Spring 数据处理框架的演变
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
定量分析的成败在很大程度上取决于采集,存储和处理数据的能力。若能及时地向业务决策者提供深刻并可靠的数据解读,大数据项目就会有更多机会取得成功。
如今,为数据处理设计合适的架构需要下很大工夫。数据处理主要包括 3 个方面:
- 批处理 :批量处理大量的静态数据。这一方式一般是分布式并且可扩展的。
- 实时处理 :实时处理主要处理连续且无尽的的数据流。这些数据流也是分布式的,且速度很快。
- 混合计算模型 :该模型是批处理和实时处理的结合,可以处理大量和高速数据。
大数据项目的工程非常耗时,并且要利用合适的技能来解决数据采集和处理的问题,因为这些问题的解决对大多数方案来说都是必不可少的。Pivotal 曾推出了 Spring XD 和 Spring Cloud Dataflow 来减少大数据工程的开销。本文将简要介绍 Spring XD,以及该技术的最新版本,即 Spring Cloud Data Flow 的各方面细节。
Spring XD
Spring XD 是第一轮技术创新的产物。它为一些常见的与数据处理有关的任务提供了一种易用的解决方案。Spring XD 建立在了历经考验的 Spring 技术之上,并为数据摄入、移动、处理、深度分析、流处理和批处理提供了支持。
Spring XD 为实时处理以及批处理提供了一个精巧、稳定,且可扩展的框架。用 Spring XD 来采集数据,并将数据从各种数据源移到目标会更加容易。
Spring XD 架构在传统企业级 ETL(数据抽取、转换与加载的流程),实时分析和数据科学项目工作台的创建中得到了广泛应用。
基于 Spring XD 的架构
下图描述了基于 Spring XD 的架构。在下图这些模块的帮助下,我们可以创建、运行、部署并销毁数据管道,并对管道中的数据进行各种各样的处理。
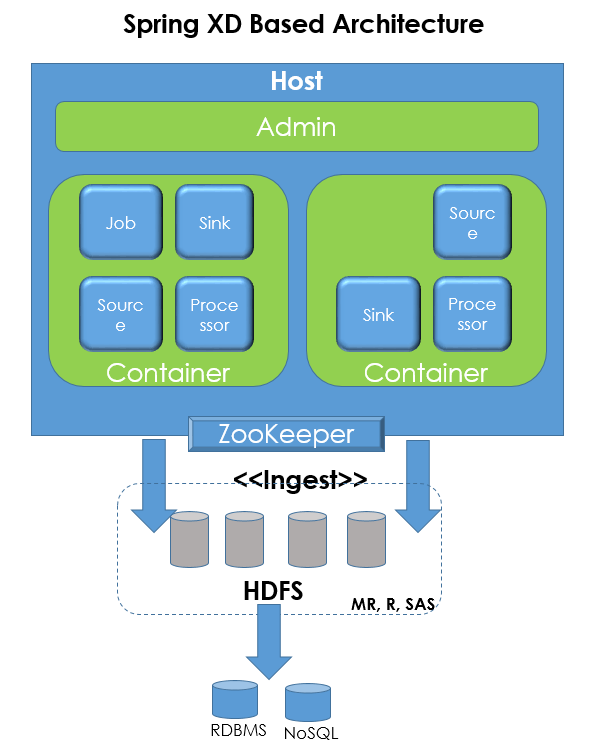
Spring XD 的主要组件是 Admin 和 Container。
- Admin UI 用于向服务器发送要执行某个任务的请求,然后服务器会调用关联的模块执行所请求的任务。在此,一个模块是构建 Spring 应用程序上下文的组件之一。
- 所有模块都需要一个 XD 容器才能运行并执行该模块执行的相关任务。
以下是 Spring XD 体系结构中的一些关键模块。
- 数据源(Source) :一个数据流的创建总会从创建数据源模块开始。数据源可以使用轮询机制或事件驱动机制获得数据,然后只会提供数据的输出。
- 数据处理器(Processor) :它会接收输入消息,并在经过某些类型的处理后产生输出消息。
- 数据接收器(Sink) :顾名思义,该模块是一个数据流的终点。它会将输出的数据发送到一个外部的资源,例如 HDFS。
- 作业(Job) :该模块会执行一些批处理作业。
对 Spring Cloud Data Flow 的需求
应用方面的需求总是在变化。这逐渐揭示了 Spring XD 的缺陷和对新一轮的技术创新的需求。以下是一些对新型框架最重要的需求:
- 云技术在运营需求和非功能性需求的平台级实现方面发挥了巨大作用,但在应用级别上落实 非功能性要求仍是一个对工程量的挑战。
- 在分布式环境中对特定阶段部署,动态资源分配,扩展能力和跟踪能力的需求也在日益增长。
- 现在越来越多的平台意识到了将平台迁移到云服务供应商上,以及一个平台的可迁移性的必要性。基于微服务的云架构会更加适合这一需求,但 Spring XD 没有为基于微服务的架构提供直接的支持。
- Spring XD 支持大数据的应用场景,但仍有很大一部分项目不需要 Hadoop 来存储并处理数据。
Spring Cloud Data Flow
