(Java篇)爬取微信公众号文章并保存为 PDF 格式
背景:某一天,拿着自己的手机看着技术文章,然而手机看技术文章,有时候确实蛋疼,因为一旦代码多起来,小屏幕看的还是眼花;又或者某一天觉得这一篇文章,觉得写的很棒棒哦,于是先收藏,打算过几天看,然后等我几天再次打开收藏的文章,卧X,居然被作者删了···;或者想对某个博主的文章进行分类···
于是就萌生了能不能爬下“微信公众号”文章,保存到电脑的想法
如今普天盖地的安利 Python ,虽然有着“人生苦短,我用 Python”一说,但我还是想在「爬虫」这方面支持一下我大 Java (好吧,其实自己折腾一番,还是写着 Java 舒服,平时写 python 还是少)
一、抓包
关于手机抓包(这里指 Android 手机),推荐使用 Fiddler 工具来抓包,Fiddler 自行去下载。
划重点:请确保电脑和手机连接在同一局域网的同一个 WiFi,别又说怎么抓不到包
1.查询电脑当前 IP
Win + R (快捷键),打开【运行】窗口,然后输入 cmd 回车,弹窗命令窗口,紧接着输入:ipconfig
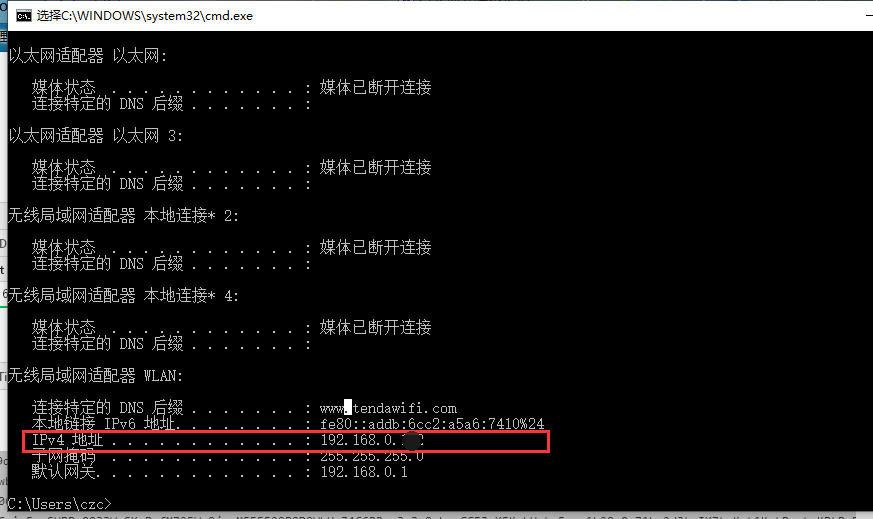
记着 ip,一会配置手机 WiFi,不会配置的可以看 Fiddler 官网这篇文章: docs.telerik.com/fiddler/Con…
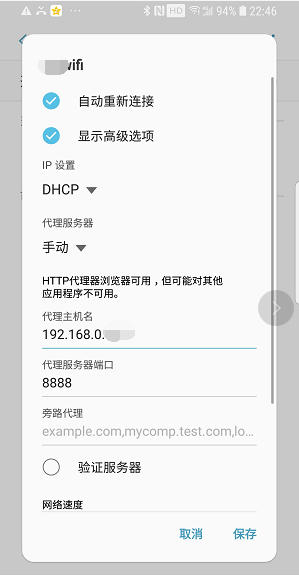
打开手机 WiFi 管理,显示 WiFi 的高级选项,设置代理服务器为手工,代理主机名为刚刚电脑 IPv4 地址:192.168.0.XXX ,代理服务器端口默认设置为:8888
2.手机安装 Fiddler 证书
因为微信的网络请求为 HTTPS ,安全性高,所以 Fiddler 需要在手机端安装它的信任证书,才能抓到微信的请求( 比喻:Fiddler 充当代理人、中间商,在建立 https 的过程搞事情,瞒天过海,以获取信任 )。
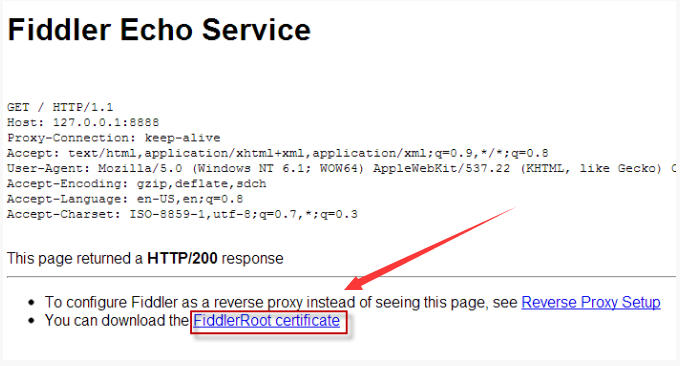
操作如下:
- 手机浏览器打开:ipv4.fiddler:8888/
- 下载证书
FiddlerRoot Certificate - 手机安装这个证书,安装过程可能需要设置屏幕密码
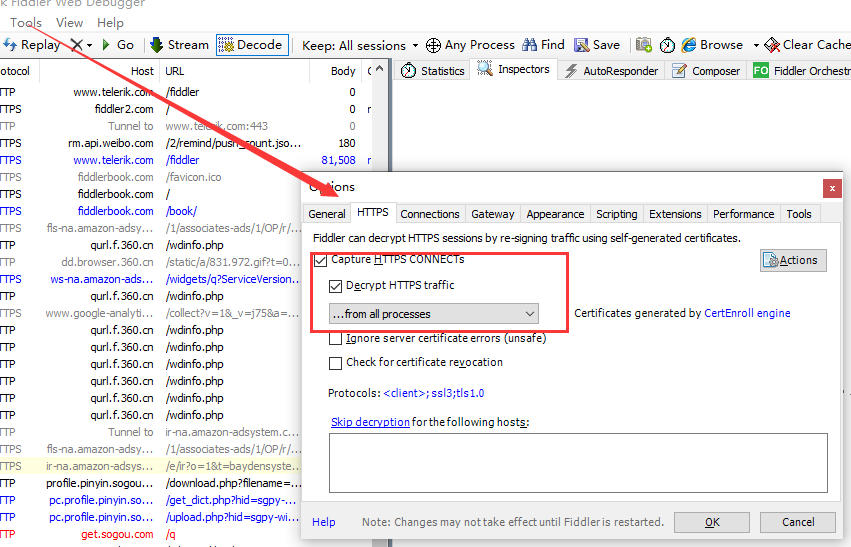
- 打开 【Fiddler】-【Tools】-【HTTPS】,勾选
Capture HTTPS traffic
二、爬虫
配置好抓包工具之后,打开某公众号,切换历史文章消息,然后点击更多消息,此时观察 Fiddler 抓包情况。
每次抓包前,建议先清空历史抓包数据,然后在执行操作,这样方便定位链接。
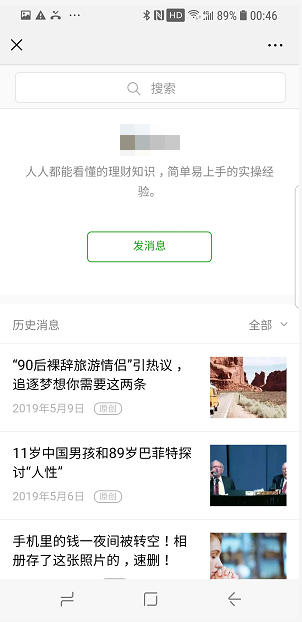
于是我们可以很轻易的拿到微信公众号获取文章接口地址:
