Dubbo 源码分析 - 集群容错之 Cluster
1.简介
为了避免单点故障,现在的应用至少会部署在两台服务器上。对于一些负载比较高的服务,会部署更多台服务器。这样,同一环境下的服务提供者数量会大于1。对于服务消费者来说,同一环境下出现了多个服务提供者。这时会出现一个问题,服务消费者需要决定选择哪个服务提供者进行调用。另外服务调用失败时的处理措施也是需要考虑的,是重试呢,还是抛出异常,亦或是只打印异常等。为了处理这些问题,Dubbo 定义了集群接口 Cluster 以及及 Cluster Invoker。集群 Cluster 用途是将多个服务提供者合并为一个 Cluster Invoker,并将这个 Invoker 暴露给服务消费者。这样一来,服务消费者只需通过这个 Invoker 进行远程调用即可,至于具体调用哪个服务提供者,以及调用失败后如何处理等问题,现在都交给集群模块去处理。集群模块是服务提供者和服务消费者的中间层,为服务消费者屏蔽了服务提供者的情况,这样服务消费者就可以处理远程调用相关事宜。比如发请求,接受服务提供者返回的数据等。这就是集群的作用。
Dubbo 提供了多种集群实现,包含但不限于 Failover Cluster、Failfast Cluster 和 Failsafe Cluster 等。每种集群实现类的用途不同,接下来我会一一进行分析。
2. 集群容错
在对集群相关代码进行分析之前,这里有必要先来介绍一下集群容错的所有组件。包含 Cluster、Cluster Invoker、Directory、Router 和 LoadBalance 等,先来看图。
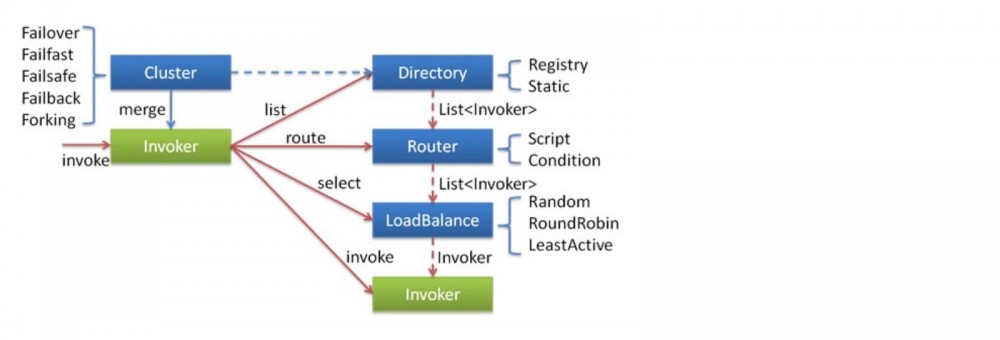
* 图片来源: Dubbo 官方文档
这张图来自 Dubbo 官方文档,接下来我会按照这张图介绍集群工作过程。集群工作过程可分为两个阶段,第一个阶段是在服务消费者初始化期间,集群 Cluster 实现类为服务消费者创建 Cluster Invoker 实例,即上图中的 merge 操作。第二个阶段是在服务消费者进行远程调用时。以 FailoverClusterInvoker 为例,该类型 Cluster Invoker 首先会调用 Directory 的 list 方法列举 Invoker 列表(可将 Invoker 简单理解为服务提供者)。Directory 的用途是保存 Invoker,可简单类比为 List<Invoker>。其实现类 RegistryDirectory 是一个动态服务目录,可感知注册中心配置的变化,它所持有的 Inovker 列表会随着注册中心内容的变化而变化。每次变化后,RegistryDirectory 会动态增删 Inovker,并调用 Router 的 route 方法进行路由,过滤掉不符合路由规则的 Invoker。回到上图,Cluster Invoker 实际上并不会直接调用 Router 进行路由。当 FailoverClusterInvoker 拿到 Directory 返回的 Invoker 列表后,它会通过 LoadBalance 从 Invoker 列表中选择一个 Inovker。最后 FailoverClusterInvoker 会将参数传给 LoadBalance 选择出的 Invoker 实例的 invoker 方法,进行真正的 RPC 调用。
以上就是集群工作的整个流程,这里并没介绍集群是如何容错的。Dubbo 主要提供了这样几种容错方式:
- Failover Cluster - 失败自动切换
- Failfast Cluster - 快速失败
- Failsafe Cluster - 失败安全
- Failback Cluster - 失败自动恢复
- Forking Cluster - 并行调用多个服务提供者
这里暂时只对这几种容错模式进行简单的介绍,在接下来的章节中,我会重点分析这几种容错模式的具体实现。好了,关于集群的工作流程和容错模式先说到这,接下来进入源码分析阶段。
3.源码分析
3.1 Cluster 实现类分析
我在上一章提到了集群接口 Cluster 和 Cluster Invoker,这两者是不同的。Cluster 是接口,而 Cluster Invoker 是一种 Invoker。服务提供者的选择逻辑,以及远程调用失败后的的处理逻辑均是封装在 Cluster Invoker 中。那么 Cluster 接口和相关实现类有什么用呢?用途比较简单,用于生成 Cluster Invoker,仅此而已。下面我们来看一下源码。
public class FailoverCluster implements Cluster {
public final static String NAME = "failover";
@Override
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
// 创建并返回 FailoverClusterInvoker 对象
return new FailoverClusterInvoker<T>(directory);
}
}
如上,FailoverCluster 总共就包含这几行代码,用于创建 FailoverClusterInvoker 对象,很简单。下面再看一个。
public class FailbackCluster implements Cluster {
public final static String NAME = "failback";
@Override
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
// 创建并返回 FailbackClusterInvoker 对象
return new FailbackClusterInvoker<T>(directory);
