为什么不用原生 Spring Cloud Config?
引言
近几年传统应用架构已经逐渐朝着微服务架构演进。那么随着业务的发展,微服务越来越庞大,此时服务配置的管理变得会复杂起来。为了方便服务配置文件统一管理,实时更新,配置中心应运而生。
其实,所谓配置中心,就是将配置的数据放在某种存储介质中,该介质可以是
-
File(例如Git、Svn)
-
Database(例如mysql、oracle)
-
nosql Database(例如Redis、Memacache、MongoDb)
-
其他第三方中间件(例如Zookeeper)
那么配置中心可以简单理解为是封装了对这些介质进行操作的接口,供客户端拉取使用。
由于我们采用的是Spring-Boot的架构,因此当时自然而然会考虑到Spring-Cloud中提供的配置中心 Spring-Cloud-Config ,但是当时做完调研以后,觉得并不能直接用。
因此,本文想来分享一下,原生 Spring-Cloud-Config的配置中心的缺点,以及我们对
Spring-Cloud-Config
做了哪些改动。
正文
OK,我们当时做配置中心的选型的时候。第一选择是Spring-Cloud- Config。
Spring-Cloud-Config在存储介质的选择这块,基本上网上所有的文章都在推荐使用Git,即将配置文件放在Git中,服务端从Git中读取。其实官网上讲的最详细的配置,也是采取用Git作为存储介质。
因此,我相信大部分读者在生产上也是用Git作为存储介质,搭配Spring-Cloud-Config使用。
但是呢,博主认为以Git作为存储介质存在一些硬伤。
Git的权限控制是个坑
Git的权限管理是说控制用户能不能Push或者Delete分支,或者能不能Push代码,而不是能不能访问某个目录的文件。
对目录和文件的可读是Git的最基本要求,不可能做到针对目录级别的不可读。
因此如果直接使用,会出现这样一种情形
不同团队之间可以互看对方配置!
于是,可能会有如下情形发生
A团队同事A:"小B,这个地方不懂怎么配?"
A团队同事B:"去看看B团队的配置,直接贴过来。"
然后B团队就会发现自己的中间件里总是会多出一些莫名奇妙的数据!
当然,你可以禁止研发直接登陆Git改配置。然后呢,基于Git研发一套配置管理系统,在上面做权限控制,但是又有几个公司这么做呢?因为,这可能带来第二个问题。
粒度问题
将配置信息放在Git中,有一个致命问题: 粒度太粗了!
你每次对一条配置发生crud的操作,其带来的影响是整个文件发生变动。如果将来我们需要对某条配置做灰度发布,基于Git来做是比较麻烦的,注意了,我没说不能做,只是比较麻烦。
那么,当时我们最理想的存储介质就是数据库,将配置信息放在数据库里有 两个好处
-
基于数据库开发一套配置管理系统,显然比基于git来开发容易的多!
-
将配置放在数据库里,每条配置对应数据库的表中的一条记录。这么做粒度够细,针对某些重要的配置,做灰度发布,实现起来就容易很多。
因此,我们采用数据库作为存储介质。庆幸的是,这一点在Spring-Cloud-Config中是支持的。在该组件下,只需要设置
spring.profiles.active=jdbc
就能够激活jdbc模式。
但是我们很快发现了一个更大的问题,也正是因为这个问题,我们不得以需要进行改写Spring-Cloud-Config。
Spring-Cloud-Config的刷新机制是个坑!
