消息消费模式
消息驱动是架构风格的一种,在转向消息驱动时候,我们会关心使用消息有什么注意事项?有什么经验模式可以借鉴?去哪儿网已经有四年多使用消息驱动架构风格构建大型交易系统的经验,现在整个交易链路基本上都是靠消息来驱动完成,在这个过程中我们也不断地的摸索前进,积累了一些消息处理的模式,而且我们还将这种模式以内置的方式提供出来,以期达到开箱即用。本文就根据过去我们使用消息驱动积累的经验总结,并结合我们内部的消息队列QMQ作为讲解示例。
consumer消费到重复消息怎么办?
消息消费模式
消息消费一般存在三种模式:最多一次,最少一次和有且仅有一次。
最多一次
这种可靠性最低,不管消费是否成功,投递一次就算完了。这种类型一般用在可靠性不高的场景中,比如我们一个对日志分析展示的场景,如果这种日志分析出现一定的缺失对业务也影响不大,那我们可以使用这种方式,这种方式性能最高(QMQ的非可靠消息)。
最少一次
基本上所有追求可靠性的消息队列都会采用这种模式。因为网络是不可靠的,要在不可靠的网络基础上构建可靠的业务,就必须使用重试来实现,那么重试就有可能引入重复的消息(QMQ的可靠消息)。
有且仅有一次
这是人们最期望的方式。也就是我如果真正的处理失败了(业务失败)你才给我重发,如果仅仅是因为网络等原因导致的超时不能给我重发消息。但是这种仅仅靠消息队列自身是很难保证的。不过借助一些其他手段,是能达到有且仅有一次的『效果』(QMQ的幂等检查)。
通过上面的描述,我们知道有且仅有一次的消息投递模式是很难达到的,那如果我们需要消息的可靠性,就必须接受重复消息这个事实。那么对于重复消息到底该怎么办呢?下面会列出一些场景和解决方案:
处理方式
不处理
这也算解决方案么?我当然不是说所有的重复消息都可以不处理的,但是是有场景是可以的。比如我们有一个缓存,数据库更新之后我们发送一条消息去将缓存删掉,等下一次数据访问的时候缓存没有命中,从数据库重新加载新数据并更新缓存。这里的消息就是删除缓存的消息,那么删除缓存这个消息就是可以接受重复消息的,这种重复消息对业务几乎没有影响(影响也是有,可能会稍微降低缓存命中率),我们权衡一下处理重复消息的成本和这个对业务的影响,那么不处理就是个最佳方案了。可能有同学说,降低缓存命中率也不行啊,还是得解决。那么我们看这个重复消息会降低多少命中率呢?那就得看重复消息多不多呢?重复消息一般是网络不稳定导致的,这在内网里这种情况其实并不常见,所以我觉得是可以接受的。
业务处理
