
大话分布式系统理论进阶(下)

分布式系统理论进阶 - Paxos
《分布式系统理论基础 - 一致性、2PC和3PC》 一文介绍了一致性、达成一致性需要面临的各种问题以及2PC、3PC模型,Paxos协议在节点宕机恢复、消息无序或丢失、网络分化的场景下能保证决议的一致性,是被讨论最广泛的一致性协议。
Paxos协议同时又以其“艰深晦涩”著称,下面结合 Paxos Made Simple 、 The Part-Time Parliament 两篇论文,尝试通过Paxos推演、学习和了解Paxos协议。
Basic Paxos
何为一致性问题?简单而言,一致性问题是在节点宕机、消息无序等场景可能出现的情况下,相互独立的节点之间如何达成决议的问题,作为解决一致性问题的协议,Paxos的核心是节点间如何确定并只确定一个值(value)。
也许你会疑惑只确定一个值能起什么作用,在Paxos协议里确定并只确定一个值是确定多值的基础,如何确定多值将在第二部分Multi Paxos中介绍,这部分我们聚焦在“Paxos如何确定并只确定一个值”这一问题上。

和2PC类似,Paxos先把节点分成两类,发起提议(proposal)的一方为proposer,参与决议的一方为acceptor。假如只有一个proposer发起提议,并且节点不宕机、消息不丢包,那么acceptor做到以下这点就可以确定一个值:
P1. 一个acceptor接受它收到的第一项提议
当然上面要求的前提条件有些严苛,节点不能宕机、消息不能丢包,还只能由一个proposer发起提议。我们尝试放宽条件,假设多个proposer可以同时发起提议,又怎样才能做到确定并只确定一个值呢?
首先proposer和acceptor需要满足以下两个条件:
-
1. proposer发起的每项提议分别用一个ID标识,提议的组成因此变为(ID, value)
-
2. acceptor可以接受(accept)不止一项提议,当多数(quorum) acceptor接受一项提议时该提议被确定(chosen)
(注: 注意以上“接受”和“确定”的区别)
我们约定后面发起的提议的ID比前面提议的ID大,并假设可以有多项提议被确定,为做到确定并只确定一个值acceptor要做到以下这点:
P2. 如果一项值为v的提议被确定,那么后续只确定值为v的提议
(注: 乍看这个条件不太好理解,谨记目标是“确定并只确定一个值”)
由于一项提议被确定(chosen)前必须先被多数派acceptor接受(accepted),为实现P2,实质上acceptor需要做到:
P2a. 如果一项值为v的提议被确定,那么acceptor后续只接受值为v的提议
满足P2a则P2成立 (P2a => P2)。
目前在多个proposer可以同时发起提议的情况下,满足P1、P2a即能做到确定并只确定一个值。如果再加上节点宕机恢复、消息丢包的考量呢?
假设acceptor c 宕机一段时间后恢复,c 宕机期间其他acceptor已经确定了一项值为v的决议但c 因为宕机并不知晓;c 恢复后如果有proposer马上发起一项值不是v的提议,由于条件P1,c 会接受该提议,这与P2a矛盾。为了避免这样的情况出现,进一步地我们对proposer作约束:
P2b. 如果一项值为v的提议被确定,那么proposer后续只发起值为v的提议
满足P2b则P2a成立 (P2b => P2a => P2)。
P2b约束的是提议被确定(chosen)后proposer的行为,我们更关心提议被确定前proposer应该怎么做:
P2c. 对于提议(n,v),acceptor的多数派S中,如果存在acceptor最近一次(即ID值最大) 接受的提议的值为v',那么要求v = v';否则v可为任意值
满足P2c则P2b成立 (P2c => P2b => P2a => P2)。
条件P2c是Basic Paxos的核心,光看P2c的描述可能会觉得一头雾水,我们通过 The Part-Time Parliament 中的例子加深理解:
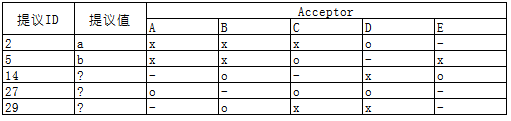
