剖析 Spring 多数据源
点击上方" 田守枝的技术博客 ",关注我
在实际开发中,经常会遇到应用要访问多个库的情况,需要配置多个数据源。本文会介绍spring多数据源的典型场景,如何优雅的实现多数据源,并结合spring、mybatis源码进行分析,为什么在事务中,不能切换数据源。最后,还会提供一个多数据源的完整源码案例。
1 多数据源的典型使用场景
在实际开发中,经常可能遇到在一个应用中可能需要访问多个数据库的情况,以下是两种典型场景。
1.1 业务复杂
数据分布在不同的数据库中,笔者见过一个相对比较复杂的业务,一个业务中同时操作了9个库,业务代码需要根据用户不同的操作,去访问不同的库。

1.2 读写分离
一些规模较小的公司,没有使用数据库访问层中间件。使用多数据源来实现简单的读写分离功能。
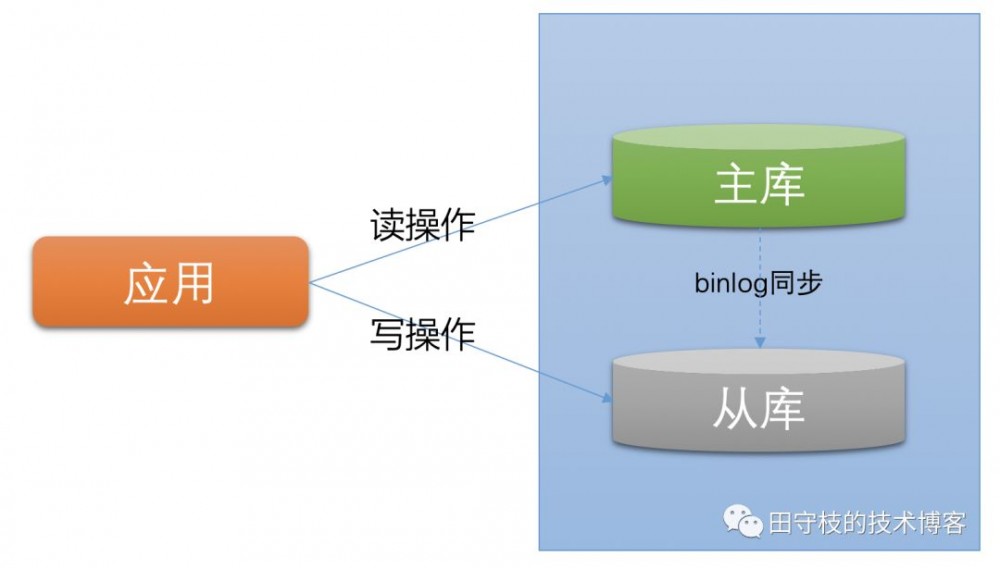
这里的架构与上图类似。不同的是,在读写分离中,主库和从库的数据库是一致的(不考虑主从延迟)。数据更新操作(insert、update、delete)都是在主库上进行,主库将数据变更信息同步给从库。在查询时,可以在从库上进行,从而分担主库的压力。
需要注意的是 ,使用多数据源实现的读写分离操作,需要开发人员自行判断执行的sql是读还是写。如果使用了数据库访问层中间件,通常会有中间件来实现读写分离的逻辑,对业务更加透明。
2 如何实现多数据源
对于大多数的java应用,都使用了spring框架,spring-jdbc模块提供了 AbstractRoutingDataSource ,其内部可以包含了多个DataSource,然后在运行时来动态的访问哪个数据库。这种方式访问数据库的架构图如下所示:
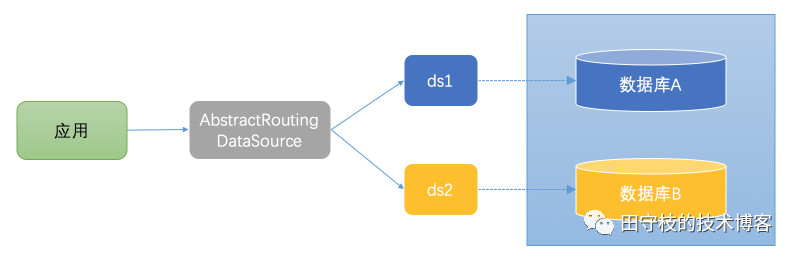
应用直接操作的是AbstractRoutingDataSource的实现类,告诉AbstractRoutingDataSource访问哪个数据库,然后由AbstractRoutingDataSource从事先配置好的数据源(ds1、ds2)选择一个,来访问对应的数据库。
关于如何利用AbstractRoutingDataSource实现多数据源访问,各种博客已经很多,基本功能都能实现,但是易用性不够好,要修改大量代码,业务侵入性太强。
这也是笔者为什么写这篇文章的原因,这里提供了一种更加简单易用的多数据源实现,笔者称之为 RoutingDataSource 。在读者对sprign-aop不是很了解的情况下,也能非常容易上手。而且笔者将这个组件发布到了maven中央仓库,因此你可以直接pom.xml中进行引用。
<dependency>
<groupId>io.github.tianshouzhi</groupId>
<artifactId>routing-datasource</artifactId>
<version>1.0.0</version>
</dependency>
routing-datasource中,最重要的就是以下两个组件: RoutingDataSource类: 其实现了类似于spring的AbstractRoutingDataSource的功能,内部管理了多个数据源。支持按照package(包名),指定这个包下面的类都访问方某个库。 @Routing注解 : 可以添加在类或接口上,也可以添加在方法上,实现更精确的数据源选择控制。 另外值得一提的是,@Routing注解支持与spring事务整合 。
3 RoutingDataSource配置
假设我们有2个库,db1(包含user表),db2(包含user_account表),如下
#数据库:db1
CREATE DATABASE `db1`;
USE `db1`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
#数据库:db2
CREATE DATABASE `db2`;
USE `db2`;
CREATE TABLE `user_account` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`account` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
接着,我们需要配置2个数据源分别来访问这个库,任何实现JDBC规范的数据源都可以(druid、c3p0、dbcp、tomcat-jdbc等)。
<!--配置ds1,访问数据库db1-->
<bean id="ds1" class="org.apache.ibatis.datasource.pooled.PooledDataSource">
<property name="username" value="root"/>
<property name="password" value="shxx12151022"/>
<property name="url" value="jdbc:mysql://localhost:3306/db1"/>
<property name="driver" value="com.mysql.jdbc.Driver"/>
</bean>
<!--配置ds2,访问数据库db2-->
