JVM数据区域与垃圾收集<深入理解JVM读书笔记>
周志明老师所著的《深入了解JAVA虚拟机》(后文简称"书中")可谓是java工程师进阶的必读书籍了.最近读了书中的第一二部分,也就是前五章,有很多收获.因此想要写一篇文章.来用自己理解到的知识来总结一下前五章.
虽然说是总结,但是仍然强烈推荐大家去看原著.原著并没有"多出什么东西导致需要我进行总结",而是每个小节都让我有所收获.但是我并不能全部记住书中所写,只能按照自己的思路记录,串联起来.再次推荐一下大家阅读原著
自动内存管理机制
书中多次提到:
Java和C++之间有一堵由内存动态分配和垃圾收集所围成的高墙,墙外的人想进去,墙里的人想出来.
C/C++程序员对每一个对象的内存分配拥有绝对的控制权,但是这样就会很繁琐.Java程序员不用处理内存的分配,有JVM动态进行,在 出现内存泄漏的时候却比较难以排查.
根据所new的对象动态的进行内存分配,以及在合适的时间回收/释放掉不需要的对象,这就是JVM的自动内存管理机制.
运行时数据区域
JVM在执行java代码的时候,会将系统分配给他的内存划分为几个区域,来方便管理.比较经典的运行时数据区域图如下:
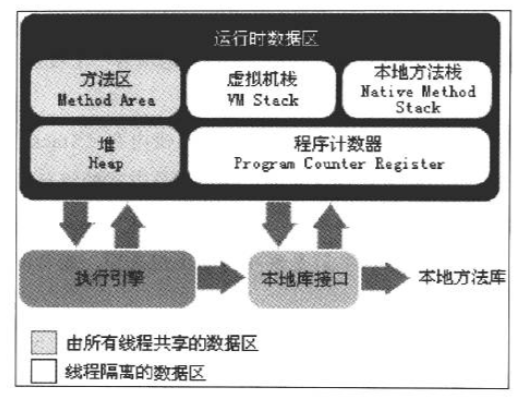
程序计数器:
程序计数器是一块比较小的线程独立的内存空间,它可以看成是当前线程执行的字节码的行号指示器.
虚拟机栈
虚拟机栈也是线程私有内存.每个方法在执行的时候都会创建一个"栈帧",里面存储了局部变量表,操作数栈,动态链接,方法出口等信息.可以理解为虚拟机栈存储了方法运行时需要的一些额外信息,一个"栈帧"的入栈出栈对应了一个方法的执行开始与结束.
本地方法栈
如果我们将上面的虚拟机栈理解为"为了java方法的执行而记录一些内容",那么本地方法栈就是为了Native方法二记录的.其他方面基本一致.虚拟机规范中对这一块的规定不严格,因此各个虚拟机的实现不同.著名的"HotSpot"把虚拟机栈和本地方法栈进行了合并.
堆
堆(Heap)是JVM内存中最大的一块,也是垃圾收集的主要工作区域.这块区域唯一的目的就是存放类的实例.堆中根据虚拟机的不同还有不同的区域划分,以便垃圾收集进行工作. 其中的详细区域划分在后面垃圾收集的地方会详细说明.
方法区
方法区也是一块线程共享区域,用于存储已经加载了的类信息,常量,静态变量,即时编译器编译后的代码等等.
他有一个更加响亮的名字"永久代", HotSpot 虚拟机将方法区实现成了永久代,来避免单独为方法区实现垃圾收集.这一举动的利弊不是我个小菜鸡可以分析的,但是我们要理解为什么叫做永久代?因为这一区域存放的内容,垃圾收集的效率是比较低的(常量,静态变量等较少需要被回收),所以当数据进入此区域,就好像永久存在了一下.
这一区域里面还有一个单独的区域,运行时常量池,当类加载后,各种字面量和符号引用会进入此区域. 在程序运行期间,也是可以将新的常量放入常量池的,比如 string.intern()
方法.