mp.weixin.qq.com/mp/profile_…
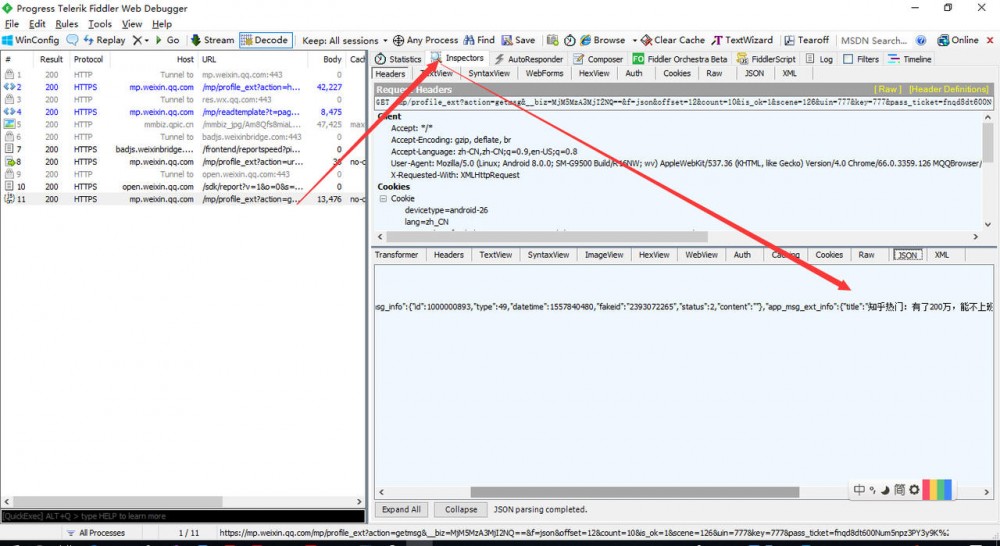
切换到 WebForms 选项卡,可以看到 Get 请求下的参数信息,后面我们模拟请求,照着写就 ok 了( Get 请求参数,可以写在链接里面)
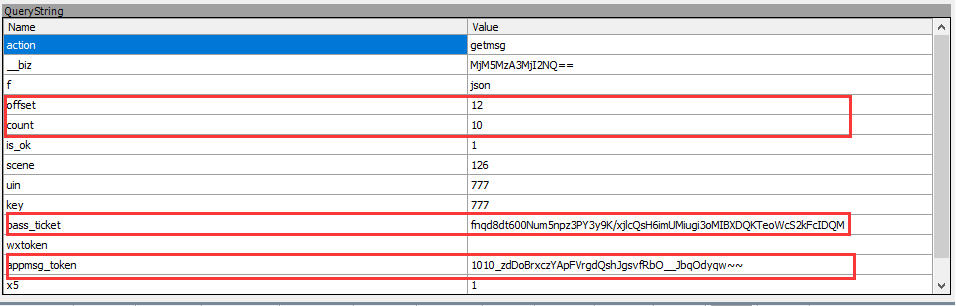
在上面这个图,我框了几个重要参数的,这几个参数涉及到微信服务端的校验相关操作,所以在复制的时候,记得不要搞错了,否则会提示 session 错误。
我个人试错发现,每次爬一个新的公众号,只需对应修改这 4 个参数即可: __biz、appmsg_token、pass_ticket、wap_sid2
如何爬取所有文章呢?做过手机客户端的童鞋,应该知道我们用 Recyclerview 或 ListView 做 下拉刷新或者上拉加载更多 的时候,接口一般需要配置 nextpage 的参数吧,对应微信文章接口就是: offset 参数(理解为偏移量), count 参数(理解为每次加载的数目)。
举例:我设置 offset 为0, count 为 10,那么第一页数据就加载10条,那第二页的起始点就应该是 offset = 10 , count 不作修改依旧为 10。希望大家能理解我的例子,相信这个不难
1.构建请求,递归调用
请求这东西,当然是 okhttp 来啦,引用相关 jar 包或者 gradle 依赖。说明一下:User-Agent 使用 Fiddler 抓取的值,以模拟手机客户端的请求。核心代码如下:
String url = "https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=%s&f=json&offset=%d&count=10&is_ok=1&scene=126&uin=777&key=777&pass_ticket=%s&wxtoken=&appmsg_token=%s&f=json ";
url = String.format(url, MyClass.__biz, startIndex, MyClass.pass_ticket, MyClass.appmsg_token);
// System.out.println(url);
String cookie = "rewardsn=; wxtokenkey=777; wxuin=777750088; devicetype=android-26; version=2700033c; lang=zh_CN; pass_ticket=%s; wap_sid2=%s";
cookie = String.format(cookie, MyClass.pass_ticket, MyClass.wap_sid2);
