时代,现如今,大数据的发展已达到惊人的速度,大数据技术深刻改变了世界。与此同时,各大数据库厂商在大数据这片蓝海里都想多分一杯羹,于是乎,各种数据库开发技术如雨后春笋般孕育而出。
众所周知,大数据技术纷杂繁多,而Spark、Hive、Tez、RapidsDB这几款却深受开发者青睐,谈其性能各有千秋:
- Spark是由UC Berkeley AMP Lab所开源的类Hadoop MapReduce的通用并行框架, 其拥有Hadoop MapReduce所具有的优点, 并且能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能,其本质是将SQL转换为MapReduce程序。
- Tez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。
- RDP(Rapids Data Platform)是一个实时大数据分析领域的高性能分析应用平台。RapidsDB采用了内存计算(In-Memory Computing)技术。
正所谓萝卜青菜各有所爱,今天我们就来评测下深受开发者喜爱的Spark、Hive、Tez、RapidsDB将会带来哪些惊人的测试效果。本次评测旨在为数据库相关从业人员提供一个技术参考方向。
本次测试基于某证交所复杂的交易分析;测试场景包括: Hive1.2,Tez0.83,RapidsDB2.63,Spark 1.6。
测试结果如下:
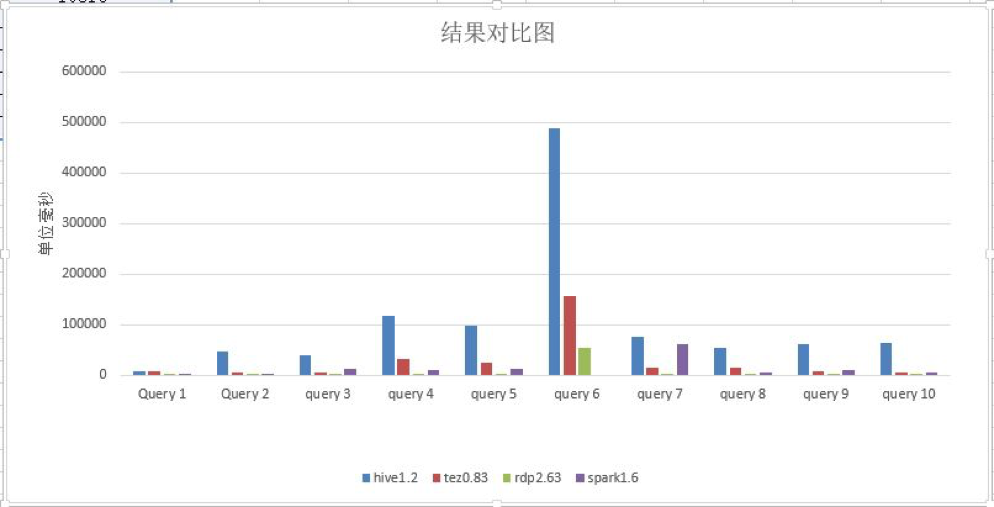
注:蓝色代表Hive、红色代表Tez、绿色代表RDP(RapidsDB)、紫色代表Spark。
从图表上可以看出,Hive在所有查询中耗时都比较长;Tez次之;Spark位居第三;令笔者惊奇的是,RapidsDB的表现则最优。
笔者曾听闻,有人宣称Spark是大数据的未来,更有Spark一出,Hadoop已死的说法,然而在此次评测过程中,Spark却被后起之秀RapidsDB秒杀,实则让人唏嘘不已!
下面我们来看下详细的测试环境:

可以看出,各测试环境随着查询节点的不同,表现能力也各不相同。比如:在Query 1查询时,Hive 1.2用时8576ms,Tez 0.83用时844ms,Spark-SQL 1.6用时1520ms;令人惊奇的是,RDP(RapidsDB)2.63仅用了2ms。
笔者还注意到,在Query6查询时分值达到最高,但不难看出,依然是RapidsDB拔得头筹。
再来看下Query10,请注意,该时段的查询是基于某段时间内满足程序化交易标准的用户,并且必须满足以下情形之一:(1)一个交易日内出现五次以上每秒申报五笔;(2)一秒内完成申报并撤销申报,且日内出现三次以上;(3)日内申报两千币以上;其中含有交易金额、交易笔数,涉及多表复杂关联查询,使用聚合函数汇总、分组排序等,数据量均在百万级别之上。值得一提的是,在Query10查询过程中,Hive 、Tez、 Spark速度几乎持平;但RapidsDB这匹黑马却只用了1ms,完全秒杀其他测试环境。从数据上可以看出,RapidsDB对SQL查询语句、性能解析方面达到最佳。
由此,我们可以预想到,RapidsDB的性能不容小觑,将来RapidsDB的人气将会越来越高,
那么耗时最快的RapidsDB(RDP)是什么鬼?
RDP(Rapids Data Platform)是由柏睿数据公司推出的一款专注于实时分析和应用的先进平台。其包含四大模块:Rapids Hadoop(企业版大数据存储管理引擎)、Rapids DB(分布式实时在线处理引擎)、Rapids MGrid(分布式内存分析引擎)、Rapids Manager(统一的管理控制台)。
其中,RapidsDB内存计算是一项具有突破性的技术,它对那些非汇总的大数据的分析速度是惊人的(相对磁盘数据库)。这项技术的主要功能是在内存当中来存储需要持久化的数据,可以压缩并存储大量数据在主存中。该技术利用英特尔多核并行处理硬件优势将数据的复杂计算从应用层移到数据库层从而大大加快了处理的速度。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

