基于容器的日志管理实践
2013年以来docker迅速火了起来,它的理念带来了非常大的便利性,不过实际应用中会发现还有监控、日志、网络等问题尚待解决,本文会结合实例分享数人云做容器日志系统的经验。
基于ELK的日志管理系统架构
日志收集是大数据的基础,业务平台每天产生大量日志数据,为了实现数据分析,需要将生产服务器上的所有日志收集后进行分析处理;高可用性,高可靠性以及可扩展性是日志收集系统的必备要素。
ELK是目前较流行的日志一体化解决方案,提供日志收集、处理、存储、搜索、展示等功能。容器标准输出日志常用的查询方式是通过docker命令 docker logs containerid来查看,容器内日志受容器隔离性影响不便于收集,因此当面对大型系统,用单一命令管理日志是不可行的,需要一个对于容器日志统一检索管理的方案。基于ELK实践了一套容器日志管理系统,架构如下:
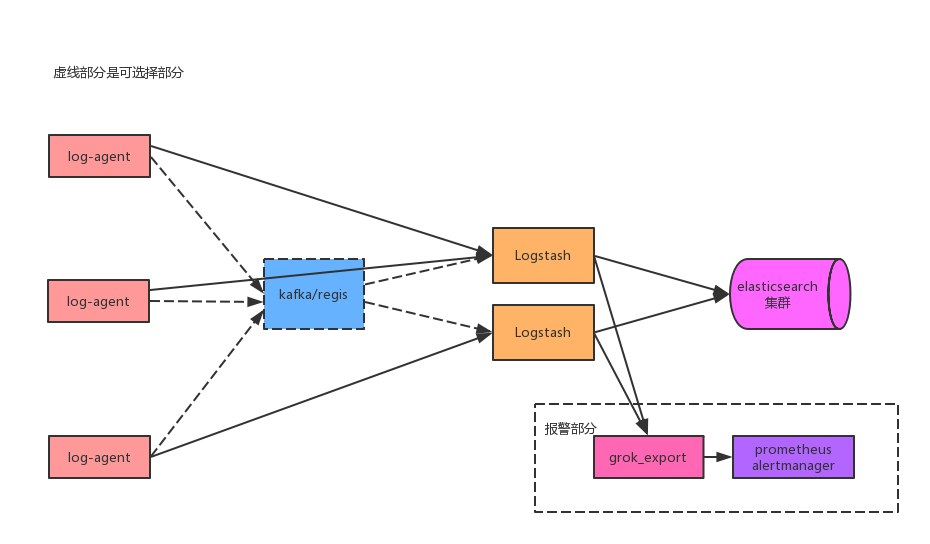
日志采集
传统的日志采集有较成熟的解决方案,如flume、logstash等,但传统的采集方案不适用于容器日志。docker本身提供了log driver功能,可以利用不同的driver把日志输出到不同地方,logdriver具体有以下几种:
• None(将日志设置成不再输出)
• json-file(docker默认的logdriver,将日志以json文件的方式存储在本地)
• Syslog(标准输出日志可通过该方式传输)
• journals
• self
• fluent
• awslogs
• splunk
• etwlogs
• gcplogs
对于这些logdriver就不一一详细介绍了,大家有兴趣可以去docker官网查看。可见docker对日志提供了较为丰富的处理方式,供选择的还有优秀的开源项目logspout等,然而这并不能满足所有的使用场景。
容器的标准输出日志可从以上驱动中选择,由于大多数用户选择标准化输出日志,故docker没有提供采集功能,如果将日志内的文件挂载出来进行采集,多个实例同名日志则会无法区分,容器内文件日志处理、错误日志多行处理等问题时有发生,若想标准输出日志和容器内文件日志兼得,则需自己动手丰衣足食,以下为数人云日志采集系统实践。
1.标准输出日志
针对marathon+mesos环境开发了一套日志采集工具,docker的标准输出日志json-file默认持久化在本地上,mesos对于标准输出日志也存了一份在sandbox下:
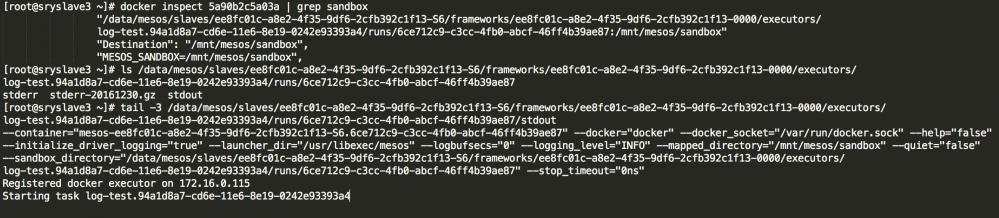
因此标准输出日志也可以通过mesos文件的方式进行采集。
2.容器内文件日志
平台支持的文件存储是overlay,避免了许多复杂环境的处理。关于overlay盗用一张图:
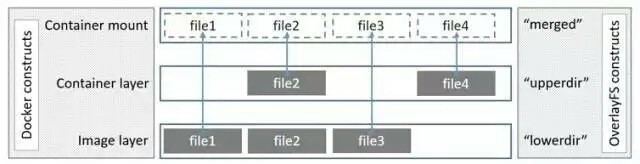
容器的存储驱动运用写时复制(Copy On Write),overlay主要分为lower和upper, 当需要修改一个文件时,使用CoW将文件从只读的lower层复制到可写层upper层进行修改,在docker中,底部的只读层是image,可写层是container,因此容器内日志在宿主机上通过upper的文件系统可找到,例如在容器内的/var/log/test.log中写一个test字符,如图:

同理,无论是标注输出的日志还是容器内文件日志,都可以通过文件的方式进行处理,也可以同时把json-file关闭,以减轻docker本身的压力。
3.自研日志采集工具
基于上述方式开发了一款日志采集工具,对日志进行统一收集管理,日志通过tcp把json格式化的日志输出到logstash,包括应用id,容器name,容器id,taskid等,当然开发的过程中也遇到许多问题,如断点续传和错误日志多行处理等功能,这其中参考了filebeat(go语言开发)对于日志处理的方式,个人认为如果是对于传统文件日志处理,filebeat是不错的选择,日志采集功能第一步支持:
• 容器标准输出日志采集
• 容器内文件日志采集,支持同时采集多个文件
