基于Java的同花顺股票数据爬虫
问题来源
- 今天与同学聊天,得知他有个任务是抓取同花顺网站上的股票数据,有点兴趣,便做了相关实验。
介绍
- 网站地址: http://q.10jqka.com.cn/
- 网站界面:
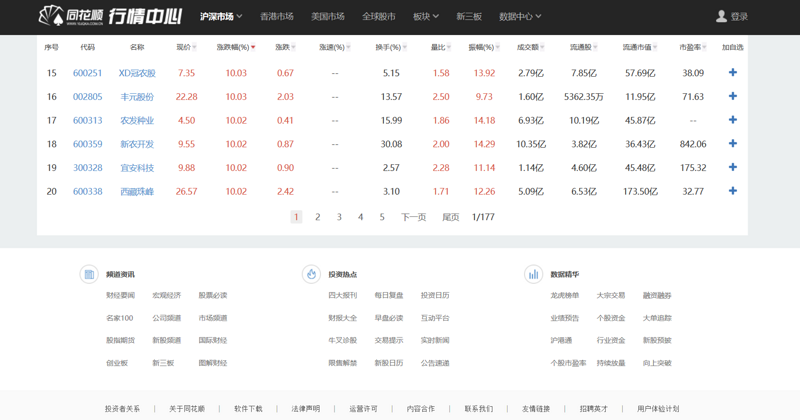
- 爬取内容:图中全部股票专栏表格中的数据
观察
- 浏览器:Firefox
- 观察现象:网页中每次只展示一页的数据,一页20条数据。通常来说,为了减轻浏览器的存储压力,后台服务器一般只给前台发送一页的数据,数据的获取需要前端发送请求
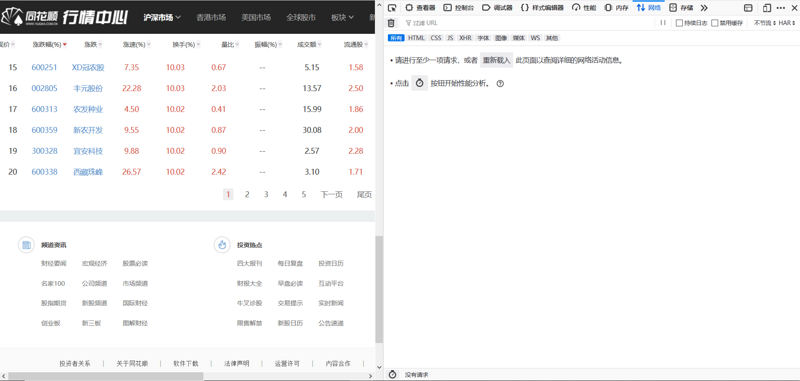
- 寻找请求:为了获取某一页数据对应的请求,点击F12键,调出浏览器工具控制台,并点击到网络专栏,同时清空界面中的所有请求,页面如下:
- 点击页,发现请求,该请求方法为GET,返回类型为html,界面如下:
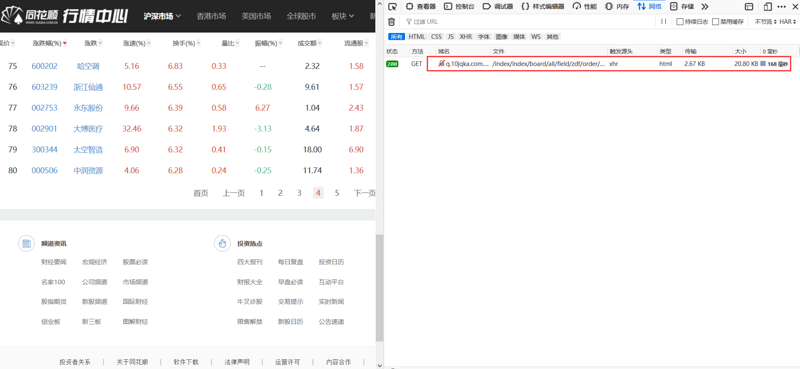
- 探索请求:发现该请求的返回类型为html,为了进一步探索该请求,将该请求的地址复制到浏览器地址栏中,打开页面,发现这与主网站上的数据一致,可认为该请求可获取到股票数据。
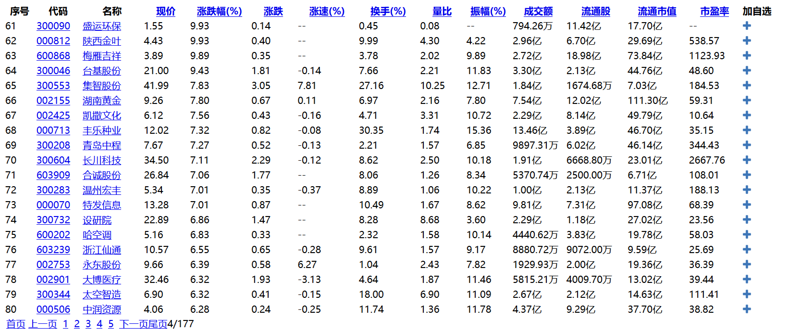
- 寻找关系:通常来说,某一页与请求的地址会有特定的联系。刚刚我们请求的地址为: http://q.10jqka.com.cn/index/... ,发现其中的4正好为我们所点击的页数,这个时候页数和请求地址的规律寻找出来了
实验
- 语言:Java
- 工具:htmlunit,
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.35.0</version>
</dependency>
- 基本思想:浏览器模拟点击
- 源码如下:
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.net.URL;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.HttpMethod;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.WebRequest;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.html.HtmlButton;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlPasswordInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class HtmlUtil {
WebClient webClient;
//初始化
public HtmlUtil(){
webClient = new WebClient(BrowserVersion.CHROME);//新建一个模拟谷歌Chrome浏览器的浏览器客户端对象
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常, 这里选择不需要
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常, 这里选择不需要
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);//是否启用CSS, 因为不需要展现页面, 所以不需要启用
webClient.getOptions().setJavaScriptEnabled(true); //很重要,启用JS。有些网站要开启!
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//很重要,设置支持AJAX
webClient.getOptions().setTimeout(30000);
}
//获取某个url的web客户端
public String htmlUnitUrl(String url, WebClient webClient) {
try {
