如何设计并实现一个db连接池?

连接池的使命!
无论是线程池还是db连接池,他们都有一个共同的特性: 资源复用 ,在普通的场景中,我们使用一个连接,它的生命周期可能是这样的:
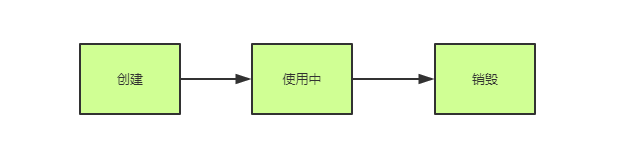
一个连接,从创建完毕到销毁,期间只被使用了一次(这里的一次是指在单个作用域内的使用),当周期结束,另外一个调用者仍然需要这个连接去做事,就要重复去经历这种生命周期。因为创建和销毁都是需要对应的服务消耗时间以及系统资源去处理的,这样不仅浪费了大量的系统资源,而且导致业务响应过程中都要花费部分时间去重复的创建和销毁,得不偿失,而连接池便被赋予了解决这种问题的使命!
连接池需要做什么?
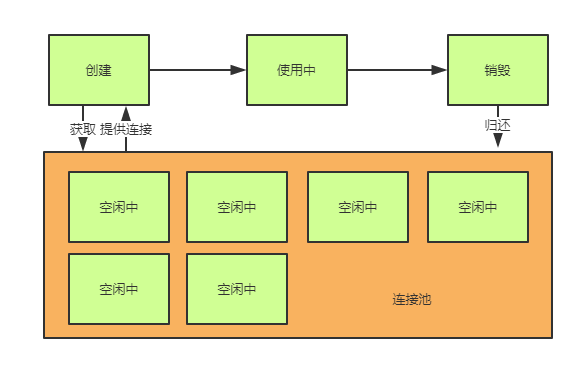
顾名思义,连接池中的 池 字已经很生动形象的阐明了它的用意,它用将所有连接放入一个 "池子" 中统一的去控制连接的创建和销毁,和原始生命周期去对比,连接池多了以下特性:
- 创建并不是真的创建,而是从池子中选出空闲连接。
- 销毁并不是真的销毁,而是将使用中的连接放回池中(逻辑关闭)。
- 真正的创建和销毁由线程池的特性机制来决定。
因此,当使用连接池后,我们使用一个连接的生命周期将会演变成这样:
分析计划
通灵之术 - 传送门: github.com/ainilili/ho… ,DEMO为Java语言实现!
事前,我们需要点支烟分析一下时间一个连接池需要做哪些事情:
- 保存连接的容器是必不可少的,另外,该容器也要支持连接的添加和移除功能,并保证线程安全。
- 我们需要因为要对连接的销毁做逻辑调整,我们需要重写它的
close以及isClosed方法。 - 我们需要有个入口对连接池做管理,例如回收空闲连接。
连接池不仅仅只是对 Connection 生命周期的控制,还应该加入一些特色,例如初始连接数,最大连接数,最小连接数、最大空闲时长以及获取连接的等待时长,这些我们也简单支持一下。
目标以明确,开始动工。
连接池容器选型
要保证线程安全,我们可以将目标瞄准在 JUC 包下的神通们,设我们想要的容器为 x ,那么 x 不仅需要满足基本的增删改查功能,而且也要提供获取超时功能,这是为了保证当池内长时间没有空闲连接时不会导致业务阻塞,即刻熔断。另外, x 需要满足双向操作,这是为了连接池可以识别出饱和的空闲连接,方便回收操作。
综上所述, LinkedBlockingDeque 是最合适的选择,它使用 InterruptibleReentrantLock 来保证线程安全,使用 Condition 来做获取元素的阻塞,另外支持双向操作。
另外,我们可以将连接池拆分为3个类型:
- 工作池 :存放正在被使用的连接。
- 空闲池 :存放空闲连接。
- 回收池 :已经被回收(物理关闭)的连接。
其中, 工作池 和 回收池 大可不必用双向对列,或许用单向队列或者 Set 都可以代替之:
private LinkedBlockingQueue<HoneycombConnection> workQueue; private LinkedBlockingDeque<HoneycombConnection> idleQueue; private LinkedBlockingQueue<HoneycombConnection> freezeQueue; 复制代码
Connection的装饰
连接池的输出是 Connection ,它代表着一个db连接,上游服务使用它做完操作后,会直接调用它的 close 方法来释放连接,而我们必须做的是在调用者无感知的情况下改变它的关闭逻辑,当调用 close 的方法时,我们将它放回空闲队列中,保证其的可复用性!
