使用python抓取新浪微博数据
本篇文章是python爬虫系列的第四篇,介绍如何登录抓取新浪微博的信息。并对其中的关键内容进行提取和清洗。

开始前的准备工作
首先是开始之前的准备工作,与前面的文章相比,我们除了导入库文件,还把设置登录页URL,以及登录用户密码也放在了准备工作中。下面分别来说明。
导入所需的库文件,第一个是requests,用于请求和页面抓取,第二个是re正则库,用于从页面的代码中提取所需要的信息。第三个是pandas库,用来进行拼表以及数据导出。
#导入requests库(请求和页面抓取) import requests #导入正则库(从页面代码中提取信息) import re #导入pandas库(用于创建数据表和导出csv) import pandas as pd
开始抓取前,先找到新浪微博的登陆页面地址,PC端的页面内容较多,我们选择通过移动端页面登陆微博。地址是http://m.weibo.cn/,点击登陆后,跳转到登陆页面地址https://passport.weibo.cn/signin/login,这是我们要提交用户名和密码进行登陆的地址。此外还需要找到要抓取页面的URL地址。这里我们抓取“蓝鲸碎碎念”的微博首页。http://weibo.com/askcliff/home
#设置登陆用户名和密码
payload = {
'username': '用户名',
'password': '密码'}
#微博登陆页URL
url1='https://passport.weibo.cn/signin/login'
#微博内容抓取页URL
url2='http://weibo.com/askcliff/home'
准备工作完成后,还需要对爬虫进行伪装,下面是具体的步骤和内容。
将爬虫伪装成浏览器
首先是设置头文件信息,里面包括浏览器的信息和字符编码以及引荐来源信息等等。这些信息的获得方法请参考本系列第三篇文章的内容。
#设置请求头文件信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept':'text/html;q=0.9,*/*;q=0.8',
'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding':'gzip',
'Connection':'close',
'Referer':'http://www.baidu.com/'
}
设置Cookie的内容,获得cookie值的内容也请参考第三篇文章的内容。唯一的不同在于需要在登陆状态下查看cookie值并进行保存。Cookie中会保存登陆信息。
#设置Cookie的内容
cookie={'ALF':'1512025918',
'Apache':'5582079329023.459.1480472083206',
'SCF':'AoVcrse87P6zmMtZKsEug5bAAo_H6Zt17MI3RlrtRpA4qlvNTTnENdzBgdAiYtXpxqNqfUnrc4z9taUndzaGr9c.',
'SINAGLOBAL':'2194771417416.632.1423499773609',
'SSOLoginState':'1480472583',
'SUB':'_2A251OgvvDeTxGedI61YV-C_EyD6IHXVWTnonrDV8PUNbmtANLRXfkW-bhQmK-cEZIcxdomJO1Yzg52KkoQ..', 'SUBP':'0033WrSXqPxfM725Ws9jqgMF55529P9D9WWgwwO53bYmTfR9ipEOyk5q5JpX5K2hUgL.Fo2cehBX1h2Re0z2dJLoIEXLxKnL1KeL1-BLxK.LBozLBonLxKMLBKzL12-LxKMLBKzL12-LxK-LB.qLBo-t',
'SUHB':'02Me2StsrIXMMi',
'ULV':'1480472083473:198:8:1:5582079329023.459.1480472083206:1479779756603',
'UOR':'www.wpdaxue.com,widget.weibo.com,www.baidu.com',
'WBStorage':'2c466cc84b6dda21|undefined',
'WBtopGlobal_register_version':'e91f392a3df0305e',
'YF-Page-G0':'ee5462a7ca7a278058fd1807a910bc74',
'YF-Ugrow-G0':'3a02f95fa8b3c9dc73c74bc9f2ca4fc6',
'YF-V5-G0':'35ff6d315d1a536c0891f71721feb16e',
'_T_WM':'8519d55f44e2d02f81931ae8c417a1b1',
'__gads':'ID=3ca23266e2f80acc:T=1423541337:S=ALNI_MbTV-7G_42zCQkplHbiQUzrDs36Zg',
'_ga':'GA1.2.1810133914.1425401997',
'_s_tentry':'www.baidu.com',
'login_sid_t':'01055f2ea0a097fc1512f94fbc6b0c88',
'lzstat_uv':'1488026467799833128|3200746',
'un':'139******03',
'wvr':'6'}
设置完headers和cookie信息后,就可以开始进行登陆并抓取页面信息了。
抓取微博信息
首先设置会话对象,保证每次页面请求都能保留cookie信息,换句话说就是每次请求都是登陆状态。然后以post形式向微博的登陆页面提交用户名和密码进行登陆。登录成功后,请求真正需要抓取的页面地址,并进行内容编码。这里抓取的是”蓝鲸碎碎念”的微博首页。
#设置一个会话对象 s = requests.Session() #以post形式提交登陆用户名和密码 s.post(url=url1, data=payload, headers=headers) <Response [200]>
#提交请求获取要抓取的页面信息 r=requests.get(url=url2, cookies=cookie, headers=headers) #获取页面的内容信息 html=r.content #对页面内容进行编码 html=str(html, encoding = "UTF-8")
#查看页面内容 html

提取信息并进行数据清洗
抓取完页面后,我们使用正则对页面中的信息进行提取,这里提取两个信息,第一是用户昵称。第二是用户性别。
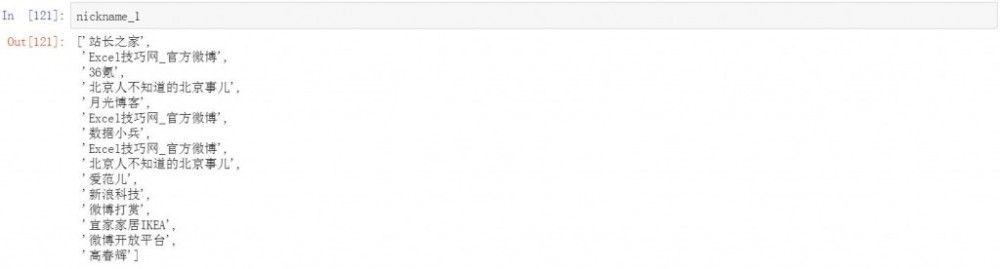
首先使用正则提取用户昵称,然后用if判断并排除重复信息,得到用户的昵称字段。
#提取微博昵称信息 nickname=re.findall(r'nickname=(.*?)//',html) #清洗微博用户昵称 nickname_1=[] for i in nickname: if not "gender" in i: nickname_1.append(i)
同样的方式提取用户性别,先使用正则提取,然后通过判断排除重复信息获得微博用户性别字段。
#提取微博用户性别 gender=re.findall(r'gender=(.*?)//"',html) #清洗微博用户性别 gender_1=[] for i in gender: if not "&" in i: gender_1.append(i)

生成数据表并导出数据
使用pandas库将微博用户昵称和性别两个字段拼成数据表。并导出为csv格式的文件,以便进行后续的统计和分析工作。
#生成数据表
weibo=pd.DataFrame({'nickname':nickname_1,'gender':gender_1})

#导出为csv文件
weibo.to_csv('weibo.csv')
—【所有文章及图片版权归 蓝鲸(王彦平)所有。欢迎转载,但请注明转自“蓝鲸网站分析博客”。】—
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