<bean id="ds2" class="org.apache.ibatis.datasource.pooled.PooledDataSource">
<property name="username" value="root"/>
<property name="password" value="shxx12151022"/>
<property name="url" value="jdbc:mysql://localhost:3306/db2"/>
<property name="driver" value="com.mysql.jdbc.Driver"/>
</bean>
接下来,我们需要将这两个数据源交给RoutingDataSource管理。
<!--配置RoutingDataSource,其管理了ds1和ds2-->
<bean id="routingDataSource" class="io.github.tianshouzhi.routing.RoutingDataSource">
<property name="targetDataSources">
<map>
<!--entry的key,将在稍后将看到的@Routing注解中使用到-->
<entry key="ds1" value-ref="ds1"/>
<entry key="ds2" value-ref="ds2"/>
</map>
</property>
<!--配置默认数据源,在RoutingDataSource无法确定使用哪个数据源时,将会使用默认的数据源-->
<property name="defaultTargetDataSource" value="ds1"/>
</bean>
在实际开发中,我们通常不会直接操作数据源,而是与ORM框架进行整合,这里选用mybatis,因此需要添加mybatis相关配置
<!--配置mybatis的SqlSessionFactoryBean,注入datasource属性引用的是routingDataSource-->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="routingDataSource”/>
<!--注意,如果你sql写在xml中,需要打开以下配置,本案例写在映射器接口上-->
<!--<property name="mapperLocations" value="classpath*:config/sqlmap/**/*.xml" />-->
</bean>
<!--配置MapperScannerConfigurer-->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
<!--UserMapper和UserAccountMapper位于此包中-->
<property name="basePackage" value="io.github.tianshouzhi.routing.mapper"/>
</bean>
另外,我们编写了2个mybatis映射器(源码见后文): UserMapper和UserAccountMapper,分别用于访问db1.user表和db2.user_account表。之后我们就可以通过这两个接口上添加 @Routing 注解,来让其访问不同的库。
4 @Routing注解的基本使用
@Routing可以在方法上使用,也可以在类或者接口上使用,以下是Routing注解的使用说明。
4.1 方法上添加@Routing注解
public interface UserMapper {
@Routing("ds1")
//通过@Routing注解,指定此方法走ds1数据源
public User selectById(@Param("id") int id);
//未添加注解,将走默认的数据源
public int insert(User user);
}
上述接口定义了2个方法:
selectById方法:添加了@Routing("ds1")注解,表示通过其访问数据库,都会选择ds1数据源。
insert方法:没有添加注解,因此将走默认的数据源。也就是前面 配置RoutingDataSource时,指定的ds1。
4.2 接口或类上添加@Routing注解
例如我们在UserAccountMapper接口上定义了@Routing注解,接口中定义的2个方法都会走ds2数据源访问db2,而user_account位于db2中 :
@Routing("ds2")
public interface UserAccountMapper {
UserAccount selectById(@Param("id") int id);
int insert(UserAccount userAccount);
}
提示:通常我们一个Mapper接口操作的都是某个库中的表,因此建议直接在接口上添加@Routing注解,而不是每个方法单独添加。(读写分离操作除外)
4.3 接口、方法上都添加@Routing注解
@Routing("ds2")
public interface UserAccountMapper {
//使用接口上@Routing注解指定的ds2数据源
UserAccount selectById(@Param("id") int id);