因此,我们需要对原来的 Connection 做装饰,其做法很简单,但是很累,这里新建一个类来实现 Connection 接口,通过重写所有的方法来实现一个**"可编辑"**的 Connection ,我们称之为 Connection 的装饰者:
public class HoneycombConnectionDecorator implements Connection{
protected Connection connection;
protected HoneycombConnectionDecorator(Connection connection) {
this.connection = connection;
}
此处省略对方法实现的三百行代码...
}
复制代码
之后,我们需要新建一个自己的 Connection 来继承这个装饰者,并重写相应的方法:
public class HoneycombConnection extends HoneycombConnectionDecorator implements HoneycombConnectionSwitcher{
@Override
public void close() { do some things }
@Override
public boolean isClosed() throws SQLException { do some things }
省略...
}
复制代码
DataSource的重写
DataSource 是JDK为了更好的统合和管理数据源而定义出的一个规范,获取连接的入口,方便我们在这一层更好的扩展数据源(例如增加特殊属性),使我们的连接池的功能更加丰富,我们需要实现一个自己的 DataSource 能:
public class HoneycombWrapperDatasource implements DataSource{
protected HoneycombDatasourceConfig config;
省略其它方法的实现...
@Override
public Connection getConnection() throws SQLException {
return DriverManager.getConnection(config.getUrl(), config.getUser(), config.getPassword());
}
@Override
public Connection getConnection(String username, String password) throws SQLException {
return DriverManager.getConnection(config.getUrl(), username, password);
}
省略其它方法的实现...
}
复制代码
我们完成了对数据源的实现,但是这里获取连接的方式是物理创建,我们需要满足池化的目的,需要重写 HoneycombWrapperDatasource 中的连接获取逻辑,做法是创建一个新的类对父类方法重写:
public class HoneycombDataSource extends HoneycombWrapperDatasource{
private HoneycombConnectionPool pool;
@Override
public Connection getConnection() throws SQLException {
这里实现从pool中取出连接的逻辑
}
省略...
}
复制代码
特性扩展
在当前结构体系下,我们的连接池逐渐浮现出了雏形,但远远不够的是,我们需要在此结构下可以做自由的扩展,使连接池对连接的控制更加灵活,因此我们可以引入 特性 这个概念,它允许我们在其内部访问连接池,并对连接池做一系列的扩展操作:
public abstract class AbstractFeature{
public abstract void doing(HoneycombConnectionPool pool);
}
复制代码
AbstractFeature 抽象父类需要实现 doing 方法,我们可以在方法内部实现对连接池的控制,其中一个典型的例子就是对池中空闲连接左回收:
public class CleanerFeature extends AbstractFeature{
@Override
public void doing(HoneycombConnectionPool pool) {
这里做空闲连接的回收
}
}
复制代码
落实计划
经过上述分析,要完成一个连接池,需要这些模块的配合,总体流程如下:
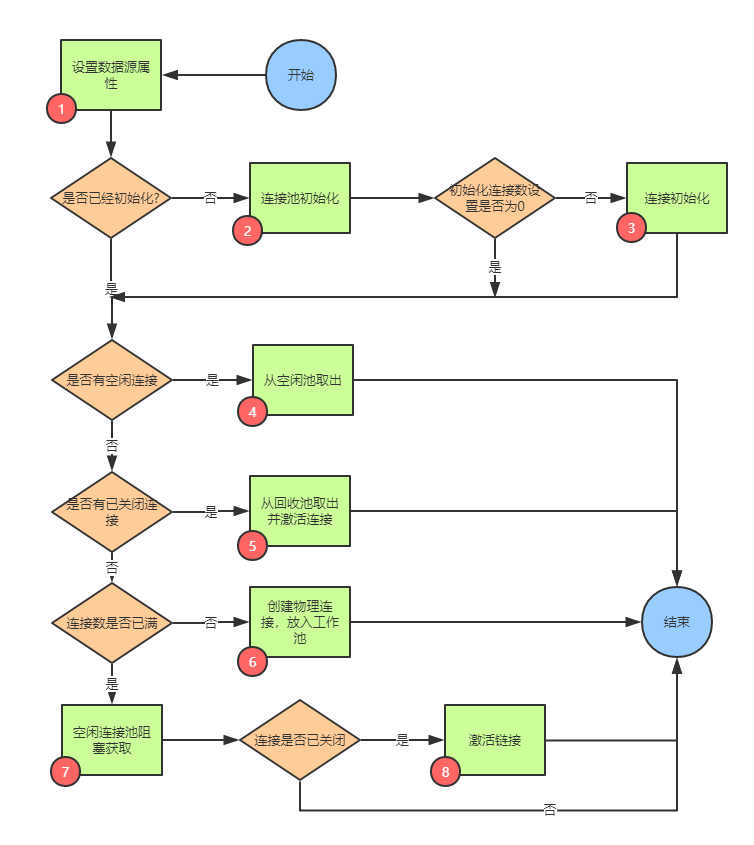
第一步:设置数据源属性
在初始化 DataSource 之前,我们需要将各属性设置进去,这里使用 HoneycombWrapperDatasource 中的 HoneycombDatasourceConfig 来承载各属性:
public class HoneycombDatasourceConfig {
//db url
private String url;
//db user
private String user;
//db password
private String password;
//driver驱动
private String driver;
//初始化连接数,默认为2
