看图测试指南——图像识别在测试中的应用
前言
也许我们使用过Uiautomator编写过自动化测试脚本,也许我们也使用过Monkey来测试过应用的稳定性。但在使用过程中总觉得有或多或小的问题,用Uiautomator写脚本,总觉得有时候控件没法识别;用Monkey来进行稳定性测试,总觉得没法复现问题……本文将使用一个新的角度(图像识别)来看待这类型的测试问题。增加一种图像识别的方法来补充Uiautomator与Monkey的限制。本文仅作为“抛砖”篇把图像应用到测试这个思路引出来,希望能引出更多的“玉”能参与其中一起研究。
二、图像识别及算法介绍
也许图像识别对于我们来说也不怎么陌生,或多或少都有所接触,但能把图像识别直接应用到我们测试工作中的同学好像并不是特别多。图像识别这名词官方的说法是“利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术”。其实说白了,图像识别重要的是“识别”二字。对于测试来说就是通过“识别”让计算机辅助我们测试,让计算机代替我们进行测试。
以下将就如何去“识别”的问题,介绍笔者在使用图像识别作为辅助工具所采用到的一些算法与算子。
2.1 SIFT算法
SIFT算法的主要方法是提取图片中物体上的一些局部外观兴趣点的特征值与特征方向。这些兴趣点的特征值与特征方向与图片的大小以及旋转角度无关、而且对光线与微视角的改变容忍度相当高,而且SIFT算法对于部分物体遮蔽的侦测率相当高,而且在当前电脑硬件的速度下,辨识速度接近即时运算。
SIFT算法的主要特点是尺度不变,也就是图片放大缩小不影响匹配、图片旋转任意角度不影响匹配、图片亮度增减不影响匹配、拍摄视角高低不影响匹配。
2.1.1 SIFT算法计算过程
由于SIFT算法计算过程涉及的数学知识比较多,本文不是主要以讲解数学知识为目的,所以计算过程只是笔者简略理解后得出的几个关键步骤。以下均为网上参考的资料。
1)图片去噪:算法采用去噪的算法是高斯模糊,先对输入图片进行一次高斯模糊处理。
2)构建高斯金字塔:高斯金字塔是把原图片经过连续变化尺度参数得到的一个图片组。
3)构建高斯差分金字塔:刚获得的模糊化后的高斯金字塔的每一层相邻两张图进行差分运算构建出差分金字塔。
4)提取空间极值点:通过对差分金字塔进行极值点分析,得到每张图的空间极值点。
5)获取主梯度方向:主梯度方向是极值点变化最大的那个方向为极值点的主梯度变化方向。
经过上述几个步骤后便可得出一张图在几个不同尺度下的特征点以及特征方向。
下图为使用KingRoot主页面运算得到的特征点位置及特征方向。其中圆的半径大小为极值大小,半径指向方向为特征方向。
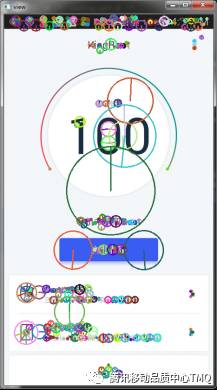
2.2 Canny算子
对于轮廓识别,有很多各种各样的算子。Canny算子的作用是:能尽可能多地表示出图像的实际边缘;标识出的边缘尽可能与实际图像的实际边缘接近;图像中边缘只能识别一次且噪声点识别为边缘。
2.2.1 Canny算子的运算过程
与SIFT算法类似,本文并不针对Canny算子很细节部分的运算过程作详细介绍,笔者根据自己的理解给出以下的计算步骤。
1)图片去噪:Canny算子使用去噪的方法跟SIFT算法一致,同样使用高斯模糊来实现。
2)获取梯度:通过计算图片中每个点各个方向的梯度来获取图像中每个点的亮度梯度,以及亮度梯度方向。
3)边缘检测:采用双阈值算法。使用高阈值过滤大部分噪点,用低阈值保留图片大部分信息。
下图为KingRoot主页以及使用Canny算子算出的轮廓信息。如图所示能把图片中大部分轮廓部分都获取到了。
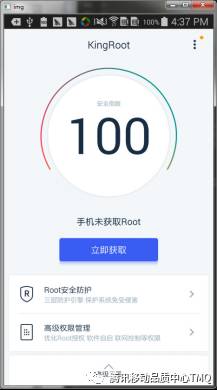

三、图像识别应用
3.1 基于图像识别的控件点击方法
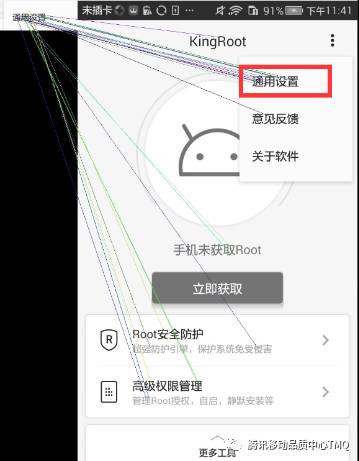
