推荐系统:爱奇艺知识推荐系统架构
爱奇艺知识频道当前已经包含了2万精品课程,涵盖职场、文史、IT/互联网等多个分类,这么多课程怎么实现高效分发是一个大难题,通过搜索触达、人工运营位、IP导流等方式确实可以分发一批课程,然而这些课程普遍集中于头部热度课程,暴露在用户面前的仍然是冰山的顶部,大量的课程由于信息过载没有暴露的机会,挖掘长尾课程防止过度马太效应,推荐系统责任重大。
1、表现形式
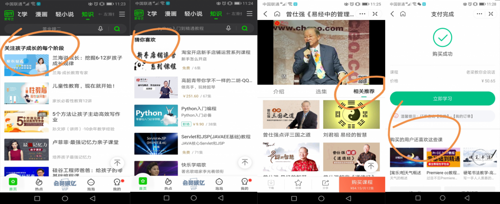
爱奇艺知识当前的推荐系统有如图几个表现形式:
- 个性化分群运营:根据画像做用户分群,按群推荐课程;
- 猜你喜欢:个性化课程推荐流;
- 相关推荐:课程页面内的相关推荐;
- 买了又买:购买成功页的课程推荐;
2、系统架构
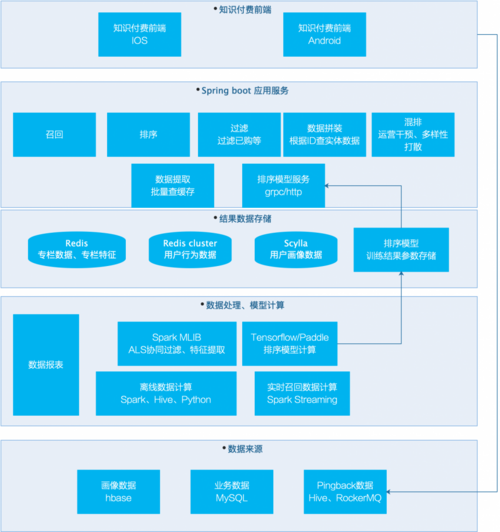
系统架构上图,主要流程如下:
- 数据处理:使用spark、hive、python,从mysql备库、hbase、pingback的hive表和实时流提取数据,实现关联、清洗、映射特征等处理,其中spark streaming从pingback的rockermq准实时提取用户行为,实现10秒钟用户个性化推荐列表的更新;
- 模型计算:使用spark als矩阵分解计算,结果可以给用户推荐协同过滤、以及根据item vectors实现相关推荐;使用tensorflow/paddle实现排序模型,使用LR/DNN/DEEP&WIDE实现CTR排序;
- 结果数据存储:这里涉及比较多的考虑,主要是从数据量、查询响应时间、数据结构支持度等方面考虑:
- 对于item本身实体数据、item相似度列表等数据,使用redis存储,因为redis cluster不能够批量读取,但是这里却需要批量读取;
- 对于用户行为实时数据,因为需要大数据量存储,并且需要丰富的数据结构支持,选用redis cluster;
- 对于用户画像数据、自己提取的用户标签数据,数据量大,只需要根据用户ID提取,所以选用scylla;
- 在线服务:主要是参考youtube的推荐系统架构,将整体步骤细分为召回、排序、过滤、混排等步骤,其中:
- 召回、排序、已购等步骤,都是id在参与计算,等最终返回的时候,才查询实体业务数据;
- 模型排序服务使用grpc/brpc/http提供服务给应用服务调用;
- 应用服务同时需要支持AB Test的分桶,以及参数的返回;
- 前端请求:前端只进行非常短暂的缓存(防止恶意请求),重要的是需要搞定pingback的埋点投递,投递中需要设定ab test的参数
以上就是爱奇艺知识的推荐系统架构,系统还处于快速迭代升级中,之后的事情有这些:
- 当前系统在QPS高峰是耗时150MS左右,时间耗费在实体数据拼装阶段,后续进行优化;
- 相关推荐的导流效果很好,后续进行多种实验进行效果对比;
- 排序模型的线上化,通过AB测试进行效果对比;
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