假设有A~E 5个acceptor,- 表示acceptor因宕机等原因缺席当次决议,x 表示acceptor不接受提议,o 表示接受提议;多数派acceptor接受提议后提议被确定,以上表格对应的决议过程如下:
-
ID为2的提议最早提出,根据P2c其提议值可为任意值,这里假设为a
-
acceptor A/B/C/E 在之前的决议中没有接受(accept)任何提议,因而ID为5的提议的值也可以为任意值,这里假设为b
-
acceptor B/D/E,其中D曾接受ID为2的提议,根据P2c,该轮ID为14的提议的值必须与ID为2的提议的值相同,为a
-
acceptor A/C/D,其中D曾接受ID为2的提议、C曾接受ID为5的提议,相比之下ID 5较ID 2大,根据P2c,该轮ID为27的提议的值必须与ID为5的提议的值相同,为b;该轮决议被多数派acceptor接受,因此该轮决议得以确定
-
acceptor B/C/D,3个acceptor之前都接受过提议,相比之下C、D曾接受的ID 27的ID号最大,该轮ID为29的提议的值必须与ID为27的提议的值相同,为b
以上提到的各项约束条件可以归纳为3点,如果proposer/acceptor满足下面3点,那么在少数节点宕机、网络分化隔离的情况下,在“确定并只确定一个值”这件事情上可以保证一致性(consistency):
-
B1(ß): ß中每一轮决议都有唯一的ID标识
-
B2(ß): 如果决议B被acceptor多数派接受,则确定决议B
-
B3(ß): 对于ß中的任意提议B(n,v),acceptor的多数派中如果存在acceptor最近一次(即ID值最大)接受的提议的值为v',那么要求v = v';否则v可为任意值
(注: 希腊字母ß表示多轮决议的集合,字母B表示一轮决议)
另外为保证P2c,我们对acceptor作两个要求:
-
1. 记录曾接受的ID最大的提议,因proposer需要问询该信息以决定提议值
-
2. 在回应提议ID为n的proposer自己曾接受过ID最大的提议时,acceptor同时保证(promise)不再接受ID小于n的提议
至此,proposer/acceptor完成一轮决议可归纳为prepare和accept两个阶段。prepare阶段proposer发起提议问询提议值、acceptor回应问询并进行promise;accept阶段完成决议,图示如下:
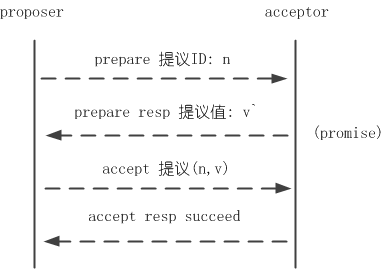
还有一个问题需要考量,假如proposer A发起ID为n的提议,在提议未完成前proposer B又发起ID为n+1的提议,在n+1提议未完成前proposer C又发起ID为n+2的提议…… 如此acceptor不能完成决议、形成活锁(livelock),虽然这不影响一致性,但我们一般不想让这样的情况发生。解决的方法是从proposer中选出一个leader,提议统一由leader发起。
最后我们再引入一个新的角色:learner,learner依附于acceptor,用于习得已确定的决议。以上决议过程都只要求acceptor多数派参与,而我们希望尽量所有acceptor的状态一致。如果部分acceptor因宕机等原因未知晓已确定决议,宕机恢复后可经本机learner采用pull的方式从其他acceptor习得。
Multi Paxos
通过以上步骤分布式系统已经能确定一个值,“只确定一个值有什么用?这可解决不了我面临的问题。” 你心中可能有这样的疑问。
其实不断地进行“确定一个值”的过程、再为每个过程编上序号,就能得到具有全序关系(total order)的系列值,进而能应用在数据库副本存储等很多场景。我们把单次“确定一个值”的过程称为实例(instance),它由proposer/acceptor/learner组成,下图说明了A/B/C三机上的实例:
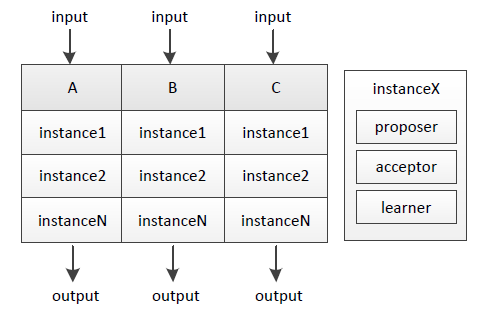
不同序号的实例之间互相不影响,A/B/C三机输入相同、过程实质等同于执行相同序列的状态机(state machine)指令 ,因而将得到一致的结果。