}
}
如上,FailbackCluster 的逻辑也是很简单,无需解释了。所以接下来,我们把重点放在各种 Cluster Invoker 上
3.2 Cluster Invoker 分析
我们首先从各种 Cluster Invoker 的父类 AbstractClusterInvoker 源码开始说起。前面说过,集群工作过程可分为两个阶段,第一个阶段是在服务消费者初始化期间,这个在服务引用那篇文章中已经分析过了,这里不再赘述。第二个阶段是在服务消费者进行远程调用时,此时 AbstractClusterInvoker 的 invoke 方法会被调用。列举 Invoker,负载均衡等操作均会在此阶段被执行。因此下面先来看一下 invoke 方法的逻辑。
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
LoadBalance loadbalance = null;
// 绑定 attachments 到 invocation 中.
Map<String, String> contextAttachments = RpcContext.getContext().getAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation) invocation).addAttachments(contextAttachments);
}
// 列举 Invoker
List<Invoker<T>> invokers = list(invocation);
if (invokers != null && !invokers.isEmpty()) {
// 加载 LoadBalance
loadbalance = ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(invokers.get(0).getUrl()
.getMethodParameter(RpcUtils.getMethodName(invocation), Constants.LOADBALANCE_KEY, Constants.DEFAULT_LOADBALANCE));
}
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
// 调用 doInvoke 进行后续操作
return doInvoke(invocation, invokers, loadbalance);
}
// 抽象方法,由子类实现
protected abstract Result doInvoke(Invocation invocation, List<Invoker<T>> invokers,
LoadBalance loadbalance) throws RpcException;
AbstractClusterInvoker 的 invoke 方法主要用于列举 Invoker,以及加载 LoadBalance。最后再调用模板方法 doInvoke 进行后续操作。下面我们来看一下 Invoker 列举方法 list(Invocation) 的逻辑,如下:
protected List<Invoker<T>> list(Invocation invocation) throws RpcException {
// 调用 Directory 的 list 方法
List<Invoker<T>> invokers = directory.list(invocation);
return invokers;
}
如上,AbstractClusterInvoker 中的 list 方法做的事情很简单,只是简单的调用了 Directory 的 list 方法,没有其他更多的逻辑了。Directory 的 list 方法我在前面的文章中已经分析过了,这里就不赘述了。
接下来,我们把目光转移到 AbstractClusterInvoker 的各种实现类上,来看一下这些实现类是如何实现 doInvoke 方法逻辑的。
3.2.1 FailoverClusterInvoker
FailoverClusterInvoker 在调用失败时,会自动切换 Invoker 进行重试。在无明确配置下,Dubbo 会使用这个类作为缺省 Cluster Invoker。下面来看一下该类的逻辑。
public class FailoverClusterInvoker<T> extends AbstractClusterInvoker<T> {
// 省略部分代码
@Override
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
List<Invoker<T>> copyinvokers = invokers;
checkInvokers(copyinvokers, invocation);
// 获取重试次数
int len = getUrl().getMethodParameter(invocation.getMethodName(), Constants.RETRIES_KEY, Constants.DEFAULT_RETRIES) + 1;
if (len <= 0) {
len = 1;
}
RpcException le = null;
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyinvokers.size());
Set<String> providers = new HashSet<String>(len);
// 循环调用,失败重试
for (int i = 0; i < len; i++) {
if (i > 0) {
checkWhetherDestroyed();
