深度学习在2016年都有哪些主要研究进展?(附开源平台地址)| 盘点
在过去的几年时间里,深度学习(Deep Learning)一直都是机器学习社区的核心主题, 2016年也不例外。
研究人员长久以来亟待解决的一个主要挑战就是无监督学习(Unsupervised Learning)。Tryolabs 认为,2016 年对于这一领域来说是取得伟大突破的一年,主要原因是出现了大量的基于生成模型(Generative Models)的研究。此外,雷锋网会介绍自然语言处理(NLP)技术在 2016 年所取得的创新,这些技术会是实现该目标的关键。除了回顾那些推动该领域快速向前发展做出突出贡献(或有极大潜力)的进步,雷锋网 (公众号:雷锋网) 也将关注相关组织机构和开源平台的建设情况。
一、无监督学习
无监督学习是指不需要额外信息就能从原始数据中提取模式和结构的任务,这点和需要建立标签的监督学习相反。
使用神经网络解决这个问题的经典方法是自动编码器。基本版本由多层感知器(MLP)组成,其中输入和输出层具有相同的大小,还有一个较小的隐藏层被训练用于恢复输入层。一旦经过训练,隐藏层就能对应输出可用于聚类,降维,改进监督分类甚至数据压缩的数据表示。
而在其中,
1. 生成式对抗网络(GANs)
最近一种基于生成模型的新方法出现了,名为“生成式对抗网络”(GANs),它能够使用模型来处理无监督学习问题。GANs 将是一场真正的革命,在相关的技术演讲中,Yann LeCun(深度学习创始人之一)说 GANs 是过去 20 年里机器学习最重要的想法。
尽管 GANs 早在 2014 年由 Ian Goodfellow 提出,但直到 2016 年,GANs 才开始展现出真正的潜能。今年提出的可助于训练和优化架构(Deep Convolutional GAN)的改进技术修复了一些之前的限制,并且新的应用程序(详见下文,部分相关应用名单)揭示了该项技术能够如何的强大和灵活。
-
一个直观的例子
试想一位有野心的画家想要伪造艺术作品(G),同时又有人以鉴别画作真假谋生(D)。开始你先给D看一些毕加索的艺术作品。然后G每次都画一些作品尝试着骗过D,让他相信这些都是毕加索的原作。开始时候G是成功的,但是随着D越来越了解毕加索的风格(通过看越来越多的作品),G再想骗过D就会变得困难起来,所以G就必须做得更好。随着过程的继续,不仅D变得非常擅长区分毕加索的作品,而且G也变得非常善于模仿毕加索的画作。这就是GANs背后的设计思路。
技术上,GANs由两个持续推动的网络组成(因此称为“对抗”):发生器(G)和鉴别器(D)。给定一组训练示例(例如图像),我们可以想象有一个离散基本分布(X)来管理它们。 通过使用GANs,G将产生输出,同时D将判定它们是否来自于训练集合的同一分布。
开始时,伴随着一些噪声Z,G开始工作,其产生的图像是G(z)。D从真的分布和来自于G的假分布中提取图像,并将它们分类为:D(x)和D(G(z))。
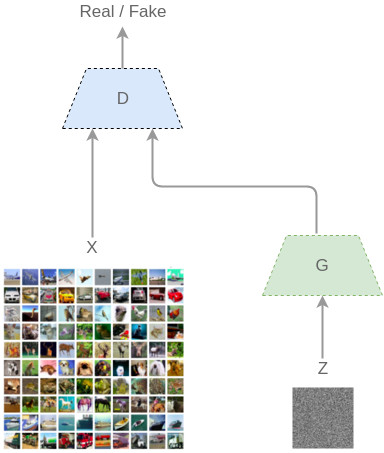
GAN是如何工作的
D和G都在同时学习,并且一旦G被训练,它就能足够了解训练实例的分布,产生有非常相似属性的新示例:

GAN生成的图像
这些图像由采用CIFAR-10训练的GAN产生的。 如果你注意一下细节,你可以看到它们不是真实物体。 但是,通过捕捉某些确定的特征属性,可以使它们从远处看起来很真实。
2. InfoGAN——数据集信息的描述模型
最近的进展延伸了GAN的思想,不仅可用于近似数据分布,也能学习可解释的、有用的数据向量表示。这些期望的向量表示需要捕获丰富的信息(与自动编码器中相同),并且也需要是可解释的,这意味着我们可以区分向量的某些部分,这些部分可使所生成的输出中的存在特定类型的形状变换。
