Full GC 问题排查案例
背景
公司技术群里有人在问项目遇到了频繁Full GC如何查找。我就向他了解了一下具体情况。
-
配置的是CMS,却发生了大量的Full GC情况。Full GC的条件可以参考:谈谈JVM的垃圾回收器;
-
发生Full GC的时候,服务本身没有任何改动;接收的MQ消息突然增多,但是在MQ消息消费完之后,Full GC没有改善;重启服务之后还是不行;
Full GC监控如下:
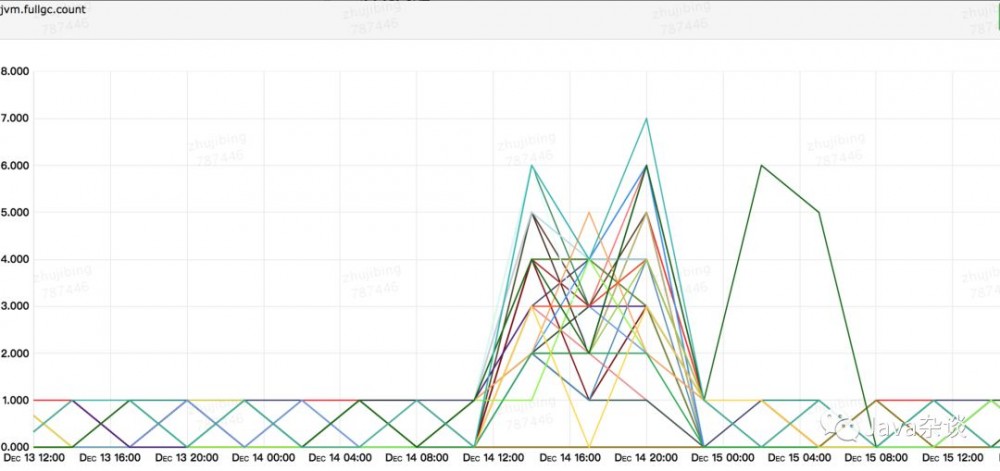
排查过程
首先,到问题机器上dump下内存,用MAT去查看,发现存在一个1.6G左右的byte数组,但是该数组已经成为不可达对象。
并且查看监控也发现,old区域中的内存存在暴增的现象,很像我之前遇到的一个case( 一个诡异的full gc查找问题 )。
然后,多次dump还是找不到byte数组的引用关系,就选择去查找full gc的原因,根据CMS GC降级到Full GC的条件和gc log怀疑是由于发生OOM发生了Full GC;
其次,查看业务方是否添加jvm参数-XX:+HeapDumpOnOutOfMemoryError,-XX:HeapDumpPath={path},发现业务方有该参数;去相关目录下查看确实有dump下的内存,用MAT分析该内存,可以看出如下:
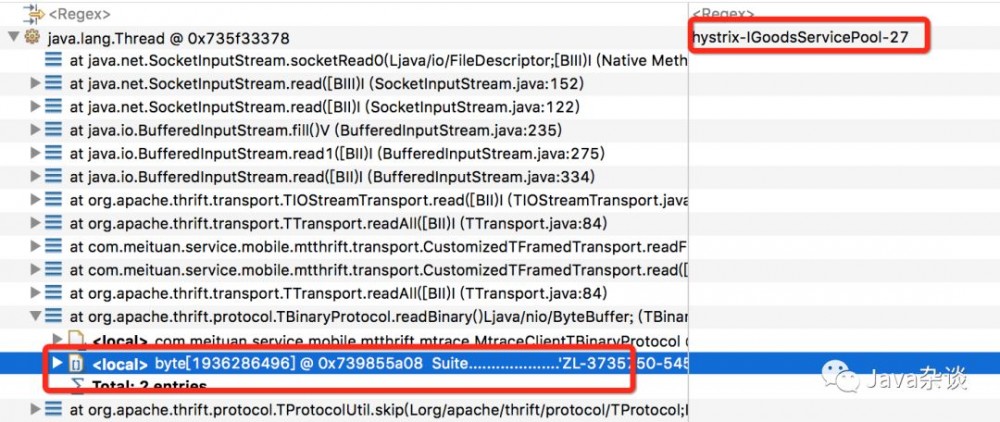
很明显业务方用hystrix封装了thrift调用接口,在read的时候,申请了1.8G的byte数组。
最后,虽然已经定位到是哪一行代码有问题,但是还是不确定为什么会出现这种现象,我怀疑出现这种现象有3种情况:
-
server 端确实是返回这么大的数据;
-
客户端和服务端的thrift协议对不上;
-
多线程并发的问题;
于是我拉上了公司基础架构部门的人和业务方,基础架构部的人建议首先看一下基础架构埋点监控,发现数据不会这么大,于是排除一。然后基础架构部的人建议业务方和server端对一下idl是否相同,业务方排查下来发现确实不同。
业务修改jar和server端的idl保持一致,上线验证问题解决。
问题分析
-
为什么业务方设置的maxResponseMessageBytes参数为15M,还会申请那么大的内存?
我理解的thrift的消息格式如下:

head中有thrift版本、data长度等信息,maxResponseMessageBytes设置的是整体的大小。而这次出错的是从data根据idl序列化成modle的时候发生的,所以maxResponseMessageBytes无能无力。
-
为什么客户端与服务端的idl不一致会导致这种现象?
一般我们在idl中新增字段,并且增加id不会有问题,但是我们去修改相同id中的类型就会导致不可知的错误。而在本例中server端修改了package的路径信息和字段,导致了该现象。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