private int initialPoolSize = 2;
//最大连接数,默认为10
private int maxPoolSize = 10;
//最小连接数,默认为2
private int minPoolSize = 2;
//获取连接时,最大等待时长,默认为60s
private long maxWaitTime = 60 * 1000;
//最大空闲时长,超出要被回收,默认为20s
private long maxIdleTime = 20 * 1000;
//特性列表
private List<AbstractFeature> features;
public HoneycombDatasourceConfig() {
features = new ArrayList<AbstractFeature>(5);
}
省略getter、setter....
复制代码
第二步:初始化连接池
设置好属性之后,我们需要完成连接池的初始化工作,在 HoneycombDataSource 的 init 方法中实现:
private void init() throws ClassNotFoundException, SQLException {
//阻塞其他线程初始化操作,等待初始化完成
if(initialStarted || ! (initialStarted = ! initialStarted)) {
if(! initialFinished) {
try {
INITIAL_LOCK.lock();
INITIAL_CONDITION.await();
} catch (InterruptedException e) {
} finally {
INITIAL_LOCK.unlock();
}
}
return;
}
//config参数校验
config.assertSelf();
Class.forName(getDriver());
//实例化线程池
pool = new HoneycombConnectionPool(config);
//初始化最小连接
Integer index = null;
for(int i = 0; i < config.getInitialPoolSize(); i ++) {
if((index = pool.applyIndex()) != null) {
pool.putLeisureConnection(createNativeConnection(pool), index);
}
}
//触发特性
pool.touchFeatures();
//完成初始化并唤醒其他阻塞
initialFinished = true;
try {
INITIAL_LOCK.lock();
INITIAL_CONDITION.signalAll();
}catch(Exception e) {
}finally {
INITIAL_LOCK.unlock();
}
}
复制代码
第三步:创建初始连接
在 init 的方法中,如果 initialPoolSize 大于0,会去创建指定数量的物理连接放入连接池中,创建数量要小于最大连接数 maxPoolSize :
public HoneycombConnection createNativeConnection(HoneycombConnectionPool pool) throws SQLException {
return new HoneycombConnection(super.getConnection(), pool);
}
复制代码
完成初始化后,下一步就是获取连接。
第四步:从空闲池获取
我们之前将连接池分成了三个,它们分别是 空闲池 、 工作池 和 回收池 。
我们可以通过 HoneycombDataSource 的 getConnection 方法来获取连接,当我们需要获取时,首先考虑的是空闲池是否有空闲连接,这样可以避免创建和激活新的连接:
@Override
public Connection getConnection() throws SQLException {
try {
//初始化连接池
init();
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
HoneycombConnection cn = null;
Integer index = null;
if(pool.assignable()) {
//空闲池可分配,从空闲池取出
cn = pool.getIdleConnection();
}else if(pool.actionable()) {
//回收池可分配,从回收池取出
cn = pool.getFreezeConnection();
}else if((index = pool.applyIndex()) != null) {
//如果连接数未满,创建新的物理连接
cn = pool.putOccupiedConnection(createNativeConnection(pool), index);
}
if(cn == null) {
//如果无法获取连接,阻塞等待空闲池连接
cn = pool.getIdleConnection();
}
if(cn.isClosedActive()) {
//如果物理连接关闭,则获取新的连接
cn.setConnection(super.getConnection());
}
return cn;
}
复制代码
第五步:从回收池获取