有同学讲这不是废话么?重复消息当然是我们业务处理啊。我这里说的业务处理是说有很多业务逻辑自身就是能处理重复消息的,也就是有很多业务逻辑本来就是幂等的。这里有个题外话:即使我们不使用消息,也要尽量将我们的接口设计为幂等的。比如我们有一个创建新订单的消息,接到消息后会向数据库保存新订单。那么如果我们接到了重复订单(订单号相同),这样的订单肯定是不能保存的,但是这里切记一点,虽然最终我们不会保存两个一样的订单,但是收到重复订单的时候你就回复成功就可以了,不要抛出异常,因为抛出异常一般会认为是消息消费失败,又会重发。这在早期我们很多同学犯这个错误,就直接将DuplicateKeyException异常抛出了(其实对于接口幂等设计时也是一样,第二次重复调用的时候你返回成功的响应就行了,如果要告诉人家是重复的也在另外的字段告诉,而不是标识成功或失败响应的地方标识,这样会让请求方的处理代码更舒服些)。
去重表
如果我们不能接受重复消息,但是我们的业务逻辑自身又没办法处理重复消息该怎么办呢?那就得借助额外的手段了。也就是引入一个去重表,我们在从消息里提取一个或多个字段作为我们去重表的唯一索引,在消息处理成功的时候我们在去重表记录,如果又接到重复的消息先查去重表,如果已经成功消费过这个消息则直接返回成功就行了。而且我们还可以根据我们对去重这个事情要求的可靠等级选择将去重表建在不同的位置:数据库或redis等。放在redis里那么去重的可靠性就是redis的可靠性,一般达到99.9%应该是没有问题的,而且放在redis里我们可以设置一个过期时间,因为重复消息这个东西一般会在一个短期时间区间内发生,比如很少几个小时后甚至是几分钟后还出现重复消息。那么如果我们对可靠性要求更高则可以将去重表放在数据库里,但使用数据库成本也更高,而且数据库一般没有自动过期机制,所以可能还需要一个自动的『垃圾回收』处理机制,将多久之前的去重表里的数据删除掉。看起来引入额外的去重机制是不是很麻烦?不用担心,QMQ已经为你提供了幂等检查器这种机制,只要简单的配置一下就ok了:

上面三种方法基本上就可以解决绝大多数问题了。但是别离开,你真的以为去重就真的这么简单么?并不是。我们再来仔细看一下,假设我们收到一个消息后我们处理变更一下数据库,然后我们还要请求其他服务,如果现在的情况是我们的数据库更新成功了,但是服务请求失败了,最后引起消息重发,这该怎么办?我们能再次调用这个服务么?并不确定。所以以后如果有人给你提供服务,除了理解清楚这个服务的功能外,最重要的一点是这个服务是不是幂等的,如果不是幂等的你应该要求服务提供方提供幂等的服务,这样你好他好大家都好(幂等性是服务设计的重要原则之一)。
另外一点,如果我们的消费逻辑只涉及我自己的数据库操作,并不调用其他服务,但是因为我自己的业务逻辑不能处理重复消息,所以我要借助去重表,但是我怎么保证去重表和我的业务库操作是原子的呢?就是我的业务库操作成功了,去重表没有记录成功怎么办?这就要引入事务了。放心,QMQ已经为你考虑到了这一点提供了带事务的去重逻辑。关于QMQ的幂等检查请参照QMQ使用文档。
消息顺序