直接内存
直接内存并没有在上图的JVM运行时数据区域中体现,而是一块额外的内存区域.在JDK1.4中引入的NIO中,可以直接通过Native方法在堆外分配内存.这样可以提高性能.
这块区域的大小不受到给虚拟机分配的内存大小的限制,但是总归也是受到物理机的内存限制的,因此,当出现OutOfMemoryError,且代码中有大量使用到NIO的时候,可以考虑到是这一块内存产生了溢出.
内存分配
虚拟机上对象的创建过程
说到对象的创建过程,也许我们都会想到那个很经典的题目: 一个父类一个子类,几个静态方法几个普通方法,几个构造方法,问这些方法中的打印顺序.
但是不要误会,那些东西在现在并不重要了,需要机创建对象的过程要远比这复杂的多.简单概括如下:
- 当遇到new关键字的时候,首先检查常量池中是否可以找到,并且检查该类是否已经加载.如果没有,先加载类.
- 按照确定的大小去获取内存,获取的方法分为 指针碰撞 和 空闲列表 . 指针碰撞 :如果内存是整齐的,左边是使用过的,右边是空闲的,那么在分配空间的时候只需要移动一下指针即可. 空闲列表 :如果内存是不规整的,使用过的和未使用的相互交错,那么JVM必须维护一个列表来记录哪些空间是可用的. 具体使用哪种方法来分配内存取决于使用的垃圾收集器,因为有些垃圾收集器带有整理内存的功能.那么就可以使用指针碰撞了.
- 拿到分配的空间之后,要将内存全部初始化为零值.(不包括对象头)
- 虚拟机设置对象信息,比如对象属于的类的信息,类的元数据信息,哈希码.GC分代信息等.
- 现在才是执行构造方法,依次设置各个字段的值.
在第二步其实还有一个问题,那就是并发问题,如果只有一个指针指在 已经使用和未使用的内存 之间,那么在频繁的创建过程中,一定有并发问题.虚拟机解决这个问题的办法主要有两种:
- CAS加上失败重试机制.
- TLAB. 本地线程分配缓冲,每个线程先从堆中申请一小块内存,然后在这一块内存上进行分配,这样只需要在申请TLAB的时候才需要进行同步,增大了处理并发的能力.
创建的对象都包括了哪些信息?
在HotSpot中, 对象信息包括: 对象头,实例数据和对齐填充.
对象头: 对象头中包括两部分信息,对象的运行数据(hash码,GC年龄等),类型指针(指明它是哪个类的实例). 实例数据 : 这块的数据就是我们在代码中定义的那些字段等等. 对齐填充 : 这块数据并不是必然存在的,当对象实例数据不是8字节的整数倍的时候,用空白字符对齐一下.
对象内存的分配机制
对象内存分配其实与选择的垃圾收集器,虚拟机启动参数等有很大的关系,因此并不能确定的说:XXX在XXX上分配.但是总归是有一些普适性的规则的.
优先在Eden分配
大多数的情况下,对象首先在Eden区域分配,当Eden区域空间不足的时候,虚拟机将会进行一次Minor GC(新生代GC).
大对象直接进入老年代
大对象(虚拟机提供了参数:-XX:PretenureSizeThreshold来调整大对象的阈值)会直接分配在老年代.由于新生代使用复制的垃圾收集算法,如果将大对象分配到新生代,可能会造成在两个Survivor区域之间发生大量的内存复制.影响垃圾收集的效率.
长期存活的对象进入老年代
每个对象都有一个年龄的计数器,当对象在eden出生并且经过一次minor GC还在新生代的话,年龄就加1. 当年龄到了15(默认值)时,会晋升到老年代中.
动态的年龄判断
上面到达年龄之后晋升到老年代并不是唯一的规则, 当Survivor空间中的相同年龄的对象的总大小的综合大于Survivor空间的一半,虚拟机会认为这个年龄是一个更加合适的阈值,会将年龄大于或者等于这个值的对象全部移到老年代中去.
分配担保
当minor GC即将发生时,虚拟机会检查老年代是否可以作为此次的分配担保(老年代中的连续内存大于新生代中存活所有对象的总和),如果成立,那么说明可以作为担保,进行minorGC.