如果空闲池不可分配,那么说明连接供不应求,也许之前有些空闲连接已经被回收(物理关闭),那么我们在创建新连接之前,可以到回收池看一下是否存在已回收连接,如果存在直接取出:
else if(pool.actionable()) {
//回收池可分配,从回收池取出
cn = pool.getFreezeConnection();
}
复制代码
第六步:创建新的连接
如果回收池也不可分配,此时要判断连接池连接数量是否已经达到最大连接,如果没有达到,创建新的物理连接并直接添加到工作池中:
else if((index = pool.applyIndex()) != null) {
//如果连接数未满,创建新的物理连接,添加到工作池
cn = pool.putOccupiedConnection(createNativeConnection(pool), index);
}
复制代码
第七步:等待空闲池的连接
如果上述三种情况都不满足,那么只能从空闲池等待其他连接的释放:
if(cn == null) {
//如果无法获取连接,阻塞等待空闲池连接
cn = pool.getIdleConnection();
}
复制代码
具体逻辑封装在 HoneycombConnectionPool 的 getIdleConnection 方法中:
public HoneycombConnection getIdleConnection() {
try {
//获取最大等待时间
long waitTime = config.getMaxWaitTime();
while(waitTime > 0) {
long beginPollNanoTime = System.nanoTime();
//设置超时时间,阻塞等待其他连接的释放
HoneycombConnection nc = idleQueue.poll(waitTime, TimeUnit.MILLISECONDS);
if(nc != null) {
//状态转换
if(nc.isClosed() && nc.switchOccupied() && working(nc)) {
return nc;
}
}
long timeConsuming = (System.nanoTime() - beginPollNanoTime) / (1000 * 1000);
//也许在超时时间内获取到了连接,但是状态转换失败,此时刷新超时时间
waitTime -= timeConsuming;
}
} catch (Exception e) {
e.printStackTrace();
}finally {
}
throw new RuntimeException("获取连接超时");
}
复制代码
第八步:激活连接
最后,判断一下连接是否被物理关闭,如果是,我们需要打开新的连接替换已经被回收的连接:
if(cn.isClosedActive()) {
//如果物理连接关闭,则获取新的连接
cn.setConnection(super.getConnection());
}
复制代码
连接的回收
如果在某段时间内我们的业务量剧增,那么需要同时工作的连接将会很多,之后过了不久,我们的业务量下降,那么之前已经创建的连接明显饱和,这时就需要我们对其进行回收,我们可以通过 AbstractFeature 入口操作连接池。
对于回收这个操作,我们通过 CleanerFeature 来实现:
public class CleanerFeature extends AbstractFeature{
private Logger logger = LoggerFactory.getLogger(CleanerFeature.class);
public CleanerFeature(boolean enable, long interval) {
//enable表示是否启用
//interval表示扫描间隔
super(enable, interval);
}
@Override
public void doing(HoneycombConnectionPool pool) {
LinkedBlockingDeque<HoneycombConnection> idleQueue = pool.getIdleQueue();
Thread t = new Thread() {
@Override
public void run() {
while(true) {
try {
//回收扫描间隔
Thread.sleep(interval);
//回收时,空闲池上锁
synchronized (idleQueue) {
logger.debug("Cleaner Model To Start {}", idleQueue.size());
//回收操作
idleQueue.stream().filter(c -> { return c.idleTime() > pool.getConfig().getMaxIdleTime(); }).forEach(c -> {
try {
if(! c.isClosedActive() && c.idle()) {
c.closeActive();
pool.freeze(c);
}
} catch (SQLException e) {
e.printStackTrace();
}
});
logger.debug("Cleaner Model To Finished {}", idleQueue.size());
}