// 在进行重试前重新列举 Invoker,这样做的好处是,如果某个服务挂了,
// 通过调用 list 可得到最新可用的 Invoker 列表
copyinvokers = list(invocation);
// 对 copyinvokers 进行判空检查
checkInvokers(copyinvokers, invocation);
}
// 通过负载均衡选择 Invoker
Invoker<T> invoker = select(loadbalance, invocation, copyinvokers, invoked);
// 添加到 invoker 到 invoked 列表中
invoked.add(invoker);
// 设置 invoked 到 RPC 上下文中
RpcContext.getContext().setInvokers((List) invoked);
try {
// 调用目标 Invoker 的 invoke 方法
Result result = invoker.invoke(invocation);
return result;
} catch (RpcException e) {
if (e.isBiz()) {
throw e;
}
le = e;
} catch (Throwable e) {
le = new RpcException(e.getMessage(), e);
} finally {
providers.add(invoker.getUrl().getAddress());
}
}
// 若重试均失败,则抛出异常
throw new RpcException(..., "Failed to invoke the method ...");
}
}
如上,FailoverClusterInvoker 的 doInvoke 方法首先是获取重试次数,然后根据重试次数进行循环调用,失败后进行重试。在 for 循环内,首先是通过负载均衡组件选择一个 Invoker,然后再通过这个 Invoker 的 invoke 方法进行远程调用。如果失败了,记录下异常,并进行重试。重试时会再次调用父类的 list 方法列举 Invoker。整个流程大致如此,不是很难理解。下面我们看一下 select 方法的逻辑。
protected Invoker<T> select(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
if (invokers == null || invokers.isEmpty())
return null;
// 获取调用方法名
String methodName = invocation == null ? "" : invocation.getMethodName();
// 获取 sticky 配置,sticky 表示粘滞连接。所谓粘滞连接是指让服务消费者尽可能的
// 调用同一个服务提供者,除非该提供者挂了再进行切换
boolean sticky = invokers.get(0).getUrl().getMethodParameter(methodName, Constants.CLUSTER_STICKY_KEY, Constants.DEFAULT_CLUSTER_STICKY);
{
// 检测 invokers 列表是否包含 stickyInvoker,如果不包含,
// 说明 stickyInvoker 代表的服务提供者挂了,此时需要将其置空
if (stickyInvoker != null && !invokers.contains(stickyInvoker)) {
stickyInvoker = null;
}
// 在 sticky 为 true,且 stickyInvoker != null 的情况下。如果 selected 包含
// stickyInvoker,表明 stickyInvoker 对应的服务提供者可能因网络原因未能成功提供服务。
// 但是该提供者并没挂,此时 invokers 列表中仍存在该服务提供者对应的 Invoker。
if (sticky && stickyInvoker != null && (selected == null || !selected.contains(stickyInvoker))) {
// availablecheck 表示是否开启了可用性检查,如果开启了,则调用 stickyInvoker 的
// isAvailable 方法进行检查,如果检查通过,则直接返回 stickyInvoker。
if (availablecheck && stickyInvoker.isAvailable()) {
return stickyInvoker;
}
}
}
// 如果线程走到当前代码处,说明前面的 stickyInvoker 为空,或者不可用。
// 此时调用继续调用 doSelect 选择 Invoker
Invoker<T> invoker = doSelect(loadbalance, invocation, invokers, selected);
// 如果 sticky 为 true,则将负载均衡组件选出的 Invoker 赋值给 stickyInvoker
if (sticky) {
stickyInvoker = invoker;
}
return invoker;
}