消息投递的顺序是消费者关心的第二个问题。很遗憾,实现顺序消费的成本也是非常高的,所以大多数消息队列没有提供顺序消费模式。Kafka因为它独特的存储模型,所以提供了顺序消费这种方式,但是也是有其他限制的。那么如果我要求顺序消费该怎么办呢?
处理方式
不处理
这个我就不啰嗦了,其实这个场景可以直接借用上面重复消息里的场景,删除缓存的消息先发的后到是没有多大关系的。
业务处理
和上面一样,绝大多数业务逻辑是本身就是能处理顺序的。比如我们的交易系统里有很多很多状态机,状态机有严格的状态扭转流程。比如我们的支付状态机,我们从待支付->支付完成->退款中->退款完成。那假设现在我们是待支付状态,然后用户支付后又立即申请退款,那么有可能退款中的消息比支付完成的消息先到(这种几率也是非常非常低的),这是不可以的,不满足状态机扭转条件,所以我们可以抛出异常告诉消息队列消费失败即可,等到后面支付完成的消息到达后将状态扭转为支付完成,然后等到退款中的消息到之后才将状态扭转为退款中。
额外字段
不要求严格有序
那么如果我们的系统没有状态机这种东西,靠业务逻辑不好处理顺序该怎么办呢?那我们可以借助额外的字段来处理了。一般在数据库设计中,我们都建议每个数据库表都有这样两个字段:created_time和updated_time,也就是这条数据的创建时间戳和更新时间戳。那么如果我们不要求消息严格有序的时候就可以借助updated_time字段来控制顺序了。比如我们接到一条消息,然后需要更新数据库,然后我们发现消息中携带的时间戳比我们数据库中记录的时间戳还小呢,那这条消息我不用消费了,直接返回成功就行了。使用这种方式有两个限制:1. 不要求严格有序,只要有序就可以了,中间可能少几条的更新对业务没有影响。 2. 服务器之间的时间不能出现较大的偏差(这个通过时间同步服务一般都能保障)。
严格有序
那么如果我们要求严格有序呢?就是中间不能出现缺口。那么这种就不能依靠时间戳了,那我们可以添加一个整型的version字段,消息里也携带了一个version字段,每次更新数据的时候我们采用这种更新方式(乐观锁): update tbl set ......, version=version+1 where version=@message.version。如果这条语句没有更新成功,则返回行数就不为1,这个时候我们抛出异常让消息队列重试,等到合适的消息到来的时候就会更新成功了。使用version字段这种方式可能就要producer和consumer进行协调了(其实就是有些耦合了),因为消息里也要携带version字段。但是设计这个version字段的时候也要一些考虑,我更建议的更新方式是update tbl set ......,version=@message.newversion where version=@message.oldversion。