• 断点续传 (如果agent崩溃,从上次offset采集)
• 多行日志合并 (如:多行错误日志合并)
• 日志文件异常处理 (如:日志被rotate可以重新采集)
• tcp传输
• --add-env --add-label标签,可以通过指定命令把container的env或者label加到日志数据里,如(--add-env hostname=HOST --add-env test=ENV_NAME1 --add-label tlabel=label_name)
• prometheus指标数据
日志处理需要提供快速的数据处理能力,在开发过程中遇到了性能问题,cpu占用非常高,针对该问题对程序作调优,使用golang内置的包net/http/pprof,对golang程序调优很好用,可将程序中每个函数占用cpu内存的比例通过生成svg的方式直观的反映出来,如图:
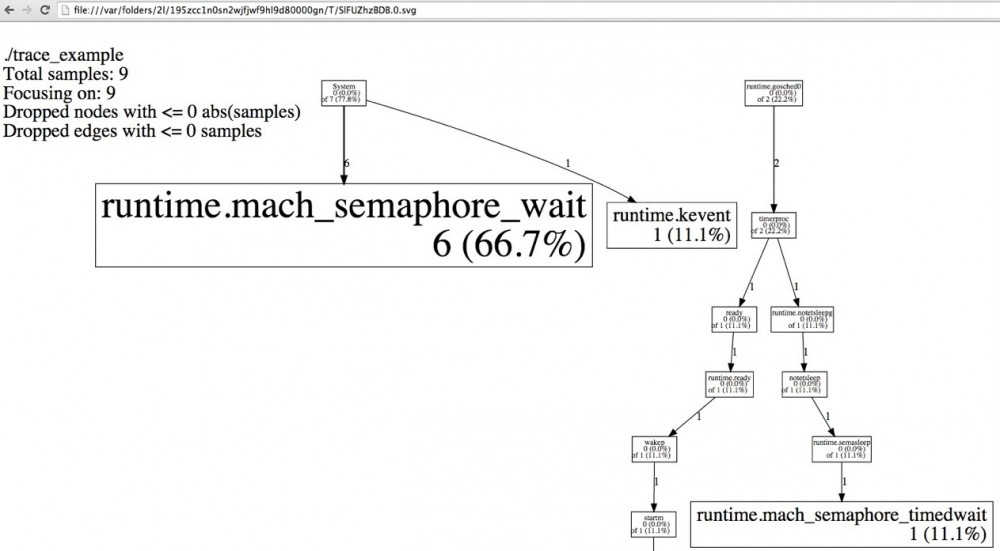
golang内置包encoding/json json的序列化、正则、反射、字节转字符串对于资源的消耗也比较高,可针对以上几方面以及程序本身进行调整。
日志存储后端架构
日志存储功能有logstash、heka、fluentd等方案,logstash基于ruby,支持功能丰富,但性能方面诟病较多;heka基于go,性能方面比logstash好很多,不过heka好像已经不维护了。综合考虑社区活跃度、迭代速度以及稳定性方面最终选择了logstash,实际应用过程中比较重要的参数如下:
• --pipeline-workers (命令行参数)
• --pipeline-batch-size (命令行参数)
• LS_HEAP_SIZE=${LS_HEAP_SIZE} (根据自己的实际情况填写,可以写到环境变量活着命令行参数里面)
• workers => 8 (根据自己实际情况,一般等于cpu数,配置文件参数)
• flush_size => 3000 (根据自己的实际情况测试)
以上参数仅供参考,可根据实际环境进行调试。如果日志量较大,为了确保架构的稳定性,可以在中间加一层消息队列,比较常用的有kafka、redis等,相信大家对这方面应用比较多,不再赘述。
es应该是索引存储的不二选择,整个架构的缓解包括es通过docker的方式部署,压测时用marvel对es的索引方式监控等,网上有很多调优资料,可自行实验。日志的展示是通过自己定制的,kibana本身的功能比较强大的同时也略微有些学习成本,最终客户想要的是很简单的东西。
压测工具选择的是分布式压测工具tsung,通过压测一个应用产生日志然后通过log-agent对日志进行采集,模拟真实环境日志采集。
日志告警
日志处理中,关键字报警是一个重要功能,对于监控报警主要用prometheus+alertmanager实现。应用运行过程中,根据日志关键字告警部的应用场景,从logstash部分对日志做分流(具体方案可以看上面图的报警部分),自研grok_export对日志进行过滤分析生成prometheus格式的数据,然后从prometheus配置报警策略通过alertmanager报警。log-agent本身也支持prometheus数据,prometheus通过特定的规则查看日志的统计信息。
• prometheus:
prometheus是开源的监控告警系统,通过pull的方式采集时间序列,以及用http传输,数据存储在本地,支持丰富的查询语法和简单的dashboard展示。
• alertmanager:
alertmanager作为prometheus的组件,所有达到阀值的时间都通过alertmanager报警,alertmanager支持非常强大的告警功能,包括http,email通知,以及静默重复报警屏蔽等功能。
以上是数人云在实践容器日志系统过程中遇到的问题,更高层次的应用包括容器日志分析等,还有待继续挖掘和填坑,欢迎大家提出建议,一起交流。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