OpenAI研究人员在8月提出的InfoGAN模型解决了这个问题。 简而言之,InfoGAN能够以无监督的方式生成包含有关数据集信息的表示。 例如,当被应用于MNIST数据集时,能够推断所生成样本的数量类型(1,2,3,...),例如生成样本的旋转和宽度,均不需要人工标记数据。
3. 条件 GAN——先验知识的引入
GAN的另一扩展是一类被称为条件GAN(cGAN)的模型。 这些模型能够输入外部信息(类标签,文本,另一个图像)生成样本,使用它强制G生成特定类型的输出。 最近出现的一些应用程序是:
-
文本描述作为先验生成图像
采用文本描述(由字符级的 CNN 或 LSTM 将其编码为向量)作为外部信息,然后基于它生成图像。详见论文:Generative Adversarial Text to Image Synthesis(2016年6月)。

-
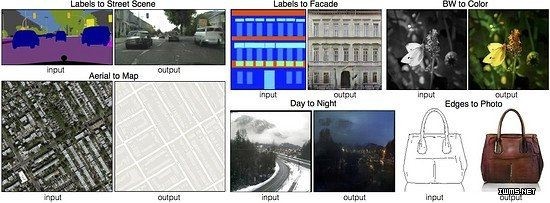
图像信息作为先验生成图像
将输入图像映射到输出图像。详见论文:Image-to-Image Translation with Conditional Adversarial Nets (2016年11月)。
-
下采样图像生成超分辨率图像
它采用下采样图像(更少细节),生成器试图将它们处理为更自然的视觉图像。看过CIS的读者应该知道我们在谈论的话题。详见论文:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (2016年11月)。

你可以在这篇文章或 Ian Goodfellow 的演讲中查看关于生成模型的更多信息。
二、自然语言处理(NLP)
为了能够和机器流畅地对话,首先要解决几个问题,例如:文本理解、提问回答和机器翻译。
1. 语义理解
Salesforce MetaMind建立了一个称为 Joint Many-Tasks(JMT)的新模型,目标是要创造出一个可以学习五个常见自然语言处理任务的模型:
-
词性标记(Part-of-speech tagging)
对句子中的每个词分配合适的词性,比如说名词、动词、形容词等。
-
词块分析(Chunking)
也称作浅层句法分析(shallow parsing),涉及到一系列的任务,像是查找名词或动词词组。
-
依存句法分析(Dependency parsing)
识别词语之间的语法关系 (比如说形容词修饰名词)。
-
语义关联性(Semantic relatedness)
衡量两个句子之前的语义相关程度。结果采用一个实值分数来表示。
-
文字蕴涵(Textual entailment)
确定前提的句子是否包含一个假设语句。可能出现的句子类别有:蕴含、矛盾和中立。
这个模型背后的神奇之处是它具有端到端的可训练性。 这意味着它允许不同层之间协同工作,从而改善低层任务(这些任务并不复杂),并从高层任务(更复杂的任务)中得到结果。 与旧的思路相比,这是一个新东西,旧想思路只能使用低层任务来改善高层任务。最终,该模型在除了词性标记之外,均取得了很好的成绩。
2.智能应答
MetaMind 同样提出了一个新的被称为 Dynamic Coattention Network (DCN)的模型来解决问答问题,该模型建立在相当直观的基础之上。
想象一下,我要给你一段长文章,并且问你一些问题。 您喜欢先读文章,然后被问问题,还是在开始阅读之前被给出问题? 当然,提前知道问题,你就能有选择的注意答案。 如果不这样,你就不得不将注意力平均分配并且记下与可能的问题相关的每个细节。
DCN也做同样的事情。 首先,它生成文档的内部表示,基于文本并且由系统将要回答的问题做为约束条件,然后就是按照可能的回答列表迭代,直到收敛到最后的回答。
3. 机器翻译