作为第二轮技术创新,Pivotal 推出了 Spring Cloud Data Flow 来替代原来的 Spring XD。Spring Cloud Data Flow 继承了 Spring XD 的优势,并通过利用云原生(cloud native)方法提供了更具可扩展性的解决方案。Spring Cloud Data Flow 是一个混合的计算模型,可以将流处理和批处理统一起来。开发人员可以利用 Spring Cloud Data Flow 来创建并操作数据管道来进行处理数据摄入、实时分析和批处理等常见流程。Spring Cloud Data Flow 只会提供一个管理服务模型,旨在精简数据项目的工程量,并让开发人员将精力集中在具体问题及对问题的分析上。
Spring Cloud Data Flow 的架构
从 Spring XD 到 Spring Cloud Data Flow,对功能的结构以及利用云原生架构扩展应用程序方法发生了从根本上的改变。
Spring Cloud Data Flow 从传统的基于组件的架构转向了采用更适合云原生应用的,由消息驱动的微服务架构。现在 Spring XD 模块已经被部署在云端上的微服务取代了。
具体地说,Spring Cloud Data Flow 在以下方面有着一些重大变化:
- 为了利用云原生平台,Spring Cloud Data Flow 引入了服务提供者接口(SPI),该接口取代了 Spring XD 运行层(runtime layer)。
- 像 Admin REST API,shell 和 UI 层这样的用户界面和集成元素与 Spring XD 相同,但底层架构已被大幅修改。
- 服务提供者接口(SPI)取代了基于 Zookeeper 的运行模式。现在 SPI 会与其他系统(例如 Pivotal Cloud Foundry 或 Yarn)协调监测并启动基于微服务的应用程序。

Spring Cloud Data Flow 的组件:
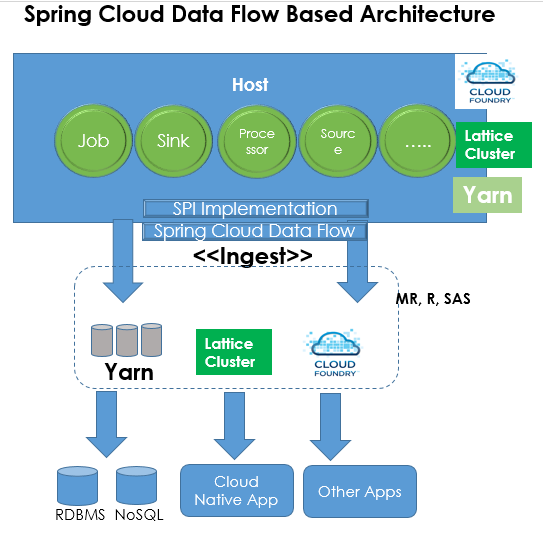
上图描绘了使用 Spring Cloud Data Flow 模型创建的一个典型数据流。
作为 Spring Boot 微服务,数据源,作业,数据接收器和数据处理器都可以部署在 Cloud Foundry, Lattice 或 Yarn 集群上。通过使用部署在云原生平台上的这些微服务,我们可以创建数据管道并将其输入到 Yarn,Lattice 或基于 Cloud Foundry 的目标中。平台特定的 SPI(服务提供者接口)会被用于发现和绑定微服务,以及绑定基于开发平台的渠道(channel)。
用例
使用 Spring Cloud Data Flow 的真正好处是能够使用一个统一的框架来快速完成构建和配置工作,并建立数据摄入和处理流程,从而使开发人员能更好地关注具体问题。
我们不妨构建这样一个用例来在高层面上见识一下 Spring Cloud Data Flow 的改变:在没有自带数据源模块的情况下构造一个完整的数据流,比如对 Facebook 的数据造一个数据流来分析 Facebook 的帖子。 在这种情况下,我们不能用在 Spring Cloud Data Flow 模块里能随便用的 Facebook 数据源模块,因此我们需要为 Facebook 数据源创建自定义模块。创建一个数据流需要三个主要的微服务:数据源,数据处理器和数据接收器。这三个微服务都有相应的接口类。
Facebook 数据管道的数据源和数据接收器的微服务示例代码片段:
Facebook 数据源:
@SpringBootApplication
@ComponentScan(.class)
public class SourceApplication {
public static void main(String[] args) {
SpringApplication.run(SourceApplication.class, args);
}
}
@Configuration
@EnableBinding(Source.class)
public class FBSource {
@Value("${format}")
private String format;
@Bean