Request request = new Request.Builder()
.url(url)
.get()
.addHeader("Host", "mp.weixin.qq.com")
.addHeader("Connection", "keep-alive")
.addHeader("User-Agent", "Mozilla/5.0 (Linux; Android 8.0.0; SM-G9500 Build/R16NW; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/66.0.3359.126 MQQBrowser/6.2 TBS/044704 Mobile Safari/537.36 MMWEBID/8994 MicroMessenger/7.0.3.1400(0x2700033C) Process/toolsmp NetType/WIFI Language/zh_CN")
.addHeader("Accept-Language", "zh-CN,zh-CN;q=0.9,en-US;q=0.8")
.addHeader("X-Requested-With", "XMLHttpRequest")
.addHeader("Cookie", cookie)
.addHeader("Accept", "*/*")
.build();
Response response = okHttpClient.newCall(request).execute();
if (response.isSuccessful()) {
String body = response.body().string();
JSONObject jo = new JSONObject(body);
if (jo.getInt("ret") == 0) {
currentTimes++;
System.out.println("当前是第" + currentTimes + "次");
String general_msg_list = jo.getString("general_msg_list");
general_msg_list = general_msg_list.replace("///", "/");
// json 解析
JSONObject jo2 = new JSONObject(general_msg_list);
JSONArray msgList = jo2.getJSONArray("list");
for (int i = 0; i < msgList.length(); i++) {
JSONObject j = msgList.getJSONObject(i);
JSONObject msgInfo = j.getJSONObject("comm_msg_info");
