关于偏向锁,安全点,JIT的一些暗坑.
前言
本文是一篇简短的杂糅.
本文源自于作者最近的一个疑问:为什么在旧版的jdk中偏向锁的移除一定要在全局安全点进行?同时在上个星期,作者参与的一个项目发生了一件怪事:一个服务莫名其妙地不接受任何请求了,一切请求都是timeout,而查看日志,发现出故障的服务本身去请求另一个服务,请求与响应在几十毫秒完成,却原地停顿四十余秒,最后报出超时异常.
作者在调研这两个问题期间搜索了大量以"偏向锁"和"安全点"为关键词的介绍,尽管最终也没能找出准确的答案,但是在调研过程中还是有所得,值得记录一个短篇了.
偏向锁的疑问
首先是偏向锁的移除:
我们知道,从java6开始,自带的synchronized锁进行了大量的优化,有一个膨胀的过程,从无锁-偏向锁-轻量锁-重量锁依次膨胀,第一次加锁时,允许线程将该监视器偏向自己,直到发生其他线程争抢(偏向锁持有线程在退出同步块时不移除偏向,此种情况可以重偏向),此时偏向锁被移除,并膨胀为轻量锁.
这个过程可以简单理解为其他线程请求锁,虚拟机要所有线程在最近的安全点阻塞,vm线程伪造一个displaced mark word到持有者线程的栈桢,更改监视器的标记位,然后让所有线程继续执行.此时持有锁的线程会因此自视为轻量锁,竞争者也将按照轻量锁的规则去竞争.
作者查看了大量的贴子和资料,哪怕是在官方的文章中,甚至一些贴了官方原码的注释中,也只有大概这样的描述:偏向锁的移除需要在全局安全点执行,就是不解释为什么.
也许就没有为什么吧,单纯是官方的实现问题,在前面的文章"54个JAVA官方文档术语"和"JAVA9-12"中曾简单提过,从JAVA10起出现了一个新的功能"线程局部握手",它能帮助我们做若干事情,其中一件就是由vm线程和java线程在单独线程的安全点移除偏向锁,而不需要等待全局安全点,同时在握手期间,会阻止进入全局安全点.经过这么久的资料查找,作者看来在java10之前必须全局安全点才能移除偏向锁这件事本身就似乎没有为什么,只是从前就这样设计的.
偏向锁的存在意义:
我们知道,偏向锁的目标是减少昂贵的原子指令cas等的使用以及互斥量的开销;轻量锁的目标是减少互斥量的开销.偏向锁在不考虑重偏向这种情况下,似乎只有第一次加锁才起作用,那么这个问题似乎有些多余,我们会对没有竞争的代码加上同步吗?
答案是会的.大体有以下场景:
1.类加载其实是加锁的,我们可以尝试并发地进行类加载,尽管大多情况下这由main线程完成.
2.一些旧版本的库,如使用Vector,使用HashTable,使用Collections.synchronize系列,在绝对不会出现线程逃逸的情况下使用StringBuffer拼接字符串,单线程使用了某些库中加了同步的代码等.
3.默认的情况下在jvm启动的前几秒偏向锁是不可用的,可以使用-XX:BiasedLockingStartupDelay=0进行配置.
以上情况可参考问题: 偏向锁的设计 .
偏向锁的设计疑问,为什么只在对象头中保存线程id?
可以参考: 偏向锁与轻量锁的设计不同 .
偏向锁退出同步块其实是无操作的,偏向锁标记依旧存在,所以自然恢复,规避了昂贵的原子指令和屏障的开销,但是轻量锁就不同了,需要在设置标记时保存锁记录的指针,同时还要将原来的信息存放到栈桢.这样在释放时,可以使用cas恢复原值.
Unlocked:
[ orig_header | 001 ] | Stack frame |
| |
Locked: | |
[ stack_ptr | 000 ] | |
| |-------------|
--------------------->| orig_header |
|-------------|
| |
| |
-------------
重偏向问题:
偏向锁的设计初衷是同一个线程一次或若干次往复地对同一个或几个监视器加锁,显然只有首次需要一个原子指令.而jvm足够地聪明,它会发现当前是否为值得偏向的无竞态同步.
偏向锁可以重偏向的一点细节:
1.HotSpot虚拟机仅支持"粗放"的重偏向(bulk rebias),用以在承受单队列重偏向过程的开销同时保留优化的收益.
2.粗放的偏向锁重偏向和移除这两件事共享了同一个安全点操作名:RevokeBias.