这样如果发送消息的version因为某些原因(比如有些更新并不发送消息)没有严格递增两边也可以兼容。还有一点是,要控制consumer端数据的写入点。比如我们的处理消息消费的地方更新数据外还有另外一个地方更新数据,这个地方将version给更新了,那么就会导致producer和consumer版本不一致,最后导致怎么也同步不起来了。而producer方也要控制,比如如果我们人肉直接去表里修了数据可能就没有消息发出了。
并发更新
既然说到version,这里还提一下用version来处理并发更新吧。在去哪儿有很多场景里会将数据库当做key/value存储使用,比如一个订单,我们的表设计可能是订单号,订单内容(一个结构化json),created_time, updated_time, version。我们不再使用列的方式来存储订单,至于这种方式的优点和缺点就不在本文讨论之列了。那么如果来了一条订单更新消息,我们需要对这个结构化json进行更新该怎么处理呢?会先读取这个json,然后将消息里的内容与json进行merge操作,然后将merge结果写回数据库。那如果我们在merge的过程中订单已经被更新了怎么办,这就涉及并发更新控制的问题,如果不加以控制则可能导致更新被覆盖。那我们一般采取的方式是:

这种方式就可以避免并发更新冲突覆盖的问题了,但是冲突之后怎么办呢?一般会采取重试的办法。我们会发现这种并发冲突的概率并不会很大,而且出现之后只需要重试一下基本上就可以处理了:
 我们发现这种处理方式在我们的场景中一遍又一遍的出现,那我们也将这种方式直接内置到组件之中了(NeedRetryException):
我们发现这种处理方式在我们的场景中一遍又一遍的出现,那我们也将这种方式直接内置到组件之中了(NeedRetryException):

异步处理
有的时候我们接到消息后并不是在接收消息的线程里处理消息,比如我们接到消息后会发起一个异步的服务调用,那么我们并不能立即知道这个异步服务调用的返回结果。它的返回结果是在另外的线程里,但是消息队列需要知道消息的消费结果。一般消息队列的consumer client会自动的返回消费结果,但是因为异步的方式切换了线程,所以需要应用显式的告诉结果,这就需要使用显式ack的机制了:
 但是我在与一些开发沟通过程中也发现了显式ack误用的情况:
但是我在与一些开发沟通过程中也发现了显式ack误用的情况:
1. 不管三七二十一,都自己开一个线程池,将消息丢到这个线程池里处理,然后使用显式ack。问原因,答曰开个线程池处理快些。实际上QMQ的消费者本来就是跑在一个线程池里,而且这个线程池的参数是可以通过QConfig进行热配置的。如果你的消息没有异步处理需求你就*不应该*自己开个线程池然后使用显式ack处理。