//使用方法上@Routing注解指定的ds1数据源
//注意:这是一个错误的示例,因为user_account表位于db2中
@Routing("ds1")
int insert(UserAccount userAccount);
}
4.4 包(package)级别的数据源映射
如果项目的目录结构划分的比较好,操作不同的库的Mapper接口,位于不同的package下,如:
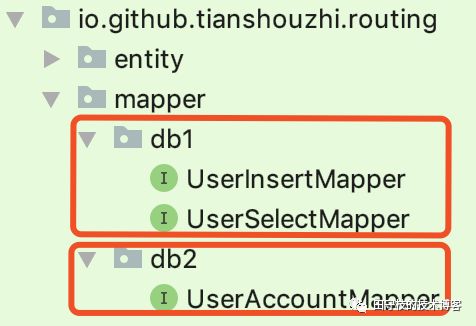
上图中, db1包下都是操作db1的映射器接口 db2包下都是操作db2的映射器接口。 此时你可以修改前面的RoutingDataSource配置,通过添加如下配置,直接定义某个package下的映射器,都访问某个库,从而无需在每个接口上都定义@Routing注解。
<bean id="routingDataSource" class="io.github.tianshouzhi.routing.RoutingDataSource">
...
<property name="packageDataSourceKeyMap">
<map>
<entry key="io.github.tianshouzhi.routing.mapper.db1" value="ds1"/>
<entry key="io.github.tianshouzhi.routing.mapper.db2" value="ds2"/>
</map>
</property>
</bean>
注:对于@Routing注解优先级,优先级满足以下条件:方法>接口>包
4.5 service层调用
Mapper映射器接口属于dao层,通常dao层的代码都是在service层进行调用的,业务层的接口也可以添加@Routing注解,如果没有添加。则由调用的Mapper映射器方法、接口上的@Routing注解决定使用哪个ds,如果都没有没有定义,则使用默认的数据源
public void business(int userId,int userAccountId) {
userAccountMapper.selectById(userAccountId);
userMapper.selectById(userId);
}
4.6 service层添加@Routing注解
业务层方法添加@Routing注解后,将 忽略 内部调用的Mapper映射器方法、接口上的Routing注解 , 内部调用的所有mapper映射器都会以业务层@Routing注解为准 , 这是为了与事务的语义兼容(见事务整合分析) 。如:
//指定方法内部调用的映射器接口,都必须使用ds2
@Routing("ds2")
public void business(int userId,int userAccountId) {
//user_account表位于db2中,因此访问可以成功
userAccountMapper.selectById(userAccountId);
//注意:user表位于db1中,这里强制使用ds2,因此将执行失败
userMapper.selectById(userId);
}
4.7 @Routing注解的事务支持
@Routing注解可以与spring的事务联合使用, 注意要保证事务中的方法必须都访问的是同一个库中的表 。
4.7.1 事务管理器配置
Spring的事务管理器,通过 PlatformTransactionManager 接口表示,其有2个重要的实现类:
DataSourceTransactionManager :用于支持本地事务,事实上,其内部也是通过操作java.sql.Connection来开启、提交和回滚事务。
JtaTransactionManager :用于支持分布式事务,其实现了JTA规范,使用XA协议进行两阶段提交。需要注意的是,这只是一个代理,我们需要为其提供一个JTA provider,一般是Java EE容器提供的事务协调器(Java EE server's transaction coordinator),也可以不依赖容器,配置一个本地的JTA provider。 关于分布式事务,不在本文的讨论范畴内,感兴趣的读者,可以参考笔者博客上一篇文章,如何使用atomikos来实现分布式事务,地址如下:
http://www.tianshouzhi.com/api/tutorials/distributed_transaction/386
显然,在这里,我们配置的是DataSourceTransactionManager,意味着这里的多数据源不支持分布式事务。
由于RoutingDataSource管理了多个数据源,因此事务管理引用的应该也是RoutingDataSource,以下是声明式事务@Transactional注解的案例:
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="routingDataSource"/>
</bean>
<tx:annotation-driven />
这里有必要介绍一下,为什么DataSourceTransactionManager不支持分布式事务 。熟悉JDBC编程的同学应该知道,我们可以通过以下方式开开启或者提交一个事务
DataSource ds=...