3.如果满足这几个条件:偏向锁撤消次数超过了BiasedLockingBulkRebiasThreshold并且小于BiasedLockingBulkRevokeThresholdand,且最后一次撤消偏向不晚于BiasedLockingDecayTime,且所有逃逸的变量都限定于jvm的属性,则后续的偏向锁粗放重偏向是可用的.
4.使用-XX:+PrintSafepointStatistics可打印安全点事件,与偏向锁有关的可重点可关注EnableBiasedLocking,RevokeBias和BulkRevokeBias.选项-XX:+TraceBiasedLocking可以帮助生成一个详细描述jvm做出的偏向锁决策的日志.
参考: 单个偏向锁的重偏向 .
安全点和JIT
关于安全点和JIT本身此处不再缀述,此处简单回忆若干前提.
JIT有client和server模式,其中server模式是高度优化的,甚至于可以用"过度优化"来形容,在"54个java官方文档术语"这篇文章中甚至提过一个"不常见的陷阱",发生时会反优化并退回解释执行.
JIT高度编译优化的代码和字节码解释执行不同,可能会进行一些安全点的消除,并且编译代码要在全局安全点进行一次"栈上替换"(OSR),然后才能生效.
参考: 循环的线程奇怪地阻塞了其他线程?
老外写的一个代码例子,非常像我们项目碰到的停顿现象,我们的代码也类似,确实有大量的同步操作(必然涉及偏向锁和移除,同时也涉及到JIT的栈上替换和计数大循环):
//代码
public class TestBlockingThread {
private static final Logger LOGGER = LoggerFactory.getLogger(TestBlockingThread.class);
public static final void main(String[] args) throws InterruptedException {
Runnable task = () -> {
int i = 0;
while (true) {
i++;
if (i != 0) {
boolean b = 1 % i == 0;
}
}
};
new Thread(new LogTimer()).start();
Thread.sleep(2000);
new Thread(task).start();
}
public static class LogTimer implements Runnable {
@Override
public void run() {
while (true) {
long start = System.currentTimeMillis();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// do nothing
}
LOGGER.info("timeElapsed={}", System.currentTimeMillis() - start);
}
}
}
}
//打印日志
[Thread-0] INFO c.m.c.concurrent.TestBlockingThread - timeElapsed=1004
[Thread-0] INFO c.m.c.concurrent.TestBlockingThread - timeElapsed=1003
[Thread-0] INFO c.m.c.concurrent.TestBlockingThread - timeElapsed=13331
[Thread-0] INFO c.m.c.concurrent.TestBlockingThread - timeElapsed=1006
[Thread-0] INFO c.m.c.concurrent.TestBlockingThread - timeElapsed=1003
[Thread-0] INFO c.m.c.concurrent.TestBlockingThread - timeElapsed=1004
[Thread-0] INFO c.m.c.concurrent.TestBlockingThread - timeElapsed=1004
显然中间那一个13秒多的等待时间就像我们项目中的40秒暂停一样突兀,这也一度让作者认为找对了答案.
该代码中,每行日志的打印预期应该是间隔一秒上下,可以看到除了13秒多的一次停顿以外,其他操作的差距都是3-6毫秒的级别.
为什么会发生这样的情况?
注意前面提到的前提,JIT编译的高度优化代码需要在全局安全点进行栈上替换,也就是说,它需要要求所有线程到最近的一个安全点阻塞.
正常情况下,每一个JAVA线程会轮询一个安全点标记(safepoint flag)来询问是否要进入安全点,当观察到去安全点标记(go to safepoint flag)时,会赶去最近的安全点.但是,大量地进行安全点标记的轮询是耗费性能的,因此C1C2编译器做了相应的优化,消除了过于频繁的安全点轮询,因此安全点轮询主要有以下几种情况:
1.使用解释器执行时任意两个字节码之间.
2.C1C2编译器生成的代码的非计数循环的"回边"(参考了深入理解java虚拟机的回边计数器,方法调用计数器的翻译).
3.在C1C2编译器的方法的退出(OpenJDK虚拟机)和进入(Zing),但当方法已经被内联时,编译器将移除这个安全点的轮询点.
注意示例代码的task线程,它进行的是一个计数的循环,因为计数的循环会让编译器认为是一个"有限"的循环,因此每个回边不会插入相应的安全点轮询.
故此,JIT在试图将编译优化的代码进行OSR时,其他线程已赶到安全点阻塞,但是task线程却依旧未能及时到达安全点,直到JIT最终放弃了等待并判定为无限循环为止.
解决方案:
1.增加选项-XX:+UseCountedLoopSafepoints ,可以看到问题立即消失了,但要注意,它会造成全局性能的永久下降,并可能造成jvm崩盘.加上这个选项后,编译器会在每轮循环回边进行安全点轮询,问题解决.