如上,select 方法的主要逻辑集中在了对粘滞连接特性的支持上。首先是获取 sticky 配置,然后再检测 invokers 列表中是否包含 stickyInvoker,如果不包含,则认为该 stickyInvoker 不可用,此时将其置空。这里的 invokers 列表可以看做是 存活着的服务提供者 列表,如果这个列表不包含 stickyInvoker,那自然而然的认为 stickyInvoker 挂了,所以置空。如果 stickyInvoker 存在于 invokers 列表中,此时要进行下一项检测 ---- 检测 selected 中是否包含 stickyInvoker。如果包含的话,说明 stickyInvoker 在此之前没有成功提供服务(但其仍然处于存活状态)。此时我们认为这个服务不可靠,不应该在重试期间内再次被调用,因此这个时候不会返回该 stickyInvoker。如果 selected 不包含 stickyInvoker,此时还需要进行可用性检测,比如检测服务提供者网络连通性等。当可用性检测通过,才可返回 stickyInvoker,否则调用 doSelect 方法选择 Invoker。如果 sticky 为 true,此时会将 doSelect 方法选出的 Invoker 赋值给 stickyInvoker。
以上就是 select 方法的逻辑,这段逻辑看起来不是很复杂,但是信息量比较大。不搞懂 invokers 和 selected 两个入参的含义,以及粘滞连接特性,这段代码应该是没法看懂的。大家在阅读这段代码时,不要忽略了对背景知识的理解。其他的不多说了,继续向下分析。
private Invoker<T> doSelect(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
if (invokers == null || invokers.isEmpty())
return null;
if (invokers.size() == 1)
return invokers.get(0);
if (loadbalance == null) {
// 如果 loadbalance 为空,这里通过 SPI 加载 Loadbalance,默认为 RandomLoadBalance
loadbalance = ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(Constants.DEFAULT_LOADBALANCE);
}
// 通过负载均衡组件选择 Invoker
Invoker<T> invoker = loadbalance.select(invokers, getUrl(), invocation);
// 如果 selected 包含负载均衡选择出的 Invoker,或者该 Invoker 无法经过可用性检查,此时进行重选
if ((selected != null && selected.contains(invoker))
|| (!invoker.isAvailable() && getUrl() != null && availablecheck)) {
try {
// 进行重选
Invoker<T> rinvoker = reselect(loadbalance, invocation, invokers, selected, availablecheck);
if (rinvoker != null) {
// 如果 rinvoker 不为空,则将其赋值给 invoker
invoker = rinvoker;
} else {
// rinvoker 为空,定位 invoker 在 invokers 中的位置
int index = invokers.indexOf(invoker);
try {
// 获取 index + 1 位置处的 Invoker,以下代码等价于:
// invoker = invokers.get((index + 1) % invokers.size());
invoker = index < invokers.size() - 1 ? invokers.get(index + 1) : invokers.get(0);
} catch (Exception e) {
logger.warn("... may because invokers list dynamic change, ignore.");
}
}
} catch (Throwable t) {
logger.error("cluster reselect fail reason is : ...");
}
}
return invoker;
}
doSelect 主要做了两件事,第一是通过负载均衡组件选择 Invoker。第二是,如果选出来的 Invoker 不稳定,或不可用,此时需要调用 reselect 方法进行重选。若 reselect 选出来的 Invoker 为空,此时定位 invoker 在 invokers 列表中的位置 index,然后获取 index + 1 处的 invoker,这也可以看做是重选逻辑的一部分。关于负载均衡的选择逻辑,我将会在下篇文章进行详细分析。下面我们来看一下 reselect 方法的逻辑。
private Invoker<T> reselect(LoadBalance loadbalance, Invocation invocation,
List<Invoker<T>> invokers, List<Invoker<T>> selected, boolean availablecheck)
throws RpcException {
List<Invoker<T>> reselectInvokers = new ArrayList<Invoker<T>>(invokers.size() > 1 ? (invokers.size() - 1) : invokers.size());
// 根据 availablecheck 进行不同的处理
if (availablecheck) {
// 遍历 invokers 列表
for (Invoker<T> invoker : invokers) {
// 检测可用性
if (invoker.isAvailable()) {