Connection conn=ds.getConnection();
//开启事务
conn.setAutoCommit(false);
....CRUD操作
//提交事务
conn.commit();
可以看到,事务管理实际上是与Connection绑定的,而Connection又是从某个DataSource中获得的。一个DataSource只能操作一个库,由于我们在配置spring事务管理器DataSourceTransactionManager时,指定了某个DataSource,显然意味着其只能对某个库进行事务操作。
尽管我们这里 配置的数据源是笔者提供的RoutingDataSource,其内部管理了多个其他数据源,但是依然不能支持分布式事务,因为 RoutingDataSource在运行时,根据配置选择其管理的某一个特定的数据源,交给spring事务管理器来使用。
另外,一点需要注意的是,在事务中无法切换数据源。 spring的@Transactional注解,无非一个切入点,spring会对添加了 @Transactional注解方法的类进行代理。在这个方法执行之前,就从数据源中获取Connection,开启事务;在方法执行之后,根据是否没有抛出异常,提交或者回滚事务。 这里其实隐含了一个很重要的知识点,对于添加了@Transactional注解的方法,在方法执行之前,Spring已经通过DataSource获取到Connection,并开启了事务,在整个事务方法执行结束前,一直都是使用这个Connection,无法进行切换 。 spring开启事务的源码,可以参考 DataSourceTransactionManager.doBegin方法:
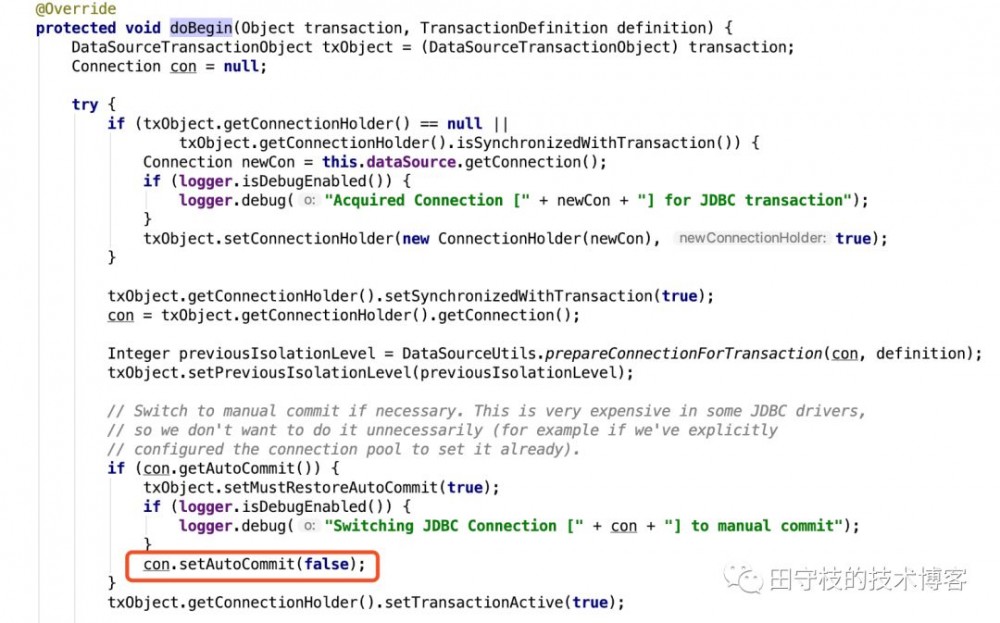
可以看到, DataSourceTransactionManager实际上,也是通过我们提供的数据源,获取到Connection,通过setAutoCommit(false)来开启事务,与我们熟悉的JDBC编程没有什么区别。
而在Spring开启事务后,底层的ORM框架在访问数据库时, 会从spring线程上下文中获取开启事务Connection,也就是说,事务中所有数据库操作,使用的都是同一个Connection 。以mybatis为例,其通过mybatis-spring模块与spring整合,mybatis-spring中有一个SpringManagedTransaction类,在创建一个Connection操作数据库,其会通过spring-jdbc模块提供的DataSourceUtils工具类,来获取Connection,如下:
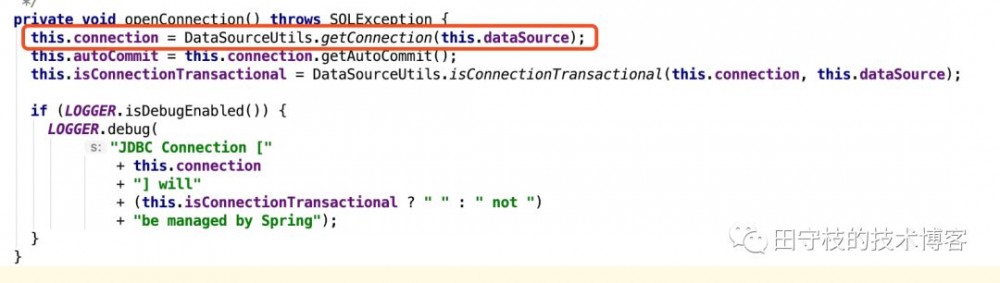
DataSourceUtils.getConnection方法内部会先尝试从spring提供的线程上下文中获得Connection,如果spring开启了事务,这个Connection必然存在。接着,mybatis会使用这个Connection创建Statement或者PreparedStatement,来完成增删改查操作。
通过上述代码分析,读者应该知道了,为什么在事务中,不能切换数据源。因为spring开启事务后,使用的Connection就已经确定了,整个事务中都会使用同一个Connection。而一个Connection,必然只能属于一个DataSource。
对于笔者提供的多数据源RoutingDataSource来说,其要完成的功能就是,在spring开启事务之前,就告诉应该使用哪个数据源,这个依然是通过@Routing注解来完成的。
4.7.2 只使用@Transactional注解
