一起阅读HashMap(jdk1.7)源码
废话不多说,直接进入主题:
首先我们从构造方法开始:
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 初始化加载因子(默认0.75f)
this.loadFactor = loadFactor;
// 初始化容器大小(默认16)
threshold = initialCapacity;
init();
}
// 可以看到jdk1.7中hashMap的init方法并没有创建hashMap的数组和Entry,
// 而是移到了put方法里,后边会讲到
void init() {
}
最常用的 put 方法:
public V put(K key, V value) {
// 可以看到,初始化table是在首次put时开始的
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 对key为`null`的处理,进入到方法里可以看到直接将其hash置为0,并插入到了数组下标为0的位置
if (key == null)
return putForNullKey(value);
// 计算hash值
int hash = hash(key);
// 根据hash,查找到数组对应的下标
int i = indexFor(hash, table.length);
// 遍历数组第i个位置的链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 找到相同的key,并覆盖其value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 在table[i]下的链表中没有找到相同的key,将entry加入到此链表
// addEntry方法后边会再看一下
addEntry(hash, key, value, i);
return null;
}
根据 put 方法的流程,我们进入到 inflateTable 方法看一下他的初始化代码:
// 容量一定为2的n次方,比如设置size=10,则容量则为大于10的且为2的n次方=16
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
// 计算扩容临界值:capacity * loadFactor,当size>=threshold时,触发扩容
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 初始化Entry数组
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
addEntry 添加链表节点
能进入到 addEntry 方法,说明根据hash值计算出的数组下标冲突,但是key不一样
void addEntry(int hash, K key, V value, int bucketIndex) {
// 当数组的size >= 扩容阈值,触发扩容,size大小会在createEnty和removeEntry的时候改变
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容到2倍大小,后边会跟进这个方法
resize(2 * table.length);
// 扩容后重新计算hash和index
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 创建一个新的链表节点,点进去可以了解到是将新节点添加到了链表的头部
createEntry(hash, key, value, bucketIndex);
}
resize 扩容
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 创建2倍大小的新数组
Entry[] newTable = new Entry[newCapacity];
// 将旧数组的链表转移到新数组,就是这个方法导致的hashMap不安全,等下我们进去看一眼
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
// 重新计算扩容阈值(容量*加载因子)
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
get 方法
对于put方法,get方法就很简单了
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
// 根据hash值找到对应的数组下标,并遍历其E
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
不安全的 transfer 方法
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 遍历旧数组
for (Entry<K,V> e : table) {
// 遍历链表
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 计算节点在新数组中的下标
int i = indexFor(e.hash, newCapacity);
// 将旧节点插入到新节点的头部
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这里粗略的讲一下为什么 transfer 是不安全的
- 从上面的代码可以看出,从oldTable中遍历Entry是正序的,也就是
a->b->c的顺序,而插入到新数组的时候是采用的头插法,也就是后插入的在首部,所以遍历之后结果为c->b->a; - 此时正常逻辑是没有问题的,而当有多个线程同时进行扩容操作时就出现问题了,看下边的图
此时的状态为a线程创建了新数组,b线程也创建了新数组,同时b的cpu时间片用完进入等待阶段,
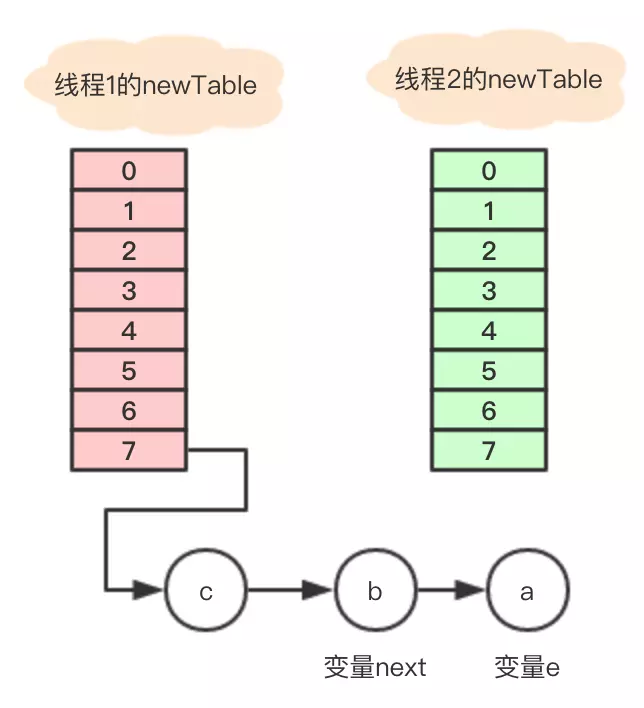
此时的状态为a线程完成了数组的扩容,退出了 transfer 方法,但是还没有执行下一句 table = newTable;
b线程回来继续执行代码
Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next;
结果如下:
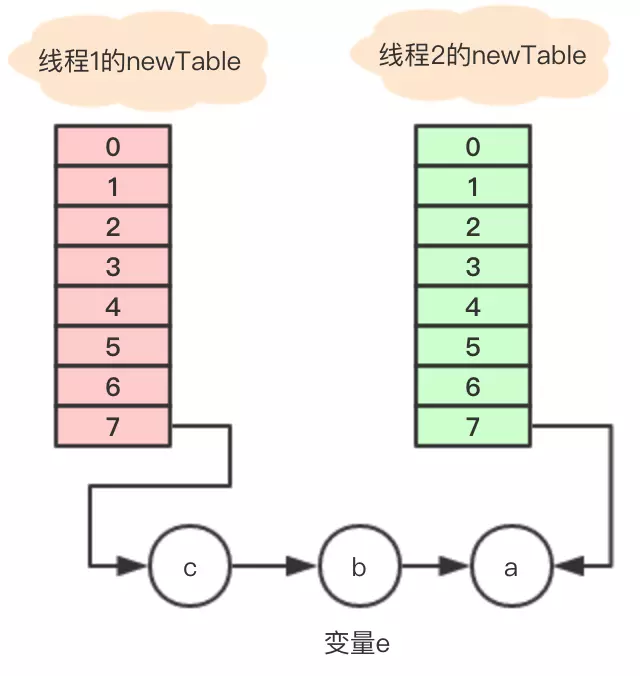
b会继续执行循环代码,进入到死循环状态。
关于 transfer 不安全的问题,感兴趣的可以去看一下这篇文章 老生常谈,HashMap的死循环 。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