proposer leader在Multi Paxos中还有助于提升性能,常态下统一由leader发起提议,可节省prepare步骤(leader不用问询acceptor曾接受过的ID最大的提议、只有leader提议也不需要acceptor进行promise)直至发生leader宕机、重新选主。
小结
以上介绍了Paxos的推演过程、如何在Basic Paxos的基础上通过状态机构建Multi Paxos。Paxos协议比较“艰深晦涩”,但多读几遍论文一般能理解其内涵,更难的是如何将Paxos真正应用到工程实践。
微信后台开发同学实现并开源了一套基于Paxos协议的多机状态拷贝类库 PhxPaxos ,PhxPaxos用于将单机服务扩展到多机,其经过线上系统验证并在一致性保证、性能等方面作了很多考量。
本文提到的一些概念包括一致性(consistency)、一致性系统模型(system model)、多数派(quorum)、全序关系(total order)等,在以下文章中有介绍 :)
《分布式系统理论基础 - 一致性、2PC和3PC》
《分布式系统理论基础 - 选举、多数派和租约》
《分布式系统理论基础 - 时间、时钟和事件顺序》
《分布式系统理论基础 - CAP》
分布式系统理论基础 - 选举、多数派和租约
选举(election)是分布式系统实践中常见的问题,通过打破节点间的对等关系,选得的leader(或叫master、coordinator)有助于实现事务原子性、提升决议效率。 多数派(quorum)的思路帮助我们在网络分化的情况下达成决议一致性,在leader选举的场景下帮助我们选出唯一leader。租约(lease)在一定期限内给予节点特定权利,也可以用于实现leader选举。
下面我们就来学习分布式系统理论中的选举、多数派和租约。
选举(electioin)
一致性问题(consistency)是独立的节点间如何达成决议的问题,选出大家都认可的leader本质上也是一致性问题,因而如何应对宕机恢复、网络分化等在leader选举中也需要考量。
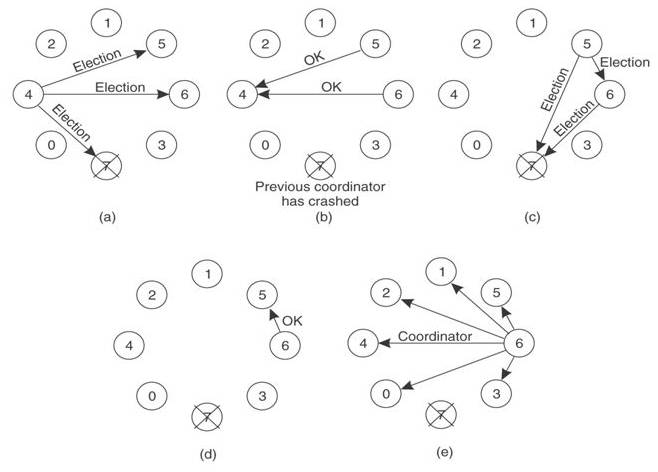
Bully算法[1]是最常见的选举算法,其要求每个节点对应一个序号,序号最高的节点为leader。leader宕机后次高序号的节点被重选为leader,过程如下:
-
(a). 节点4发现leader不可达,向序号比自己高的节点发起重新选举,重新选举消息中带上自己的序号
-
(b)(c). 节点5、6接收到重选信息后进行序号比较,发现自身的序号更大,向节点4返回OK消息并各自向更高序号节点发起重新选举
-
(d). 节点5收到节点6的OK消息,而节点6经过超时时间后收不到更高序号节点的OK消息,则认为自己是leader
-
(e). 节点6把自己成为leader的信息广播到所有节点
回顾 《分布式系统理论基础 - 一致性、2PC和3PC》 就可以看到,Bully算法中有2PC的身影,都具有提议(propose)和收集反馈(vote)的过程。
在一致性算法 Paxos 、ZAB[2]、Raft[3]中,为提升决议效率均有节点充当leader的角色。ZAB、Raft中描述了具体的leader选举实现,与Bully算法类似ZAB中使用zxid标识节点,具有最大zxid的节点表示其所具备的事务(transaction)最新、被选为leader。
多数派(quorum)
在网络分化的场景下以上Bully算法会遇到一个问题,被分隔的节点都认为自己具有最大的序号、将产生多个leader,这时候就需要引入多数派(quorum)[4]。多数派的思路在分布式系统中很常见,其确保网络分化情况下决议唯一。
多数派的原理说起来很简单,假如节点总数为2f+1,则一项决议得到多于 f 节点赞成则获得通过。leader选举中,网络分化场景下只有具备多数派节点的部分才可能选出leader,这避免了多leader的产生。

多数派的思路还被应用于副本(replica)管理,根据业务实际读写比例调整写副本数Vw、读副本数Vr,用以在可靠性和性能方面取得平衡[5]。
租约(lease)
选举中很重要的一个问题,以上尚未提到:怎么判断leader不可用、什么时候应该发起重新选举?最先可能想到会通过心跳(heart beat)判别leader状态是否正常,但在网络拥塞或瞬断的情况下,这容易导致出现双主。