}catch(Throwable e) {
logger.error("Cleaner happended error", e);
}
}
}
};
t.setDaemon(true);
t.start();
}
}
复制代码
这里的操作很简单,对空闲池加锁,扫描所有连接,释放空闲时间超过最大空闲时间设置的连接,其实这里只要知道当前连接的空闲时长就一目了然了,我们在连接放入空闲池时候去刷新他的空闲时间点,那么当前的空闲时长就等于当前时间减去空闲开始时间:
idleTime = nowTime - idleStartTime 复制代码
在切换状态为空闲时刷新空闲开始时间:
@Override
public boolean switchIdle() {
return unsafe.compareAndSwapObject(this, statusOffset, status, ConnectionStatus.IDLE) && flushIdleStartTime();
}
复制代码
测试一下
体验成果的最快途径就是投入使用,这里搞一个单元测试体验一下:
static ThreadPoolExecutor tpe = new ThreadPoolExecutor(1000, 1000, 0, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
@Test
public void testConcurrence() throws SQLException, InterruptedException{
long start = System.currentTimeMillis();
HoneycombDataSource dataSource = new HoneycombDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&useSSL=false&transformedBitIsBoolean=true&zeroDateTimeBehavior=CONVERT_TO_NULL&serverTimezone=Asia/Shanghai");
dataSource.setUser("root");
dataSource.setPassword("root");
dataSource.setDriver("com.mysql.cj.jdbc.Driver");
dataSource.setMaxPoolSize(50);
dataSource.setInitialPoolSize(10);
dataSource.setMinPoolSize(10);
dataSource.setMaxWaitTime(60 * 1000);
dataSource.setMaxIdleTime(10 * 1000);
dataSource.addFeature(new CleanerFeature(true, 5 * 1000));
test(dataSource, 10000);
System.out.println(System.currentTimeMillis() - start + " ms");
}
public static void test(DataSource dataSource, int count) throws SQLException, InterruptedException {
CountDownLatch cdl = new CountDownLatch(count);
for(int i = 0; i < count; i ++) {
tpe.execute(() -> {
try {
HoneycombConnection connection = (HoneycombConnection) dataSource.getConnection();
Statement s = connection.createStatement();
s.executeQuery("select * from test limit 1");
connection.close();
}catch(Exception e) {
}finally {
cdl.countDown();
}
});
}
cdl.await();
tpe.shutdown();
}
复制代码
PC配置: Intel(R) Core(TM) i5-8300H CPU @ 2.30GHz 2.30 GHz 4核8G 512SSD
10000次查询,耗时:
938 ms 复制代码
结束语:再次召唤传送门: github.com/ainilili/ho…
正文到此结束
- 本文标签: 线程 Features 管理 连接池 参数 git 生命 配置 IO CTO 单元测试 java dataSource swap queue NSA synchronized list db http sql executor 时间 Statement mysql ThreadPoolExecutor tar 线程池 IDE ArrayList 实例 测试 core 安全 ORM 代码 JDBC final ACE 数据 bug Select ssl src cat Action GitHub CountDownLatch 锁 https Word UI id App stream root Connection
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