long datetime = msgInfo.getLong("datetime");
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd");
String date = sdf.format(new Date(datetime * 1000));
if (j.has("app_msg_ext_info")) {
JSONObject app_msg_ext_info = j.getJSONObject("app_msg_ext_info");
JSONArray multi_app_msg_item_list = app_msg_ext_info.getJSONArray("multi_app_msg_item_list");
if (multi_app_msg_item_list.length() > 0) {
//多图文 do nothing
} else {
String content_url = app_msg_ext_info.getString("content_url");
String title = app_msg_ext_info.getString("title");
int copyright_stat = app_msg_ext_info.getInt("copyright_stat");
String record = date + "-@@-" + title + "-@@-" + content_url;
System.out.println(record);
datas.add(record);
}
} else {
System.out.println("非图文推送");
}
}
// can_msg_continue 来判断是否还有下一页数据
if (jo.getInt("can_msg_continue") == 1) {
Thread.sleep(1000);
startIndex = jo.getInt("next_offset");
execute();
} else {
System.out.println("爬取完成!");
// 完成之后,保存结果
saveToFile();
}
} else {
System.out.println("无法获取文章,参数错误");
}
}
复制代码
2.保存文章信息
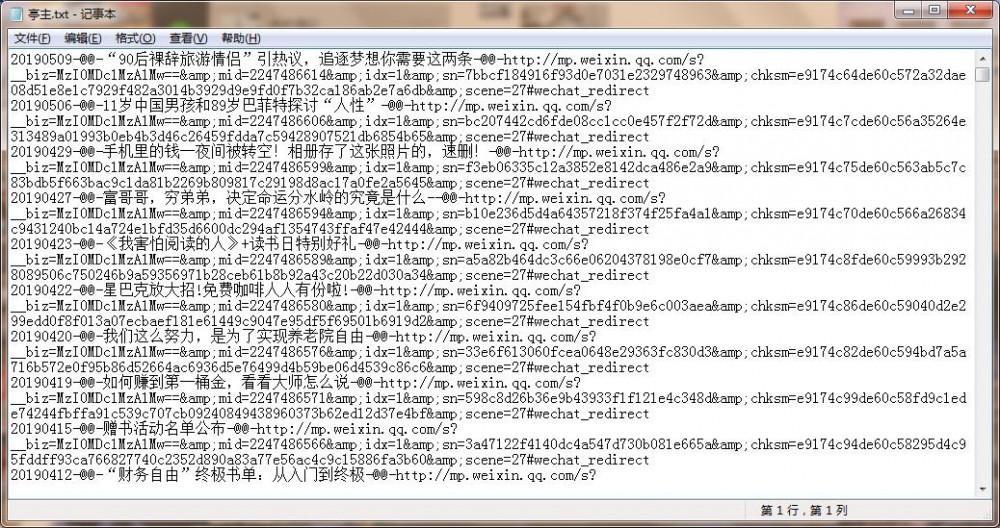
好像代码也不是特别多,哈哈,然后把爬取的数据保存到一个 txt 文本文件里面,我这边用的格式是: 时间-@@-标题-@@-链接 ( 后面方便使用“-@@-”分割字符串 ),当然你也可以连接 Mysql,来存储信息,我就偷懒了,没搞了。
三、Html 转 Pdf
既然拿到每一篇文章的 Url 了,那保存成 Html 不是很 easy 的事情吗,但是如何将 html convert Pdf 呢?