WebRequest request = new WebRequest(new URL(url), HttpMethod.GET);
Map<String, String> additionalHeaders = new HashMap<String, String>();
additionalHeaders
.put("User-Agent",
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36");
additionalHeaders.put("Accept-Language", "zh-CN,zh;q=0.8");
additionalHeaders.put("Accept", "*/*");
request.setAdditionalHeaders(additionalHeaders);
// 获取某网站页面
Page page = webClient.getPage(request);
return page.getWebResponse().getContentAsString();
} catch (Exception e) {
}
return null;
}
//爬取某网页
public void work(String url) {
try {
HtmlPage page = webClient.getPage(url);//打开网页
int pageCount = 177;
for(int i=1;i<=pageCount;i++) {
//当访问速度过快时,后台浏览器会禁止,在这里可加入适当延迟的代码
/**
*延迟执行的代码
*/
String content = htmlUnitUrl("http://q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/"+i+"/ajax/1/",webClient);
if(content.contains("Nginx forbidden."))
return;
else {
writeFile("F://测试//"+i+".html",content);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args){
HtmlUtil demo=new HtmlUtil();
String url = "http://q.10jqka.com.cn/";
demo.work(url);
}
/**
* 保存抓取的html到本地
* @param path
* @param content
*/
public static boolean writeFile(String path,String content) {
File file = new File(path);
boolean isSuccess = true;
System.out.println(path);
// if file doesnt exists, then create it
if (!file.exists()) {
try {
isSuccess = file.createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
isSuccess = false;
}
}else {
file.delete();
}
FileWriter fw;
try {
fw = new FileWriter(file.getAbsoluteFile());
BufferedWriter bw = new BufferedWriter(fw);
bw.write(content);
bw.close();
System.out.println("写入成功.");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println("写入失败.");
isSuccess = false;
}
return isSuccess;
}
}
总结
- 因为心存兴趣,便做了相关的实验,为了方便,其中的部分代码还借鉴了网上的源码。由于时间关系,以上代码只是把数据所在的网页抓取到本地,没有进行解析。
- 大家晚安~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