@InboundChannelAdapter(value = Source.OUTPUT, poller = @Poller(fixedDelay = "${fixedDelay}", maxMessagesPerPoll = "1"))
public PostSource<String> FBPostSource() {
// 一些从 Facebook 获取帖子的逻辑
return // Facebook 帖子列表
}
}
@EnableBindings(Source.class) 注解会检查相应的作为可绑定组件的接口类的实现是否存在(要在应用的 classpath 中设置,参考 Redis),然后这一组件会构建相应的渠道适配器(channel adapters)。所有微服务都会被转变为 Spring Boot 应用程序来实现更简单的依赖管理。
Facebook 数据接收器:
@SpringBootApplication
@EnableBinding(Sink.class)
@ComponentScan(.class)
public class SinkApplication {
public static void main(String[] args) {
SpringApplication.run(SinkApplication.class, args);
}
}
@Configuration
public class FBSink {
private static Logger logger = LoggerFactory.getLogger(LogSink.class);
@ServiceActivator(Source.INPUT)
public void loggerSink(Object payload) {
logger.info("Received: " + payload);
}
}
上述代码会接收来自 Facebook 数据流的数据并将其写入控制台。 Sink.class 在此会作为参数传递给 @EnableBinding 注解。另外 @ServiceActivator 会将数据输入模块连接到上例中的终端(endpoint)控制台。
一些作为数据处理器的微服务将根据输入的 SPEL 表达式过滤来自 FBSource 微服务的 Facebook 帖子,而数据处理器微服务的输出就会是 FBSink 微服务的输入。
结论
Spring Cloud Data Flow 使用了 Spring Cloud stream 模块。我们可以用后者来创建和运行以 Spring Boot 应用为形式的消息传递微服务,以便它们可以部署在不同的平台上,独立运行并相互交互。在使用 Spring Cloud stream 模块创建数据管道时,Spring Cloud Data Flow 可以充当类似胶水的角色。
目前有许多用于管理数据摄入,实时分析和数据加载的,独立的开源项目。Spring Cloud Data Flow 则为数据摄入,实时分析,批处理还有数据输出提供了一个统一的,可扩展的分布式服务。
问答
Spring Boot 如何配置端口?
相关阅读
Spring框架系列之AOP思想
初识Spring Boot框架
Spring 事务管理基础入门总结此文已由作者授权腾讯云+社区发布,原文链接:https://cloud.tencent.com/developer/article/1128177?fromSource=waitui

正文到此结束
- 本文标签: classpath HDFS 大数据 REST 运营 bean 模型 服务器 集群 Facebook value src Service springboot spring cat 开源项目 App 企业 处理器 分布式 云 https redis CTO Developer 数据科学 Spring Boot shell 数据 需求 开源 message id UI 代码 总结 Job AOP 端口 配置 API 开发 ACE IO Hadoop zookeeper 管理 参数 http ORM Spring cloud
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