因为一个配置中心应该要能够做到,配置发生改动的时候,项目能够自动感知,自动更新配置才对。在Spring-Cloud-Config中,这套机制是借助一些代码仓库(SVN、Github等)提供的Webhook机制加上Spring-Cloud-Bus来实现的。
在Webhook中配置一个回调地址,刷新流程如下图所示
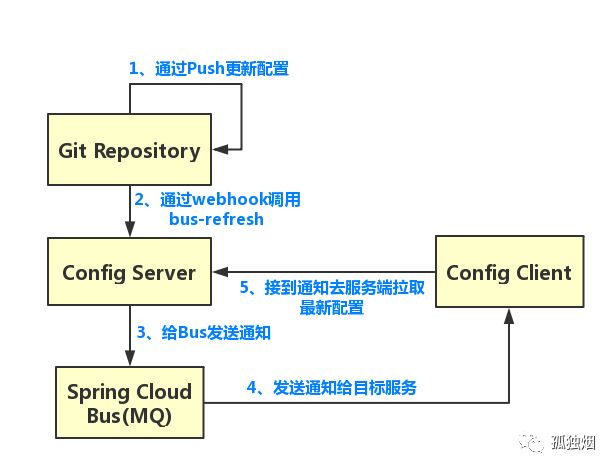
OK,那么问题又来了!
(1) 配置数据放在数据库中,数据库里没有Webhook这种东西啊,怎么做到实时刷新?
(2) Spring-Cloud-Config的这套刷新机制依赖于消息总线,依赖于消息队列,存在延迟的情况!且依赖于消息队列的可用性,系统的复杂度大大增加。如果生产环境上消息队列出问题了,我们的刷新功能就会受到影响!
所以,笔者认为这套刷新机制并不是很尽如人意,需要进行修改。因此,我们很自然而然的想到了利用长轮询来改写Spring-Cloud-Config的刷新机制!
长轮询是什么
既然有长轮询,那必定有短轮询,我顺便讲讲短轮询是什么!
假设我们有一个需求
在页面上要实时显示后台的库存数量!比如库存减少了,用户不需要进行刷新,页面上的数字自己会变化。
那么,如果采取短轮询就是在客户端(js)中不断访问后台,后台接到请求马上返回最新的库存数,然后刷新到这个页面当中。
短轮询的缺点?
很明显资源浪费。假设有几百人打开了该页面,就有几百个请求在不停的请求服务端,明显听着就不合理。
因此,自然就有了长轮询的出现!
其实也很简单,客户端(js)依然是不断的去请求。但是呢,服务端不是马上返回。而是等待库存数量变化了再返回。大家知道,HTTP都有超时时间。如果在该时间内,依然没有变化,客户端将再次发起请求。
注意了,长短轮询对于客户端来说是没有区别的,就是不断的轮询。但是对于服务端,区别就比较大了。在短轮询情况下,服务端对于每次请求不管有没有变化都会立即返回结果。而长轮询情况下,如果有变化才会立即返回结果。而如果没有变化,服务端则不会再立即给客户端返回结果,直到超时为止。
怎么实现
那么,我们在项目中采用Spring的DeferredResult来实现。在Servlet3.0以后引入了异步请求之后,Spring封装了一下提供了相应的支持,也就是DeferredResult,能够极大的提升吞吐量。
可能有人对Servlet的异步化不熟,我大概介绍一下。我们平时常用的是同步Servlet,其执行流程如下图所示
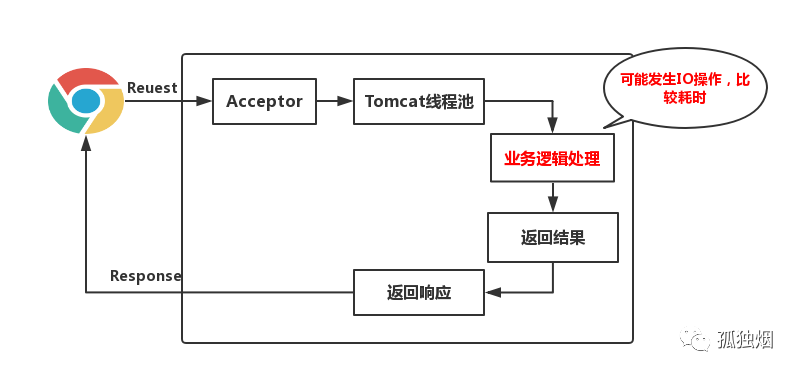
缺点很明显啦 ,业务逻辑线程和servlet容器线程是同一个,一般的业务逻辑总得发生点IO,比如查询数据库,比如产生RPC调用,这个时候就会发生阻塞,而我们的servlet容器线程肯定是有限的,当servlet容器线程都被阻塞的时候我们的服务这个时候就会发生拒绝访问,从而吞吐量上不去!