2.显式禁用某方法的编译:-XX:CompileCommand='exclude,binary/class/Name,methodName
3.手动增加安全点轮询,如在循环的结束处增加Thread.yield()或直接将计数器i改为long型(此时再回去翻doug大神的源码,一定要思考yield和long型计数器),这样循环会被编译器认为是非常大的一个(虽然还不是无限).
答主还对原作者的循环代码做出了一些修改,并解决了问题,而解决的原因就是利用了前面提过的"不常见的陷阱".
for (int i = OSR_value; i != 0; i++) {
if (1 % i == 0) {
uncommon_trap();
}
}
uncommon_trap();
明显的一个问题,语义无变化,循环依旧是无限的.只不过在i自增到偶数时,编译器将会遇到"不常见的陷阱",原本做出的极端优化将不得不退化为解释器执行,从而解决了安全点轮询过稀少的问题.
小结
许多技术单独来看都很好,偏向锁,JIT,安全点.单独看来都很完美,JIT的时间开销也相对较少,但是结合在OSR真的是一大暗坑.
且不管偏向锁为什么从前一定要在全局安全点移除了,作者后续会继续查资料,总之,从JAVA10开始不用了.关于偏向锁和OSR,建议阅读此 博客 .
作者看来,安全点的机制特别像java官方提供的同步器,如前面介绍过的CyclicBarrier,CountDownLatch,Semaphore,Phaser.一定要等待所有线程到达某个点,然后再进行一些操作,操作完毕后再释放线程继续执行.
关于安全点的三个术语:
安全点状态:java线程可以按相应的轮询机制轮询是否进入此状态,但一旦进入,就只能在安全点操作结束后才可离开了.
安全点轮询:java线程询问是否需要进入安全点状态的机制.
安全点操作:出于各种原因,但一定要等所有线程到达安全点才可以执行的操作.
最后上一张非常有代表性的图,出自 安全点 有关的一个博客.
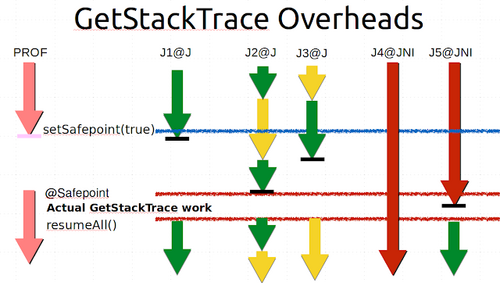
简单介绍这个图表的含义,它描述了安全点操作的若干开销.
1.到达安全点的时间(Time to Safe Point 简写TTSP):每个要进入安全点的线程都能在命中安全点轮询的情况下进入,但到达一个安全点轮询所需执行的指令数是未知的,从图上可以看到J1线程命中了一个安全点轮询并挂起.J2和J3发生了对cpu时间的竞态,J3提前获取了cpu资源并使得J2压入了运行队列,但J2此时并不在安全点.J3到达了安全点并挂起,释放了cpu资源,J2于是继续执行并最终进行了安全点轮询.J4和J5因为执行JNI代码而早已处于安全点,它们在此处不受影响.但J5在安全点期间尝试半路从JNI代码回来而被挂起.所以我们可以看到,不同的线程到达安全点的时间变化很大,早到达的线程会停顿较长时间.
b.安全点操作的开销:这取决于操作的类型,获取栈迹(GetStackTrace)将取决于栈的深度,如果采样了所有的线程或过多的线程(如在JAVA9-12一文中介绍过的新工具JVMTI::GetAllStackTraces),则时间也严重取决于线程数量.如果时间充裕,jvm会借此机会执行一些其他安全点操作.
c.恢复被挂起的线程的开销.
上述问题分析的一些帮助:
a.过长的TTSP导致的停顿时间:这包含页错误,cpu过载,过长的计数循环等.
b.线程的关闭与启动的开销与线程总数有关,总数越高则开销越大,如果要计算总开销,可以粗略使用非0的挂起/恢复线程开销和TTSP乘以线程数量进行估算.
c.虚拟机参数-XX:+PrintGCApplicationStoppedTime可以列出所有的停顿时间和TTSP.
正文到此结束
- 本文标签: http java线程 代码 final 编译 ACE 安全 synchronized App ask https id IDE Semaphore 锁 java Word cat 字节码 CTO src tab Collection UI CyclicBarrier 参数 关键词 线程 JVM 注释 client 源码 IO 配置 并发 value 博客 tar HashTable 时间 同步 翻译 文章 map CountDownLatch Collections
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