租约(lease)是解决该问题的常用方法,其最初提出时用于解决分布式缓存一致性问题[6],后面在分布式锁[7]等很多方面都有应用。
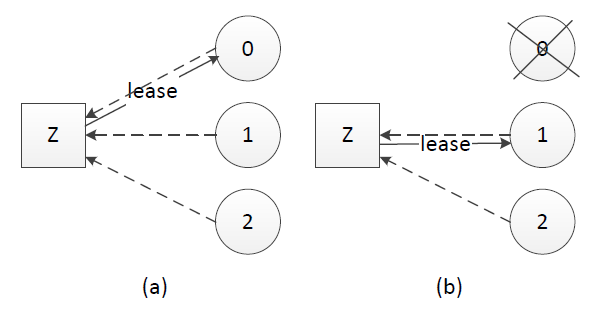
租约的原理同样不复杂,中心思想是每次租约时长内只有一个节点获得租约、到期后必须重新颁发租约。假设我们有租约颁发节点Z,节点0、1和2竞选leader,租约过程如下:
-
(a). 节点0、1、2在Z上注册自己,Z根据一定的规则(例如先到先得)颁发租约给节点,该租约同时对应一个有效时长;这里假设节点0获得租约、成为leader
-
(b). leader宕机时,只有租约到期(timeout)后才重新发起选举,这里节点1获得租约、成为leader
租约机制确保了一个时刻最多只有一个leader,避免只使用心跳机制产生双主的问题。在实践应用中,zookeeper、ectd可用于租约颁发。
小结
在分布式系统理论和实践中,常见leader、quorum和lease的身影。分布式系统内不一定事事协商、事事民主,leader的存在有助于提升决议效率。
本文以leader选举作为例子引入和讲述quorum、lease,当然quorum和lease是两种思想,并不限于leader选举应用。
最后提一个有趣的问题与大家思考,leader选举的本质是一致性问题,Paxos、Raft和ZAB等解决一致性问题的协议和算法本身又需要或依赖于leader,怎么理解这个看似“蛋生鸡、鸡生蛋”的问题?[8]
[1] Elections in a Distributed Computing System , Hector Garcia-Molina, 1982
[2] ZooKeeper’s atomic broadcast protocol: Theory and practice , Andre Medeiros, 2012
[3] In Search of an Understandable Consensus Algorithm , Diego Ongaro and John Ousterhout, 2013
[4] A quorum-based commit protocol , Dale Skeen, 1982
[5] Weighted Voting for Replicated Data , David K. Gifford, 1979
[6] Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency , Cary G. Gray and David R. Cheriton, 1989
[7] The Chubby lock service for loosely-coupled distributed systems , Mike Burrows, 2006
[8] Why is Paxos leader election no
分布式系统理论进阶 - Raft、Zab
引言
《分布式系统理论进阶 - Paxos》 介绍了一致性协议Paxos,今天我们来学习另外两个常见的一致性协议——Raft和Zab。通过与Paxos对比,了解Raft和Zab的核心思想、加深对一致性协议的认识。
Raft
Paxos偏向于理论、对如何应用到工程实践提及较少。理解的难度加上现实的骨感,在生产环境中基于Paxos实现一个正确的分布式系统非常难[1]:
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system. In order to build a real-world system, an expert needs to use numerous ideas scattered in the literature and make several relatively small protocol extensions. The cumulative effort will be substantial and the final system will be based on an unproven protocol.