// 如果 selected 列表不包含当前 invoker,则将其添加到 reselectInvokers 中
if (selected == null || !selected.contains(invoker)) {
reselectInvokers.add(invoker);
}
}
}
// reselectInvokers 不为空,此时通过负载均衡组件进行选择
if (!reselectInvokers.isEmpty()) {
return loadbalance.select(reselectInvokers, getUrl(), invocation);
}
// 不检查 Invoker 可用性
} else {
for (Invoker<T> invoker : invokers) {
// 如果 selected 列表不包含当前 invoker,则将其添加到 reselectInvokers 中
if (selected == null || !selected.contains(invoker)) {
reselectInvokers.add(invoker);
}
}
if (!reselectInvokers.isEmpty()) {
// 通过负载均衡组件进行选择
return loadbalance.select(reselectInvokers, getUrl(), invocation);
}
}
{
// 若线程走到此处,说明 reselectInvokers 集合为空,此时不会调用负载均衡组件进行筛选。
// 这里从 selected 列表中查找可用的 Invoker,并将其添加到 reselectInvokers 集合中
if (selected != null) {
for (Invoker<T> invoker : selected) {
if ((invoker.isAvailable())
&& !reselectInvokers.contains(invoker)) {
reselectInvokers.add(invoker);
}
}
}
if (!reselectInvokers.isEmpty()) {
// 再次进行选择,并返回选择结果
return loadbalance.select(reselectInvokers, getUrl(), invocation);
}
}
return null;
}
reselect 方法总结下来其实只做了两件事情,第一是查找可用的 Invoker,并将其添加到 reselectInvokers 集合中。第二,如果 reselectInvokers 不为空,则通过负载均衡组件再次进行选择。其中第一件事情又可进行细分,一开始,reselect 从 invokers 列表中查找有效可用的 Invoker,若未能找到,此时再到 selected 列表中继续查找。关于 reselect 方法就先分析到这,继续分析其他的 Cluster Invoker。
3.2.2 FailbackClusterInvoker
FailbackClusterInvoker 会在调用失败后,返回一个空结果给服务提供者。并通过定时任务对失败的调用进行重传,适合执行消息通知等操作。下面来看一下它的实现逻辑。
public class FailbackClusterInvoker<T> extends AbstractClusterInvoker<T> {
private static final long RETRY_FAILED_PERIOD = 5 * 1000;
private final ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(2,
new NamedInternalThreadFactory("failback-cluster-timer", true));
private final ConcurrentMap<Invocation, AbstractClusterInvoker<?>> failed = new ConcurrentHashMap<Invocation, AbstractClusterInvoker<?>>();
private volatile ScheduledFuture<?> retryFuture;
@Override
protected Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
// 选择 Invoker
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
// 进行调用
return invoker.invoke(invocation);
} catch (Throwable e) {
// 如果调用过程中发生异常,此时仅打印错误日志,不抛出异常
logger.error("Failback to invoke method ...");
// 记录调用信息
addFailed(invocation, this);
// 返回一个空结果给服务消费者
return new RpcResult();
}
}
private void addFailed(Invocation invocation, AbstractClusterInvoker<?> router) {
if (retryFuture == null) {
synchronized (this) {
if (retryFuture == null) {
// 创建定时任务,每隔5秒执行一次
retryFuture = scheduledExecutorService.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
try {
// 对失败的调用进行重试