今年九月,谷歌发布了用于翻译服务的新模型,谷歌神经网络机器翻译系统(Google Neural Machine Translation (GNMT)),这个系统是由如英-汉那样独立的语言对单独训练的。雷锋网最近全文编译了关于谷歌大脑的介绍,实际上就是对这个团队研发过程的详细解析。
在 11 月份,新的 GNMT 系统发布了。新的系统更进一步,通过单一模型便能实现多语言对互译。现在 GNMT 系统与以前唯一不同之处就是它采用了能指定目标语的新型输入方法。它同样能够进行 zero-shot translation,这就意味着它能够翻译一对没有训练过的语言。
GNMT 系统表明了基于多语言对的训练要比单语言对的训练效果好得多,这也证明了从一种语言对把“翻译知识”迁移到另一种语言对是可行的。
三、开源平台及组织
一些公司和企业已经建立起非营利性伙伴关系进而讨论机器学习的未来,来确保这些令人印象深刻的技术在利于社区的前提下正确使用。
OpenAI 成立于2015年末,目的是建立学界和工业界之间的合作关系,并免费公开其研究成果。该组织于2016年开始首次发表它的研究结果(通过 InfoGAN 出版刊物、Universe 平台、this one会议)。该组织的目标是确保人工智能技术能面向尽可能多的用户,而且通过研究进展的跟进,了解是否会出现超人工智能。
另一方面,亚马逊、DeepMind、谷歌、Facebook、IBM 和微软还在人工智能方面签订了合作关系,其目标是增强公众对这一领域的理解,支持实践活动和开发一个便于讨论和参与的开放平台。
该研究社区值得注意的一点是其开放性。你不仅可以在 ArXiv(或 ArXiv-Sanity)这类的网站上找到免费的几乎相关的任何出版物,还能使用同样的代码复现他们的实验。其中一个很有用的工具是 GitXiv,其将 arXiv 上的论文和它们对应的开源项目库链接到了一起。
现在,开源工具已经遍布各处,并且被研究人员和企业广泛使用和再次开发。雷锋网整理了 2016 年最受欢迎的深度学习工具,并附网址如下:
-
TensorFlow,来自谷歌,地址: https://github.com/tensorflow/tensorflow
-
Keras,来自 François Chollet,地址: https://github.com/fchollet/keras
-
CNTK,来自微软,地址: https://github.com/Microsoft/CNTK
-
MXNET,来自 DMLC,被亚马逊采用,地址: https://github.com/dmlc/mxnet
-
Theano,来自蒙特利尔大学,地址: https://github.com/Theano/Theano
-
Torch,来自 Ronan Collobert, Koray Kavukcuoglu, Clement Farabet,被 Facebook 广泛使用,地址: https://github.com/torch/torch7
四、最后的思考
现在正是参与到机器学习发展中的最佳时机。正如你所见到的,今年真是硕果累累的一年。该领域的研究发展得如此迅猛,即使想要紧跟最近的前沿趋势都变成了一件难事。但是包括雷锋网在内的所有人都应该感到幸运。只要愿意,人人都可以接触到人工智能技术。
Via tryolabs
【招聘】雷锋网坚持在人工智能、无人驾驶、VR/AR、Fintech、未来医疗等领域第一时间提供海外科技动态与资讯。我们需要若干关注国际新闻、具有一定的科技新闻选题能力,翻译及写作能力优良的外翻编辑加入。
简历投递至 guoyixin@leiphone.com,工作地 深圳;
或投递至 wudexin@leiphone.com,工作地 北京。
雷锋网原创文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