1.wkhtmltopdf 工具
1.1下载 wkhtmltopdf 并安装
传送门:wkhtmltopdf.org/,注意:系统版本的选择,我这边是 Windows 系统
1.2配置环境变量
如果你没有配置系统环境变量的话,就需要到 wkhtmltopdf 的安装目录下的 bin 文件夹下面,去执行命令
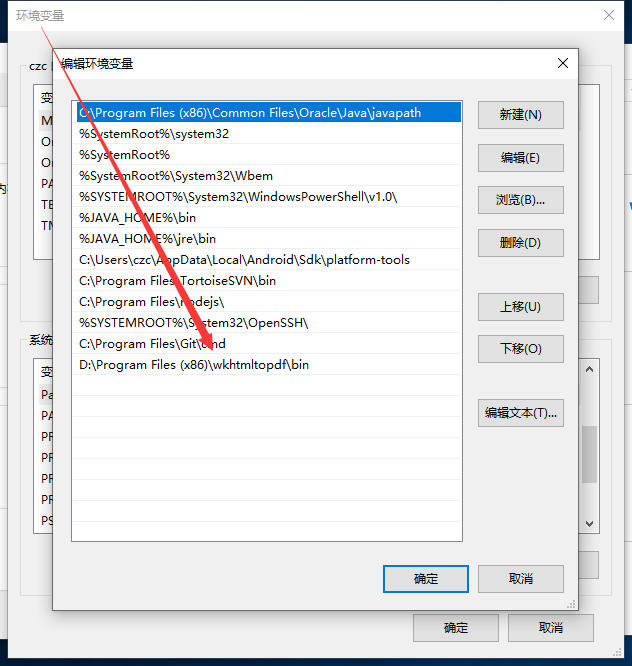
1.3如何使用
例如:你想把 Google 网页转成 pdf
wkhtmltopdf http://google.com google.pdf 复制代码
2.解决 wkhtmltopdf 保存图片丢失问题
通过 wkhtmltopdf 保存 pdf 的时候,存在网络图片丢失的问题,也就是不显示图片,那如何解决这个问题呢? 通过替换 html 中,img 标签的 data-src 和 src 的属性值,由 http 链接改为本地路径即可 。
思路:请求文章 url ,获取 html 信息,通过 jsoup 解析 html,然后通过选择器选择 img 标签,接着获取 img 的 data-src 的属性值(图片地址),然后遍历下载图片到本地,下载图片成功之后,通过 jsoup 提供的方法,修改该 img 的 data-src 的属性值,替换原先的 html 信息。核心代码如下:
Jsoup介绍:html解析神器
Request request = new Request.Builder().url(url).get().build();
Response response = okHttpClient.newCall(request).execute();
if (response.isSuccessful()) {
String html = response.body().string();
// System.out.println(html);
Document doc = Jsoup.parse(html);
//找到图片标签
Elements img = doc.select("img");
for (int i = 0; i < img.size(); i++) {
// 图片地址
String imgUrl = img.get(i).attr("data-src");
if (imgUrl != null && !imgUrl.equals("")) {
Request request2 = new Request.Builder()
.url(imgUrl)
.get()
.build();
Response execute = okHttpClient.newCall(request2).execute();
if (execute.isSuccessful()) {
String imgPath = imgDir + MD5Utils.MD5Encode(imgUrl, "") + ".png";
File imgFile = new File(imgPath);
if (!imgFile.exists()) {
// 下载图片
InputStream in = execute.body().byteStream();
FileOutputStream ot = new FileOutputStream(new File(imgPath));
BufferedOutputStream bos = new BufferedOutputStream(ot);
byte[] buf = new byte[8 * 1024];
int b;
while ((b = in.read(buf, 0, buf.length)) != -1) {
bos.write(buf, 0, b);
bos.flush();
}
bos.close();
ot.close();
in.close();
}
//重新赋值为本地路径
img.get(i).attr("data-src", imgPath);
img.get(i).attr("src", imgPath);
//导出 html
html = doc.outerHtml();
}
execute.close();
}
}
String htmlPath = dirPath + fileName + ".html";
final File f = new File(htmlPath);
if (!f.exists()) {
Writer writer = new FileWriter(f);
BufferedWriter bw = new BufferedWriter(writer);