那么,你使用异步Servlet如下图所示
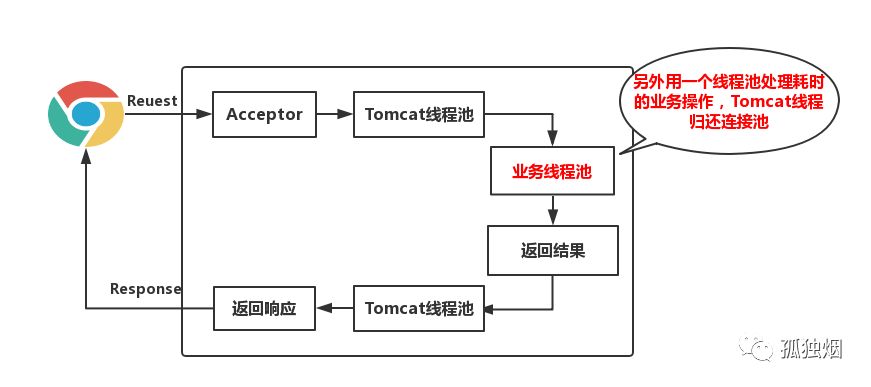
在异步Servlet中,业务线程有自己的线程池进行处理,并不会占用Tomcat中的线程,从而提升了吞吐量!
那么,怎么利用DeferredResult怎么实现长轮询呢? 流程如下
(1)客户端和服务端建立TCP连接
(2)客户端发起HTTP请求
(3)服务端发起请求,监听60s内是否有配置发生变动 (如何监听配置发生变动?)
(4)如果没发生变动,给客户端返回304标志位,客户端继续发起请求
(5)如果发生了变动,服务端会调用DeferredResult.setResult返回200状态码,客户端收到响应结果后,会发起请求获取变更后的配置信息。
最后一个问题:如何有效快速的监听出配置表的数据发生了变动?
因为我们用的是mysql。这里有一个Mysql的自定义函数叫mysql-udf-http。具有http_get()、http_post()、http_put()、http_delete()四个函数,可以在MySQL数据库中利用HTTP协议进行REST相关操作。
然后再和mysql的触发器结合起来用,可以实现在配置表发生变动的时候,主动通知我们的配置中心服务端。让服务端明白配置发生了变动!
一个疑问
采用长轮询技术来实现配置刷新,客户端和服务端需之间需要一直保持TCP连接进行通信。可能有些朋友会担心,到底服务端能撑多少的连接?可能觉得对性能有影响?
这里给出参考配置
使用了内存8G、4核的虚拟机约可以撑8000左右的连接!
总结
最后这套配置中心,我基于原有的Spring-Cloud-Config,改写其中的刷新机制,更加符合我们的业务场景!现已将改写思路说清,大家可以自行尝试!
正文到此结束
- 本文标签: GitHub web 开发 HTTP协议 https 配置中心 配置 TCP http mongo 线程 管理 spring REST IO git Spring Cloud Config NOSQL 时间 src db Mysql数据库 数据库 微服务 redis 目录 架构演进 cache SVN Spring cloud sql 需求 同步 tab 应用架构 Oracle JDBC 数据 mysql 消息队列 线程池 tomcat 权限控制 zookeeper 代码 协议 总结 服务端 js bus UI MongoDB 文章 servlet 灰度发布 cat
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