Raft[2][3]在2013年提出,提出的时间虽然不长,但已经有很多系统基于Raft实现。相比Paxos,Raft的买点就是更利于理解、更易于实行。
为达到更容易理解和实行的目的,Raft将问题分解和具体化:Leader统一处理变更操作请求,一致性协议的作用具化为保证节点间操作日志副本(log replication)一致,以term作为逻辑时钟(logical clock)保证时序,节点运行相同状态机(state machine)[4]得到一致结果。Raft协议具体过程如下:
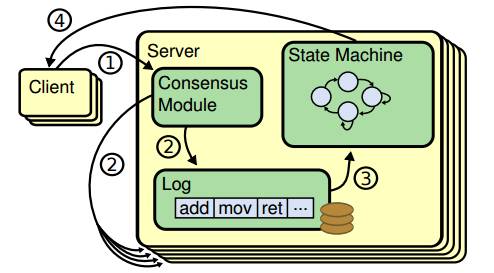
-
Client发起请求,每一条请求包含操作指令
-
请求交由Leader处理,Leader将操作指令(entry)追加(append)至操作日志,紧接着对Follower发起AppendEntries请求、尝试让操作日志副本在Follower落地
-
如果Follower多数派(quorum)同意AppendEntries请求,Leader进行commit操作、把指令交由状态机处理
-
状态机处理完成后将结果返回给Client
指令通过log index(指令id)和term number保证时序,正常情况下Leader、Follower状态机按相同顺序执行指令,得出相同结果、状态一致。
宕机、网络分化等情况可引起Leader重新选举(每次选举产生新Leader的同时,产生新的term)、Leader/Follower间状态不一致。Raft中Leader为自己和所有Follower各维护一个nextIndex值,其表示Leader紧接下来要处理的指令id以及将要发给Follower的指令id,LnextIndex不等于FnextIndex时代表Leader操作日志和Follower操作日志存在不一致,这时将从Follower操作日志中最初不一致的地方开始,由Leader操作日志覆盖Follower,直到LnextIndex、FnextIndex相等。
Paxos中Leader的存在是为了提升决议效率,Leader的有无和数目并不影响决议一致性,Raft要求具备唯一Leader,并把一致性问题具体化为保持日志副本的一致性,以此实现相较Paxos而言更容易理解、更容易实现的目标。
Zab
Zab[5][6]的全称是Zookeeper atomic broadcast protocol,是Zookeeper内部用到的一致性协议。相比Paxos,Zab最大的特点是保证强一致性(strong consistency,或叫线性一致性linearizable consistency)。
和Raft一样,Zab要求唯一Leader参与决议,Zab可以分解成discovery、sync、broadcast三个阶段:
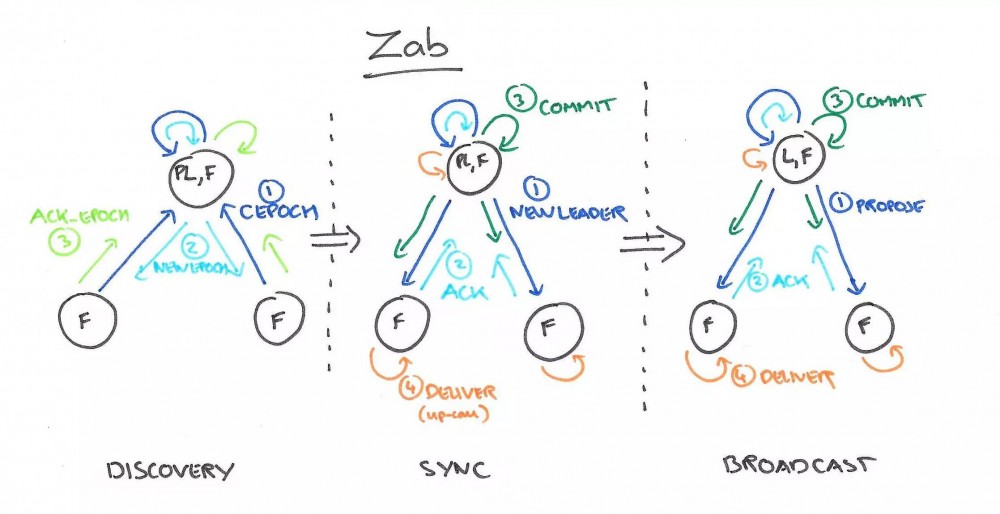
-
discovery: 选举产生PL(prospective leader),PL收集Follower epoch(cepoch),根据Follower的反馈PL产生newepoch(每次选举产生新Leader的同时产生新epoch,类似Raft的term)
