解读java集合框架源码-HashMap
Map, 一个将key映射到value的对象。一个Map不能包含两个重复的key,每个key最多只能映射到一个value上 – JDK
Map接口,在JDK中有多种实现方式。比较典型的有散列表实现的HashMap、有红黑树实现的TreeMap、结合双向链表和HashMap实现的LinkedHashMap(其特质可以帮助我们实现LRU算法),除了以上三个之外,在并发包中提供了一个基于散列表实现的线程安全的ConcurrentHashMap
HashMap
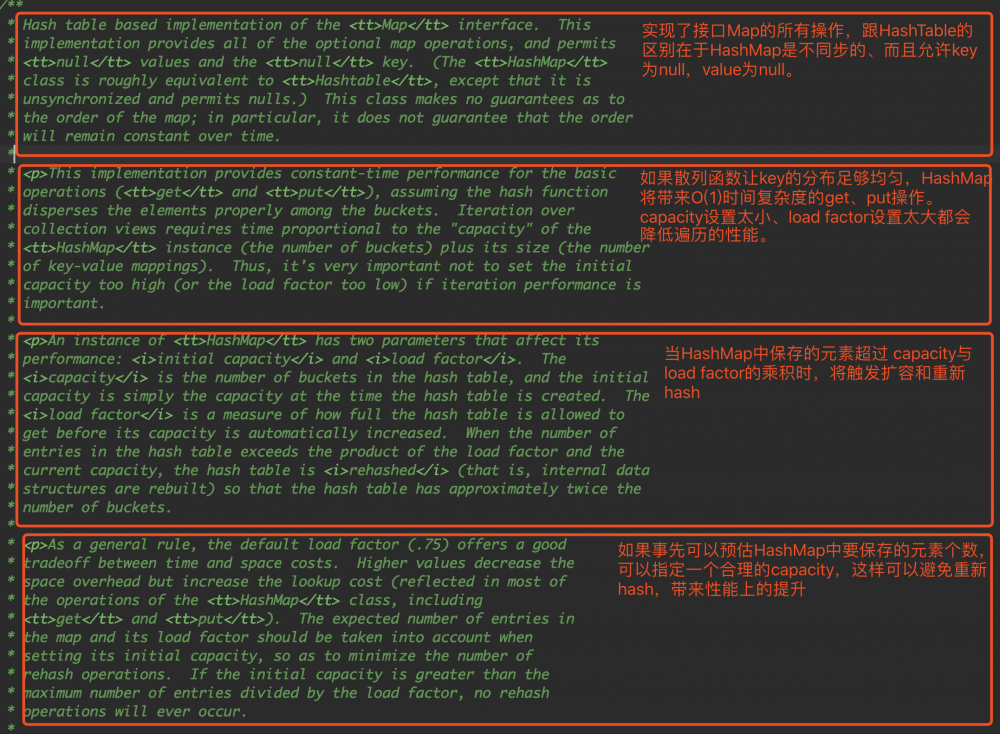
JDK注释说明

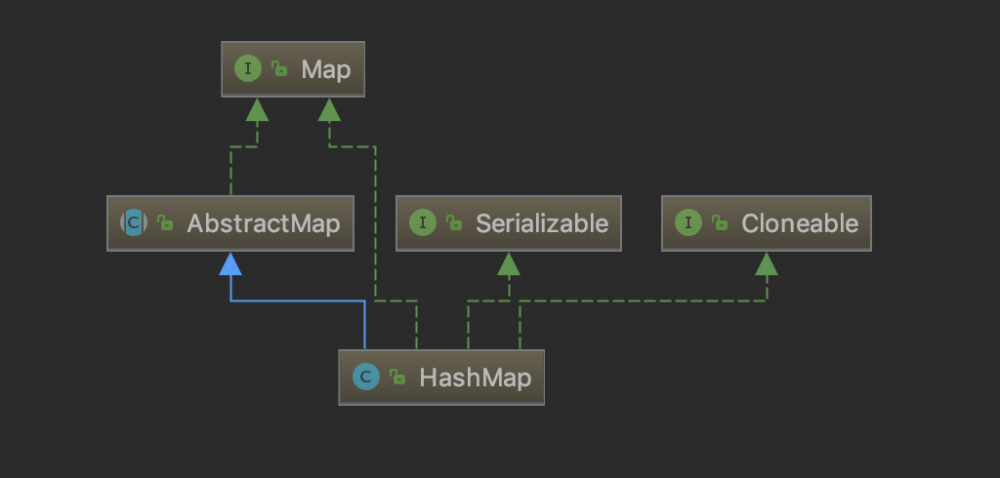
类继承图
源码分析
平时我们使用HashMap的时候,一般都是直接new HashMap()实例化一个对象,之后进行map.put(key, value)操作。此时我们依照这个调用路径来看看HashMap内部是如何为我们工作的。
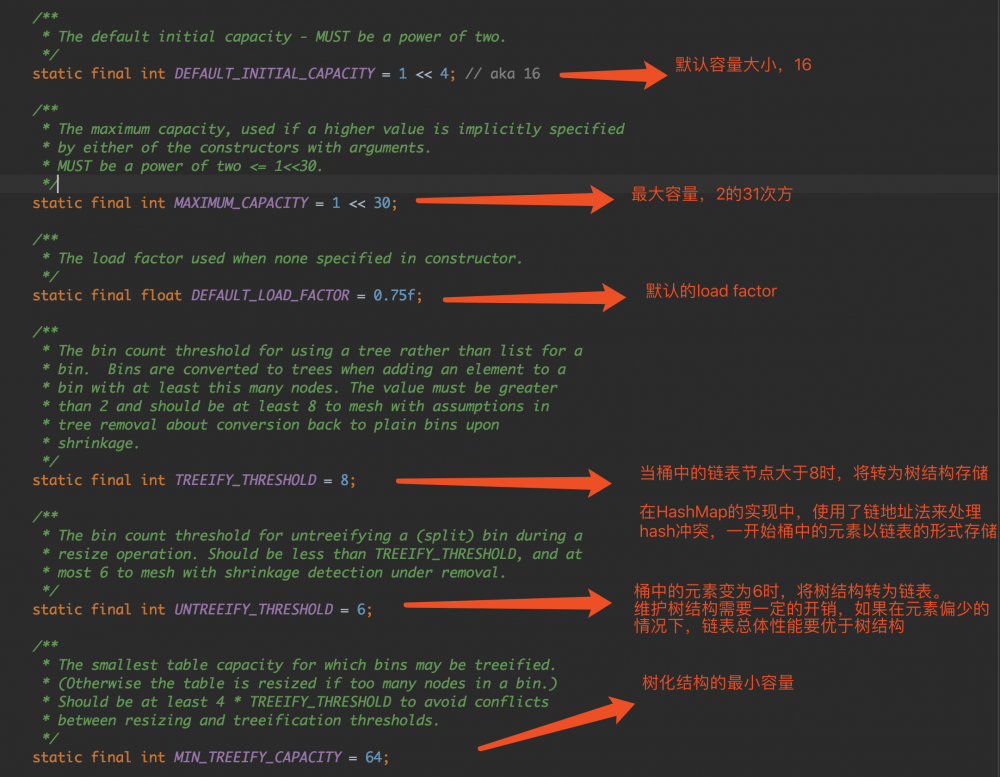