在使用Uiautomator的时候往往会遇到一个问题对于某些手机弹框是按钮并不能很好的识别,如下图。如果测试的过程中需要去点击“通用设置”按钮,实际上是没法通过Uiautomator来进行点击的。
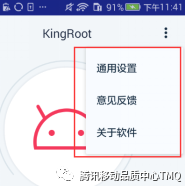
因为对于上图的弹框Uiautomator是没办法很好的识别的,如下图。整个弹框在Uiautomator的xml里面是不存在的,整个主页被识别成一个View。因此在我们测试中往往会采用坐标点击的方法来进行规避,但却衍生出适配的问题。换了一台手机分辨率变化了,脚本就没法进行了。
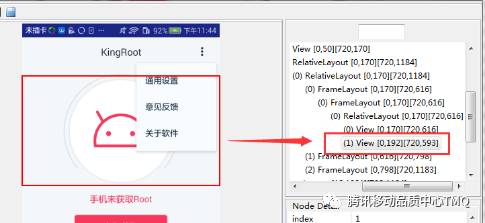
基于上述问题,广州测试组采用的是使用图像识别的方法来把“通用设置”的位置找到,并进行点击。因为SIFT算法具有尺度不变性,而且不受大小光照等方面的影响,所以可以采用它来进行匹配。具体算法的流程图如下所示。

算法主要有以下7步,即可实现对未能识别的控件进行查找点击。
1、预先把需要匹配的图片先保存起来
2、截取当前屏幕
3、SIFT算法输出目标图与屏幕截图的特征值特征变量
4、通过KNN算法进行特征值特征向量的匹配
5、把偏离比较严重的噪点去掉
6、求出点集合的中心点
7、实现点击事件
本文以点击“通用设置”为例,通过SIFT算法求出原图与屏幕截图的特征值特征向量如下图所示。可以看出两者的特征值,特征向量是相当类似的。
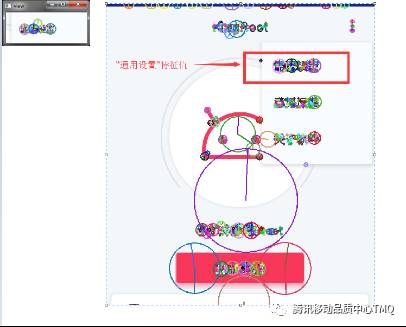
匹配的过程如下图所示,可以看出匹配到的大部分值都处在“通用设置”的位置中。
通过上述的步骤,便可获取到“通用设置”在屏幕中的位置,再实现点击则可实现点击“通用设置”的方法了。
3.2 深度遍历工测试工具
基于Canny算子与Uiautomator的深度遍历测试工具
在使用Monkey进行随机操作的时候我们会发现,很多时候Monkey不能很好的模拟人去点击有用的关键的点,从而做了无用功浪费了很多时间测试效率也不高。同时,如果在点击的过程中发现crash又不能很好的知道之前操作过的路径,复现bug尤为困难。因此笔者在考虑是否实现一个工具可以模拟小白用户进行点击操作、又能记录操作过的路径、又能在更大程度的把应用都点一遍。
基于Canny算子与Uiautomator的深度遍历测试工具其实能很好的解决以下的问题。首先介绍下这个工具的环境情况。如下图所示。主控程序在PC上运行,被控对象是手机,两者的交互的通讯是通过adb命令来进行交互。

3.2.1 工具功能
深度遍历工具的主要功能有以下几个:
1、实现随机点击功能,多点击有关键意义的点;
2、时刻检查是否在点击被测应用,如果跳出返回并继续(因为有可能在点击过程中发生应用间跳转);
3、完整记录点击的路径,能复现点击的路径;
4、每一步操作都有相应的截图,可以让测试者回看确认;
5、应用crash实现报警,及时停止运行。
3.2.2 测试工具工作流程
测试工具的工作流程图如下图所示。
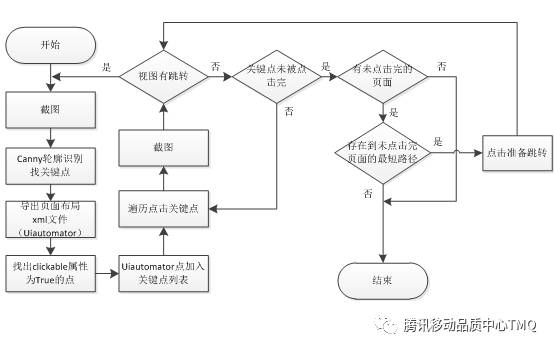
测试工具的大致流程有以下8个步骤。
1、截图取出轮廓关键点
2、取出Uiautomator布局文件,取出clickable=True的点加入关键点列表
3、依次点击关键点,并判断是否有跳转
4、有跳转则返回1,重新开始导出关键点
5、无跳转则把上一点标记为无用点,并继续点击
6、无跳转且当前页面点击完,判断是否可返回未点击完的页面
7、能返回未点击完页面则跳转返回
8、不能返回未点击完页面则退出工具
3.2.3 关键点定义
对于关键点的定义,不同测试人员有不同的见解。笔者认为关键点必须具备以下两个条件:
1、可点击的一定是关键点;
2、看上去像是可以点击且具有意义的位置。