retryFailed();
} catch (Throwable t) {
// 如果发生异常,仅打印异常日志,不抛出
logger.error("Unexpected error occur at collect statistic", t);
}
}
}, RETRY_FAILED_PERIOD, RETRY_FAILED_PERIOD, TimeUnit.MILLISECONDS);
}
}
}
// 添加 invocation 和 invoker 到 failed 中,
// 这里的把 invoker 命名为 router,很奇怪,明显名不副实
failed.put(invocation, router);
}
void retryFailed() {
if (failed.size() == 0) {
return;
}
// 遍历 failed,对失败的调用进行重试
for (Map.Entry<Invocation, AbstractClusterInvoker<?>> entry : new HashMap<Invocation, AbstractClusterInvoker<?>>(failed).entrySet()) {
Invocation invocation = entry.getKey();
Invoker<?> invoker = entry.getValue();
try {
// 再次进行调用
invoker.invoke(invocation);
// 调用成功,则从 failed 中移除 invoker
failed.remove(invocation);
} catch (Throwable e) {
// 仅打印异常,不抛出
logger.error("Failed retry to invoke method ...");
}
}
}
}
这个类主要由3个方法组成,首先是 doInvoker,该方法负责初次的远程调用。若远程调用失败,则通过 addFailed 方法将调用信息存入到 failed 中,等待定时重试。addFailed 在开始阶段会根据 retryFuture 为空与非,来决定是否开启定时任务。retryFailed 方法则是包含了失败重试的逻辑,该方法会对 failed 进行遍历,然后依次对 Invoker 进行调用。调用成功则将 Invoker 从 failed 中移除,调用失败则忽略失败原因。
以上就是 FailbackClusterInvoker 的执行逻辑,不是很复杂,继续往下看。
3.2.3 FailfastClusterInvoker
FailfastClusterInvoker 只会进行一次调用,失败后立即抛出异常。适用于幂等操作,比如新增记录。楼主日常开发中碰到过一次程序连续插入三条同样的记录问题,原因是新增记录过程中包含了一些耗时操作,导致接口超时。而我当时使用的是 Dubbo 默认的 Cluster Invoker,即 FailoverClusterInvoker。其会在调用失败后进行重试,所以导致插入服务提供者插入了3条同样的数据。如果当时考虑使用 FailfastClusterInvoker,就不会出现这种问题了。当然此时接口仍然会超时,所以更合理的做法是使用 Dubbo 异步特性。或者优化服务逻辑,避免超时。
其他的不多说了,下面直接看源码吧。
public class FailfastClusterInvoker<T> extends AbstractClusterInvoker<T> {
@Override
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
checkInvokers(invokers, invocation);
// 选择 Invoker
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
try {
// 调用 Invoker
return invoker.invoke(invocation);
} catch (Throwable e) {
if (e instanceof RpcException && ((RpcException) e).isBiz()) {
// 抛出异常
throw (RpcException) e;
}
// 抛出异常
throw new RpcException(..., "Failfast invoke providers ...");
}
}
}
上面代码比较简单了,首先是通过 select 方法选择 Invoker,然后进行远程调用。如果调用失败,则立即抛出异常。FailfastClusterInvoker 就先分析到这,下面分析 FailsafeClusterInvoker。
3.2.4 FailsafeClusterInvoker
FailsafeClusterInvoker 是一种失败安全的 Cluster Invoker。所谓的失败安全是指,当调用过程中出现异常时,FailsafeClusterInvoker 仅会打印异常,而不会抛出异常。Dubbo 官方给出的应用场景是写入审计日志等操作,这个场景我在日常开发中没遇到过,没发言权,就不多说了。下面直接分析源码。
public class FailsafeClusterInvoker<T> extends AbstractClusterInvoker<T> {
@Override
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
// 选择 Invoker
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
// 进行远程调用
return invoker.invoke(invocation);
} catch (Throwable e) {