2. 使用显式ack一定一定一定要调用ack。很多时候我们程序因为各种原因,比如中途抛出异常,队列满了消息其实根本没有处理等等导致ack没有被调用。
批量处理
一般消息都是单条处理的,但是有很多时候批量处理是能提高性能的,比如数据库的批量插入相比单条插入,ES的批量更新相比单条更新等等。那么我们就需要将单条接收的消息转成批量了。转成批量的方式一般就是先将消息入一个队列,然后在队列的那头用线程批量的从队列里取消息,然后批量处理。不过批量处理也是有讲究的。
能批量就批量
这种方式是说如果我们的消费端本来就能处理好快啊,大部分时候都比生产要快,那我就没有必要还批量了。比如虽然批量插入数据库的性能是比单条快很多,但是现在消息生产的qps就只有几十,我还要等一个个批量满就没有啥必要了,但是有的时候生产速度也会快一些,那这个时候就可以批量了。这种方式能在性能和处理速度之间达到一个比较好的平衡。恭喜你,QMQ已经提供了这种处理模式了,在QMQ Client里提供了一个BatchExecutor的类,就是专门为这种场景设计的。请看示例代码:
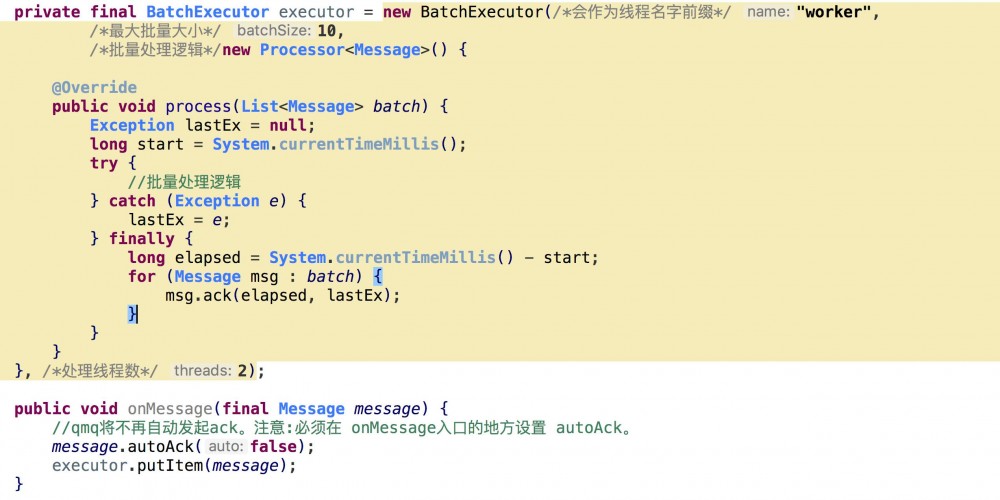
注意代码里的ack相关逻辑。BatchExecutor的特性是如果批量部分处理的慢批量就大,但是不会超过设置的最大批量大小,如果批量逻辑处理很快则可能就没有批量。
时间和批量二选一
上面介绍的BatchExecutor能在实时性和批量性能之间取得一个平衡,但平衡也不仅仅只有这一种方式。比如我们现在想通过TCP发送数据,我们知道TCP传输数据的时候除了payload以外还有一些header的,为了提高带宽利用率我们都期望让数据尽量填满每个packet,但是我们也不能为了填满packet就不顾实时性了,比如消息实在太小又太慢,可能好久才够一个packet,那我们也不能干耗着。所以我们就需要一个即有批量设置又有时间限制的批量处理功能了。也就是批量和时间这两个条件谁先达到就先满足谁。还是要恭喜你,QMQ也为你准备好了这种功能了,请看示例代码:
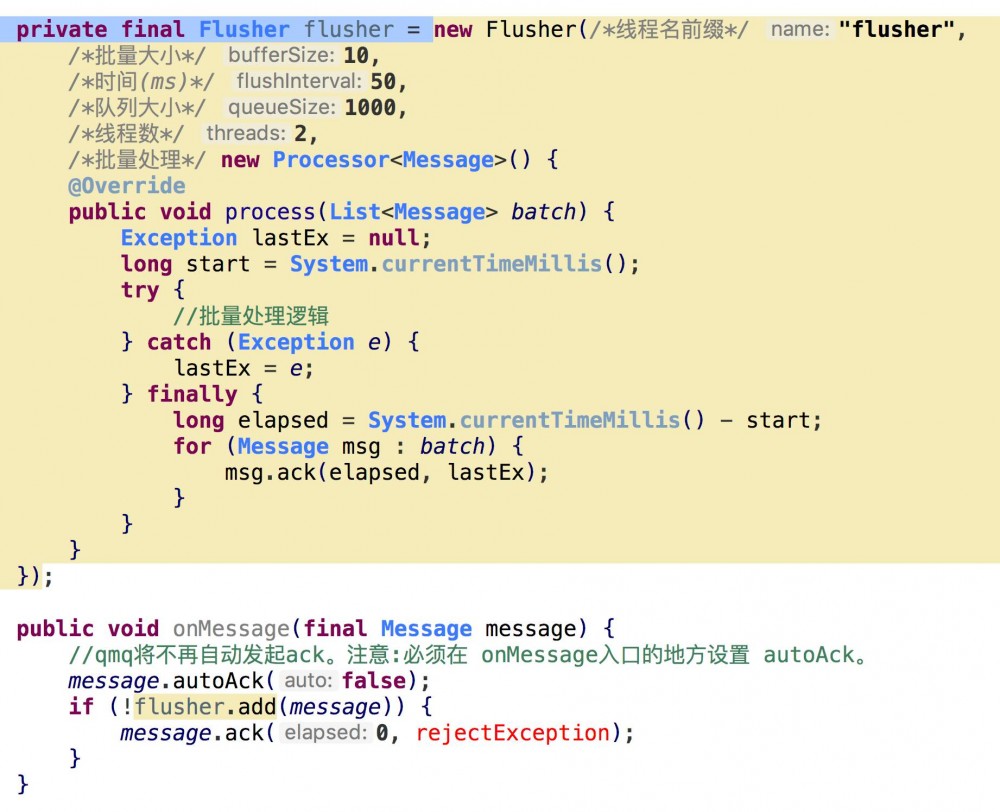
多通道批量
批量的方式其实就前面两种了,但是有的时候我们批量操作的目标可能进行了划分。比如我们进行了分库分表,那我们批量插入的时候就需要先对消息进行分组,然后不同的组批量进入不同的表。那QMQ也已经准备好了这种模式:
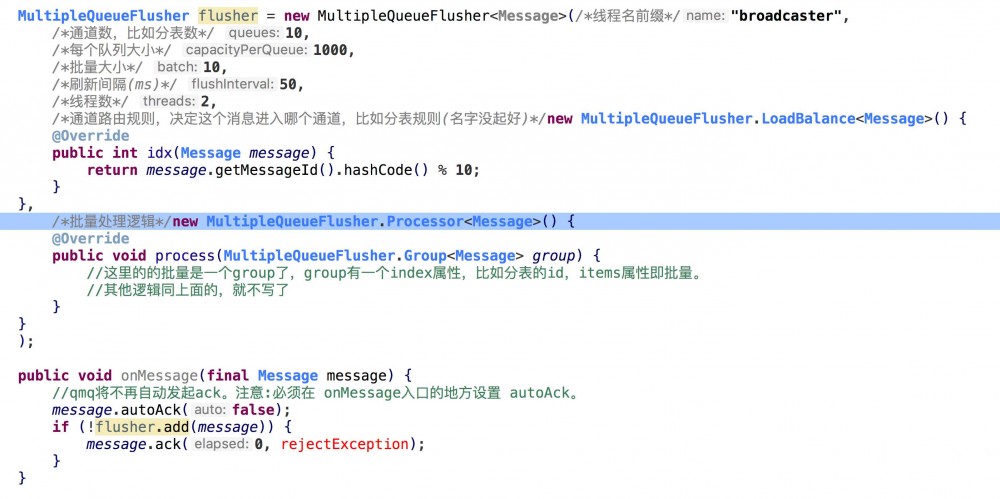
本文大致介绍了,在消费消息时候会采用的一些模式,并结合公司内部的消息队列加以举例说明,希望有些帮助。如果你还有些其他模式或疑问欢迎留言,谢谢。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