按照这两个条件,笔者一方面把Uiautomator中clickable= True属性的点都纳入关键点,另一方面把通过Canny识别具有明确轮廓意义的点也纳入关键点,因为在笔者看来一般被轮廓包围的都或是一张完整的图片,或是一个具有完整意义的字等。
3.2.4 遍历规则
测试工具遍历点击的规则采用的是深度优先的算法,也就是每点击一步,判断是否有跳转,如果有跳转且与之前出现过的页面各不相同,则重新创建一组新的关键点组,从第一点开始遍历。如果没跳转则从下个点继续点击,直到当前再无页面跳转且当前页面的所有关键点都已经被点击过了,则进行回退步骤。判断是否跳转的标准是在点击前后分别进行图片对比,观察图片的相似度来判断,若相似度小于某个阈值(程序定义为0.8)则说明有跳转。
3.2.5 返回规则
若出现当前页面所有点都已经点击过且再无出现新的跳转页面时,工具会判断当前工程是否还有未完成点击的页面,且判断当前页面能否跳转过去。判断的准则是从当前页面按广度搜索下一级跳转的页面,如果有未完成的页面则跳转,若一级页面无跳转,则遍历二级的子页面,以此类推,直到找到一条可回退的路径。
3.2.6 路径记录
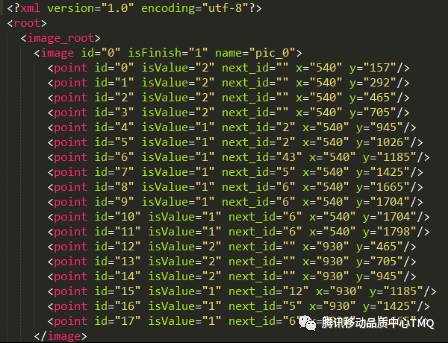
点击路径的记录有以下几个关键点需要记录到。
1、当前页面信息:包括页面id、完成状态、对应的pic的名字
2、关键点信息:包括点id、状态(未点击、点击过了)
由于xml表读写比较方便,而且易于显示,因此在记录路径的载体选择上,本工具采用的是xml作为记录的载体,具体记录的格式如下图所示。
3.2.7 实现效果
以手机管家为测试对象,笔者使用此工具,在一个晚上中遍历了大概100+的图片,每一张图片都保证是不一致的,而且能把管家一二级页面都能遍历得70%-80%,能基本实现遍历的自动化操作。
3.2.8 不足与展望
虽然能够基本遍历管家一二级页面的70%-80%,但工具依旧存在着以下不足还需要去优化解决。
1、对于需要加载的页面,加载前和加载后会被认为是两个页面。这是由于页面加载需要时间,而虽然工具每次截图之前都有一个等待时间,但对于加载过长的页面就会导致加载前后两个截图不一致被认为是两个页面。
2、运行时间过长。对于管家100+的图片是建立在遍历了11-12个小时的运行时间下的出来的,因为每次截图需要时间,等待界面跳转需要时间,而且每个页面关键点也比较多,信息如此之多因此运行的时间较长。
3、对于一些一次性页面,也就是点击同样一位置的同一按钮,首次与其他次点击进去的页面不一致的页面,由于路径表中记录了跳转的页面,因此在返回的时候就会出现对应不上的现象。
4、图像识别的方法仅能作为Uiautomator与Monkey的一个补充,解决了Uiautomator的一些限制,不能很好的完全替代Uiautomator与Monkey。
展望未来,基于图像识别的功能还是大有可为的,但却有以下可以优化的地方。
1、降低运行的时间,可以通过对界面稳定性的判断,判断当前界面稳定,不在有Loading与扫描等操作后执行跳转,这样可以减少很多无用的截图从而提高的效率
2、在图像相似度的算法的运算速度上做优化,当前比较两张图相似度需要约0.5s,所以是比较浪费时间的。优化方向一方面可以在保证效果不变的情况下减少图片的大小,另一方面采取新的计算方法加快相似度的运算。
3、优化xml文件读写的操作,由于在当前代码架构下xml会被多次重载与写入,多次I/O操作导致系统耗时比较多,因此可以减少读写的次数达到优化运行时间的目的。
四、总结
对于图像识别用于测试的路子本文仅为抛砖引玉篇,希望能在后面能在图像识别中加入机器学习与神经网络等当前热门的技术,并将其应用到测试工具的开发中。希望本文能够激发更多对图像识别的同学多思考,并将图像识别能更多的应用于工作中去。

版权所属,禁止转载
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