// 打印错误日志,但不抛出
logger.error("Failsafe ignore exception: " + e.getMessage(), e);
// 返回空结果忽略错误
return new RpcResult();
}
}
}
FailsafeClusterInvoker 的逻辑和 FailfastClusterInvoker 的逻辑一样简单,因此就不多说了。继续下面分析。
3.2.5 ForkingClusterInvoker
ForkingClusterInvoker 会在运行时通过线程池创建多个线程,并发调用多个服务提供者。只要有一个服务提供者成功返回了结果,doInvoke 方法就会立即结束运行。ForkingClusterInvoker 的应用场景是在一些对实时性要求比较高 读操作 (注意是读操作,并行写操作可能不安全)下使用,但这将会耗费更多的服务资源。下面来看该类的实现。
public class ForkingClusterInvoker<T> extends AbstractClusterInvoker<T> {
private final ExecutorService executor = Executors.newCachedThreadPool(
new NamedInternalThreadFactory("forking-cluster-timer", true));
@Override
public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
final List<Invoker<T>> selected;
// 获取 forks 配置
final int forks = getUrl().getParameter(Constants.FORKS_KEY, Constants.DEFAULT_FORKS);
// 获取超时配置
final int timeout = getUrl().getParameter(Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
// 如果 forks 配置不合理,则直接将 invokers 赋值给 selected
if (forks <= 0 || forks >= invokers.size()) {
selected = invokers;
} else {
selected = new ArrayList<Invoker<T>>();
// 循环选出 forks 个 Invoker,并添加到 selected 中
for (int i = 0; i < forks; i++) {
// 选择 Invoker
Invoker<T> invoker = select(loadbalance, invocation, invokers, selected);
if (!selected.contains(invoker)) {
selected.add(invoker);
}
}
}
// ----------------------:sparkles: 分割线1 :sparkles:---------------------- //
RpcContext.getContext().setInvokers((List) selected);
final AtomicInteger count = new AtomicInteger();
final BlockingQueue<Object> ref = new LinkedBlockingQueue<Object>();
// 遍历 selected 列表
for (final Invoker<T> invoker : selected) {
// 为每个 Invoker 创建一个执行线程
executor.execute(new Runnable() {
@Override
public void run() {
try {
// 进行远程调用
Result result = invoker.invoke(invocation);
// 将结果存到阻塞队列中
ref.offer(result);
} catch (Throwable e) {
int value = count.incrementAndGet();
// 仅在 value 大于等于 selected.size() 时,才将异常对象
// 放入阻塞队列中,请大家思考一下为什么要这样做。
if (value >= selected.size()) {
// 将异常对象存入到阻塞队列中
ref.offer(e);
}
}
}
});
}
// ----------------------:sparkles: 分割线2 :sparkles:---------------------- //
try {
// 从阻塞队列中取出远程调用结果
Object ret = ref.poll(timeout, TimeUnit.MILLISECONDS);
// 如果结果类型为 Throwable,则抛出异常
if (ret instanceof Throwable) {
Throwable e = (Throwable) ret;
throw new RpcException(..., "Failed to forking invoke provider ...");
}
// 返回结果
return (Result) ret;
} catch (InterruptedException e) {
throw new RpcException("Failed to forking invoke provider ...");
}
} finally {
RpcContext.getContext().clearAttachments();
}
}
}