bw.write(html);
bw.close();
writer.close();
}
// 转换
HtmlToPdf.convert(htmlPath, destPath);
// 删除html文件
if (f.exists()) {
f.delete();
}
response.close();
}
复制代码
3.转换成 PDF
/**
* html转pdf
*/
public static boolean convert(String srcPath, String destPath) {
StringBuilder cmd = new StringBuilder();
cmd.append("wkhtmltopdf");
cmd.append(" ");
cmd.append("--enable-plugins");
cmd.append(" ");
cmd.append("--enable-forms");
cmd.append(" ");
cmd.append(" /"");
cmd.append(srcPath);
cmd.append("/" ");
cmd.append(" ");
cmd.append(destPath);
System.out.println(cmd.toString());
boolean result = true;
try {
Process proc = Runtime.getRuntime().exec(cmd.toString());
HtmlToPdfInterceptor error = new HtmlToPdfInterceptor(proc.getErrorStream());
HtmlToPdfInterceptor output = new HtmlToPdfInterceptor(proc.getInputStream());
error.start();
output.start();
proc.waitFor();
} catch (Exception e) {
result = false;
e.printStackTrace();
}
return result;
}
复制代码
获取终端输入输出信息,上面代码的 HtmlToPdfInterceptor
public class HtmlToPdfInterceptor extends Thread {
private InputStream is;
public HtmlToPdfInterceptor(InputStream is) {
this.is = is;
}
@Override
public void run() {
try {
InputStreamReader isr = new InputStreamReader(is, "utf-8");
BufferedReader br = new BufferedReader(isr);
String line = null;
while ((line = br.readLine()) != null) {
System.out.println(line.toString()); //输出内容
}
} catch (IOException e) {
e.printStackTrace();
}
}
复制代码
wkhtmltopdf 的转换过程速度比较慢,建议开多个线程搞,我是 5 个线程去转换,最后看一下成果图(python 党别喷代码量哈,求放过~)
小结
感谢您的阅读,如有不对的地方,还请指出修正!文中不理解的地方,可加 qq 交流:1029226002。
正文到此结束
- 本文标签: final 删除 Action id linux windows 线程 数据 App HTML文件 参数 http 微信公众号 服务端 递归 cmd tar UI Apple Document 主机 下载 希望 stream 服务器 配置 时间 parse Chrome DDL 神器 MQ Agent root js 安装 代码 遍历 list src 微信文章 IO equals web https sql Google 解析 key client 文章 图片 session java ip 安全 Netty jsoup XML build python plugin token 目录 db 标题 管理 Android json Connection ACE ORM Keep-Alive mysql 端口 cat IDE HTML Select
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