-
sync: PL补齐相比Follower多数派缺失的状态、之后各Follower再补齐相比PL缺失的状态,PL和Follower完成状态同步后PL变为正式Leader(established leader)
-
broadcast: Leader处理Client的写操作,并将状态变更广播至Follower,Follower多数派通过之后Leader发起将状态变更落地(deliver/commit)
Leader和Follower之间通过心跳判别健康状态,正常情况下Zab处在broadcast阶段,出现Leader宕机、网络隔离等异常情况时Zab重新回到discovery阶段。
了解完Zab的基本原理,我们再来看Zab怎样保证强一致性,Zab通过约束事务先后顺序达到强一致性,先广播的事务先commit、FIFO,Zab称之为primary order(以下简称PO)。实现PO的核心是zxid。
Zab中每个事务对应一个zxid,它由两部分组成:<e, c>,e即Leader选举时生成的epoch,c表示当次epoch内事务的编号、依次递增。假设有两个事务的zxid分别是z、z',当满足 z.e < z'.e 或者 z.e = z'.e && z.c < z'.c 时,定义z先于z'发生(z < z')。
为实现PO,Zab对Follower、Leader有以下约束:
-
有事务z和z',如果Leader先广播z,则Follower需保证先commit z对应的事务
-
有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p先于Leader q,则Follower需保证先commit z对应的事务
-
有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p先于Leader q,如果Follower已经commit z,则q需保证已commit z才能广播z'
第1、2点保证事务FIFO,第3点保证Leader上具备所有已commit的事务。
相比Paxos,Zab约束了事务顺序、适用于有强一致性需求的场景。
Paxos、Raft、Zab再比较
除Paxos、Raft和Zab外,Viewstamped Replication(简称VR)[7][8]也是讨论比较多的一致性协议。这些协议包含很多共同的内容(Leader、quorum、state machine等),因而我们不禁要问:Paxos、Raft、Zab和VR等分布式一致性协议区别到底在哪,还是根本就是一回事?[9]
Paxos、Raft、Zab和VR都是解决一致性问题的协议,Paxos协议原文倾向于理论,Raft、Zab、VR倾向于实践,一致性保证程度等的不同也导致这些协议间存在差异。下图帮助我们理解这些协议的相似点和区别[10]:
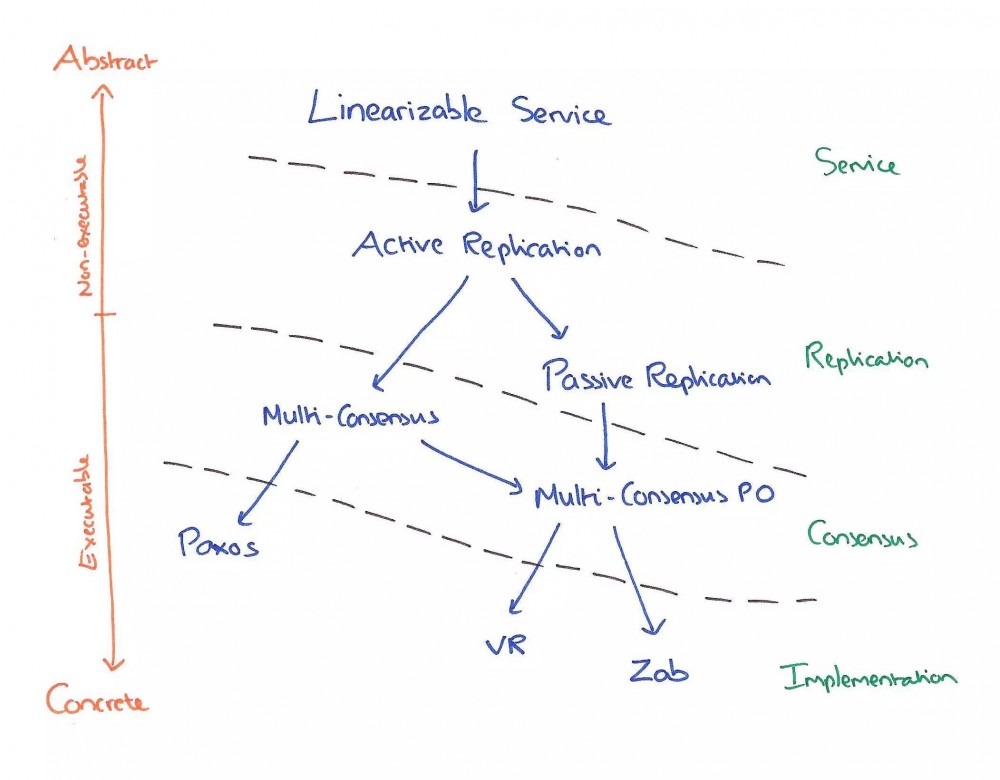