静态成员常量
构造器
默认初始化一个容量16、load factor为0.75的HashMap对象

put(key, value)操作

HashMap中的哈希算法
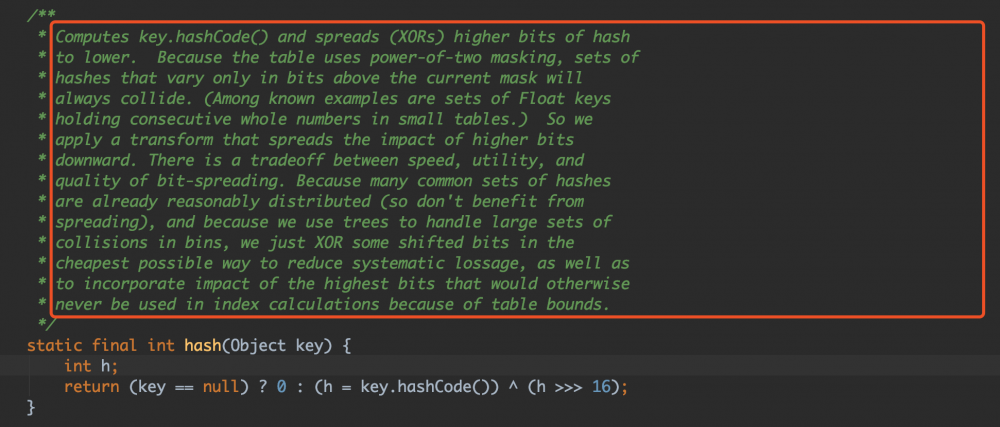
注释强调了:由于hash表使用了2的次方数作为容量大小,使用key.hashCode()和key.hashCode()的高16位进行异或运算得到的hash值,
可以减少hash冲突,为什么呢?这里先保有一个疑问,等理解了添加的流程之后再回过来看看
元素的添加操作
 在整个添加操作的过程中,有几个比较巧妙的地方
在整个添加操作的过程中,有几个比较巧妙的地方
-
通过key的hash值定位key在哈希表中的索引时,使用了位与运算代替了取余运算,极致提升性能
其中原理取决于我们构造出来的哈希表的容量为2 ^ n(2的n次方)
// 相当于tab[i = (hash % n)], n为容量大小 tab[i = (n - 1) & hash])
-
如何保证容量为2 ^ n(2的n次方)呢?