如果不成立,那就检查虚拟机设置里面HandlePromotionFailure是否允许进行冒险,如果允许的话,则进行minorGC,否则则进行FullGC. 如果冒险失败了,那就进行一次FullGC来在老年代腾出足够的空间.
垃圾收集
说起垃圾收集,我们总是可以零碎的说上一些,因为JVM的应用太广泛了,除了Java开发者还有许多其他基于JVM的开发者也需要了解这些. 但是我们有没有系统的整理过这里呢?
垃圾收集,即将无用的内存释放掉,以提供给后续的程序使用.那么就有三个问题:
- 对哪些内存进行回收?
- 什么时候进行回收?
- 怎么进行回收?
我们一个一个问题的来看.
对哪些内存进行回收?
当然是对死掉的,即 再也不会用到的对象 进行回收.
怎么判断一个对象再也不会被用到了呢?
引用计数法
首先就是引用计数法,它的思想是给每个对象设置一个计数器,每当有一个别的地方引用到了这个对象,计加器就加1.当其他地方释放掉对它的引用时,就减1.那么计数器等于0的对象,就是不可能再被引用的对象了.
这个算法其实还可以,实现简单,判断速度快,但是主流的JVM实现里面没有使用这个方法的,因为它有一个比较致命的问题,就是无法解决循环引用的问题.
当两个对象互相引用,除此之外没有其他引用的时候,他们应该被回收,但是此时他们的计数器都为1.导致他们没有办法被回收.
我们用以下代码进行一下测试:
public class ReferenceCountTest {
public static final byte[] MB1 = new byte[1024 * 1024];
public ReferenceCountTest reference;
public static void main(String[] args) {
ReferenceCountTest a = new ReferenceCountTest();
ReferenceCountTest b = new ReferenceCountTest();
a.reference = b;
b.reference = a;
a = null;
b = null;
System.gc();
}
}
复制代码
运行参数为: +XX:PrintGC
,输出结果 [GC (System.gc()) 7057K->2294K(125952K), 0.0024641 secs]
,可以看到,内存被回收掉了,说明我使用的HotSpot虚拟机使用的不是引用计数法来判断对象存活与否.
可达性算法
这个算法的基本思想就是,通过一系列的 GC ROOT 来作为起点,从这些节点开始沿着引用链进行搜索,当一个对象到 GCROOTS 没有任何的可达路径,就认为此对象是可被回收的.
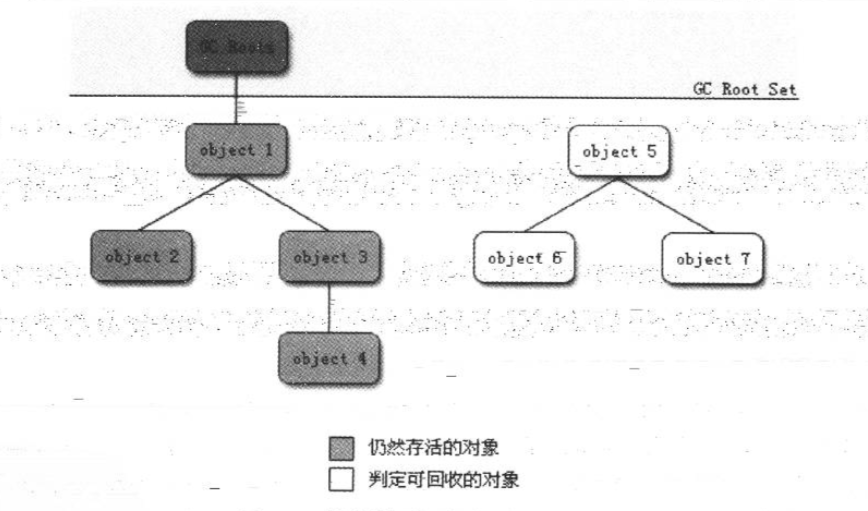
在上图中,object5,6,7虽然互相之间还有引用,但是由于从GCROOTS不可达,也是 死掉 的对象.