ForkingClusterInvoker 的 doInvoker 方法比较长,这里我通过两个分割线将整个方法划分为三个逻辑块。从方法开始,到分割线1之间的代码主要是用于选出 forks 个 Invoker,为接下来的并发调用提供输入。分割线1和分割线2之间的逻辑主要是通过线程池并发调用多个 Invoker,并将结果存储在阻塞队列中。分割线2到方法结尾之间的逻辑主要用于从阻塞队列中获取返回结果,并对返回结果类型进行判断。如果为异常类型,则直接抛出,否则返回。
以上就是ForkingClusterInvoker 的 doInvoker 方法大致过程。我在分割线1和分割线2之间的代码上留了一个问题,问题是这样的:为什么要在 value >= selected.size() 的情况下,才将异常对象添加到阻塞队列中?这里来解答一下。原因是这样的,在并行调用多个服务提供者的情况下,哪怕只有一个服务提供者成功返回结果,而其他全部失败。此时 ForkingClusterInvoker 仍应该返回成功的结果,而非抛出异常。在 value >= selected.size() 时将异常对象放入阻塞队列中,可以保证异常对象不会出现在正常结果的前面,这样可从阻塞队列中优先取出正常的结果。
好了,关于 ForkingClusterInvoker 就先分析到这,接下来分析最后一个 Cluster Invoker。
3.2.6 BroadcastClusterInvoker
本章的最后,我们再来看一下 BroadcastClusterInvoker。BroadcastClusterInvoker 会逐个调用每个服务提供者,如果其中一台报错,在循环调用结束后,BroadcastClusterInvoker 会抛出异常。看官方文档上的说明,该类通常用于通知所有提供者更新缓存或日志等本地资源信息。这个使用场景笔者也没遇到过,没法详细说明了,所以下面还是直接分析源码吧。
public class BroadcastClusterInvoker<T> extends AbstractClusterInvoker<T> {
@Override
public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
checkInvokers(invokers, invocation);
RpcContext.getContext().setInvokers((List) invokers);
RpcException exception = null;
Result result = null;
// 遍历 Invoker 列表,逐个调用
for (Invoker<T> invoker : invokers) {
try {
// 进行远程调用
result = invoker.invoke(invocation);
} catch (RpcException e) {
exception = e;
logger.warn(e.getMessage(), e);
} catch (Throwable e) {
exception = new RpcException(e.getMessage(), e);
logger.warn(e.getMessage(), e);
}
}
// exception 不为空,则抛出异常
if (exception != null) {
throw exception;
}
return result;
}
}
以上就是 BroadcastClusterInvoker 的代码,比较简单,就不多说了。
4.总结
本篇文章较为详细的分析了 Dubbo 集群容错方面的内容,并详细分析了集群容错的几种实现方式。集群容错对于 Dubbo 框架来说,是很重要的逻辑。集群模块处于服务提供者和消费者之间,对于服务消费者来说,集群可向其屏蔽服务提供者集群的情况,使其能够专心进行远程调用。除此之外,通过集群模块,我们还可以对服务之间的调用链路进行编排优化,治理服务。总的来说,对于 Dubbo 而言,集群容错相关逻辑是非常重要的。想要对 Dubbo 有比较深的理解,集群容错是绕不过去的。因此,对于这部分内容,大家要认真看一下。
好了,本篇文章就先到这,感谢大家的阅读。
附录:Dubbo 源码分析系列文章
| 时间 | 文章 |
|---|---|
| 2018-10-01 | Dubbo 源码分析 - SPI 机制 |
| 2018-10-13 | Dubbo 源码分析 - 自适应拓展原理 |
| 2018-10-31 | Dubbo 源码分析 - 服务导出 |
| 2018-11-12 | Dubbo 源码分析 - 服务引用 |
| 2018-11-17 | Dubbo 源码分析 - 集群容错之 Directory |
| 2018-11-20 | Dubbo 源码分析 - 集群容错之 Router |
| 2018-11-22 | Dubbo 源码分析 - 集群容错之 Cluster |
正文到此结束
- 本文标签: db map CTO 参数 详细分析 Service 注册中心 并发 tab 安全 CEO list 自适应 Atom 专心 retry 源码 集群 时间 value provider queue id 幂等 服务器 cat 代码 key dubbo message IO 缓存 目录 线程 IDE 实例 总结 线程池 图片 synchronized 数据 Select final 文章 executor ArrayList rand 负载均衡 UI DOM volatile http cache ConcurrentHashMap tk https 配置 遍历 开发 src constant HashMap HashSet
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