我们先来看一下resize()方法
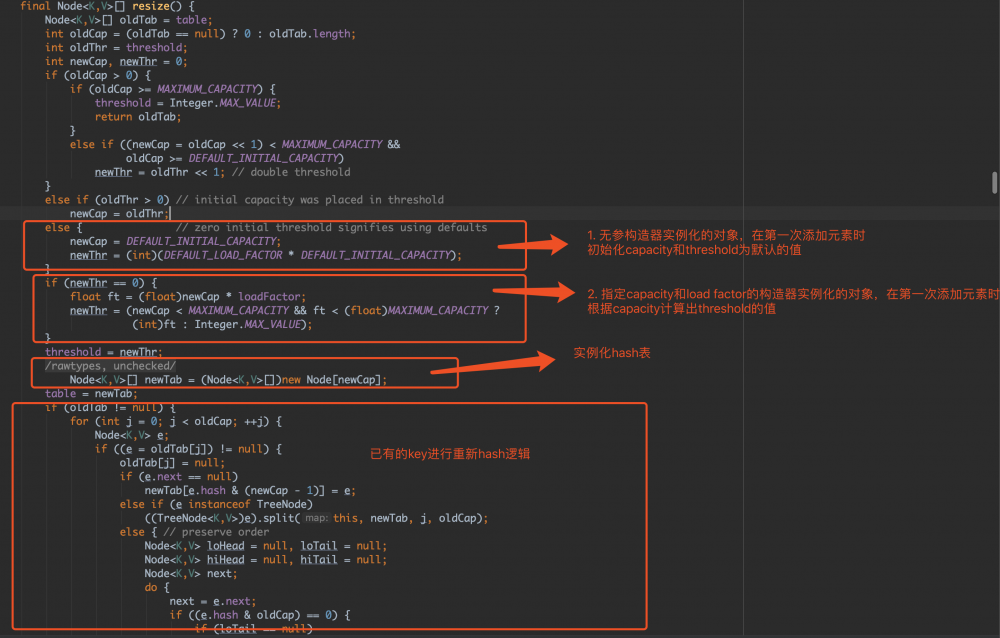
从代码可以看出
- 通过无参的构造器实例化一个对象时,容量是在方法resize()时进行分配。默认为16。
- 通过传入capacity、load factor参数的构造器时,容量是在方法tableSizeFor(initialCapacity)中计算得到的,大小为:比传入capacity大的最小2 ^ n(2的n次方)的数值
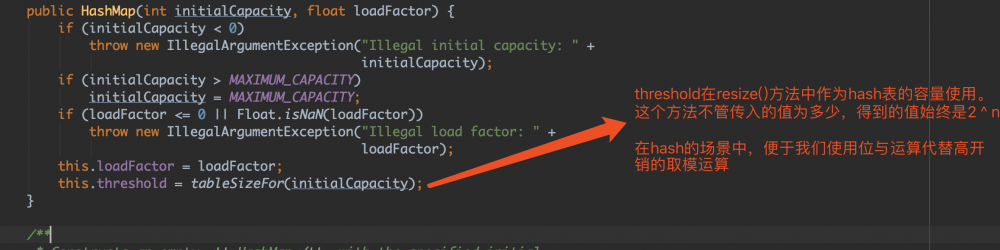 为什么tableSizeFor(capacity)可以保证返回的容量为2 ^ n
为什么tableSizeFor(capacity)可以保证返回的容量为2 ^ n - 现在回过头看一下之前留下来的问题,HashMap中的哈希算法为什么要使用key.hashCode() 与 key.hashCode >>> 16 进行异或?
这是因为在HashMap中,hash表的索引为 (hash表的长度 - 1) & hash。hash表的长度为2的幂次方,因此hash表的长度 - 1其实为低位的掩码,(hash表的长度 - 1) & hash 得到的是hash低位的值。通过以上的异或运算,可以保留key.hashCode()中高位的差异,减少hash冲突。
参考扰动函数
正文到此结束
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