相比Raft、Zab、VR,Paxos更纯粹、更接近一致性问题本源,尽管Paxos倾向理论,但不代表Paxos不能应用于工程。基于Paxos的工程实践,须考虑具体需求场景(如一致性要达到什么程度),再在Paxos原始语意上进行包装。
小结
以上介绍分布式一致性协议Raft、Zab的核心思想,分析Raft、Zab与Paxos的异同。实现分布式系统时,先从具体需求和场景考虑,Raft、Zab、VR、Paxos等协议没有绝对地好与不好,只是适不适合。
[1] Paxos made live - An engineering perspective , Tushar Chandra, Robert Griesemer and Joshua Redstone, 2007
[2] In Search of an Understandable Consensus Algorithm , Diego Ongaro and John Ousterhout, 2013
[3] In Search of an Understandable Consensus Algorithm (Extended Version) , Diego Ongaro and John Ousterhout, 2013
[4] Implementing Fault-Tolerant Services Using the State Machine , Fred B. Schneider, 1990
[5] Zab:High-performance broadcast for primary-backup systems , FlavioP.Junqueira,BenjaminC.Reed,andMarcoSerafini, 2011
[6] ZooKeeper's atomic broadcast protocol: Theory and practice , Andr´e Medeiros, 2012
[7] Viewstamped Replication A New Primary Copy Method to Support Highly-Available Distributed Systems , Brian M.Oki and Barbar H.Liskov, 1988
[8] Viewstamped Replication Revisited , Barbara Liskov and James Cowling, Barbara Liskov and James Cowling ,2012
[9] Can’t we all just agree? The morning paper, 2015
[10] Vive La Difference: Paxos vs. Viewstamped Replication vs. Zab , Robbert van Renesse, Nicolas Schiper and Fred B. Schneider, 2014
温馨提示:
请搜索 “ICT_Architect” 或 “扫一扫” 下面二维码关注公众号,获取更多精彩内容。


正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