只使用@Transactional注解,方法内部的操作,都只能访问默认数据源。会忽略内部调用的其他方法的@Routing注解。 如果访问了其他库中的表,将会报错。
@Transactional
public void testDefaultTransaction(User user,UserAccount userAcccount) {
//默认数据源是ds1,可以访问db1中user表,因此插入成功
userMapper.insert(user);
//注意:这个方法将执行失败,事务将回滚,因为user_account位于db2中
userAccountMapper.insert(userAcccount)
}
4.7.3 同时使用@Transactional/@Routing
spring事务管理器将会使用@Routing注解中指定的数据源来开启事务
@Transactional
@Routing("ds2”) //使用ds2开启事务
public void testRoutingTransaction(User user,UserAccount userAcccount) {
userAccountMapper.insert(userAccount);
//注意:这个方法将执行失败,事务将回滚,因为user位于db1中
userMapper.insert(user);
}
6 总结
虽然笔者提供了一个RoutingDataSource,并发布到了maven中央仓库,但是并没有期望真的会有人使用  。想告诉读者的是,"知其然,知其所以然"。如果你对多数据源的实现细节比较感兴趣,可以 通过git 克隆项目源码进行研究:
。想告诉读者的是,"知其然,知其所以然"。如果你对多数据源的实现细节比较感兴趣,可以 通过git 克隆项目源码进行研究:
git clone https://github.com/tianshouzhi/routing-datasource.git
研究源码时,请主要思考以下问题:
1、笔者提供了一个@Routing注解,但是并没有spring aop配置,就实现了AOP切换功能,是如何实现的。因为 @Routing本身也要对类代理,才能告诉spring框架使用哪个数据源。
2、 @Routing注解和spring提供的@Transactional注解,都需要对类进行代理,且前者需要在后者之前发挥作用。是使用二次代理?还是其他更优雅的方式?
近期发表:
Mysql分支选择:Percona Or MariaDB
异地多活场景下的数据同步之道
分布式事务概述
数据库中间件详解
识别二维码关注我

正文到此结束
- 本文标签: root Select sqlsession session provider cat 博客 API bean 目录 id tab value 并发 https dataSource UI autocommit apache App mapper bus pom 总结 压力 http 管理 Service mysql iBATIS 源码 key druid git C3P0 配置 文章 CTO SqlSessionFactory update token maven 开发 线程 src NSA Action AOP classpath XML Statement ip DBCP map ACE 代码 ORM java 数据库访问 db mybatis 数据库 dist IDE Property 协议 分布式事务 IO JDBC tomcat 同步 sql Word GitHub 业务层 spring 分布式 db2 二维码 tar Connection 数据 Atom
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