在Java中GCROOTS一般包括以下几种:
- 虚拟机栈中的栈帧中的本地变量表
- 常量引用
- 静态属性的引用
- 本地方法栈中Native方法的引用
什么时候进行回收?
这个问题其实比较复杂,且很多JVM的实现并不相同,我们粗略的以HotSpot为例说明一下.
首先我们要知道,垃圾收集是需要"Stop The World"的,因为如果整个JVM不暂停,那么就无法在某一瞬间确定哪些内存需要回收.就好像你妈妈给你打扫房间的时候会把你赶出去,因为如果你不断制造垃圾,是没有办法打扫干净的.
目前所有的JVM实现,在进行根节点的枚举(也就是确定哪些内存是需要回收的)这一步骤的时候都需要停顿,大家在做的只是尽可能的减少GC停顿来降低对系统的影响.
既然GC需要"Stop The World",但是一个运行中的先生并不是可以在随时随地停下来配合GC的.
所以当需要GC停顿的时候,需要给出一点时间,让所有线程运行到最近的"安全点"上.此外,为了解决在GC时有些线程处在挂起状态,安全点概念还有一个扩展的概念,安全区域,当线程进入到安全区域,就会挂起一个牌子,告诉别人在我摘下牌子之前,GC不用问我.而当线程想离开安全区域的时候,需要检查是否自己可以安全离开的标识.
怎么进行回收呢?
不同虚拟机的实现不一样,同一个虚拟机在堆上不同的区域执行的可能也不一样,不过总的来说,算法思想都是下面这几种.
标记清除
最基础的就是**标记-清除(Mark-Sweep)**了,该算法的过程和名字一样, 首先标记所有需要回收的对象,之后对他们统一进行回收.如下图所示.
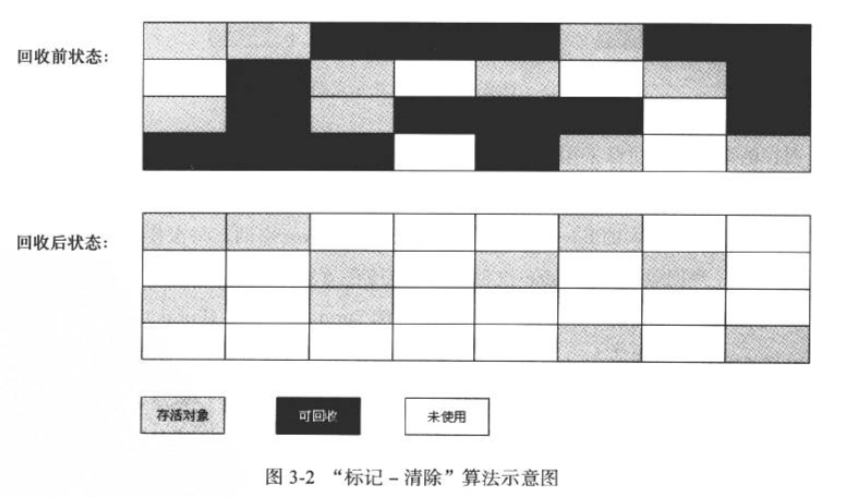
他的优点是: 思路简单且实现方便 缺点主要有两个:
1.效率不太高
2.在图中回收后的状态里,由于是直接的清除,所以可用内存不连续,全是碎片化的,这样当后续需要分配大对象而无法找到连续足够的空间,就会提前触发下一次GC
后续的算法主要就是对 标记-清除 算法的改进.
复制算法
为了解决上面的问题,出现了"复制"算法, 复制算法将内存分为容量相等的两块,每次只使用其中的一块,当用完了,将其中存活的对象copy到另外一块内存上,然后对已经使用的这一块内存进行整体的回收. 这样可以使得回收和分配时不用考虑碎片问题,效率极大的提升了,但是,代价是永远只能使用一半的内存,这个代价太过于高昂了.
复制算法的执行过程如下图:
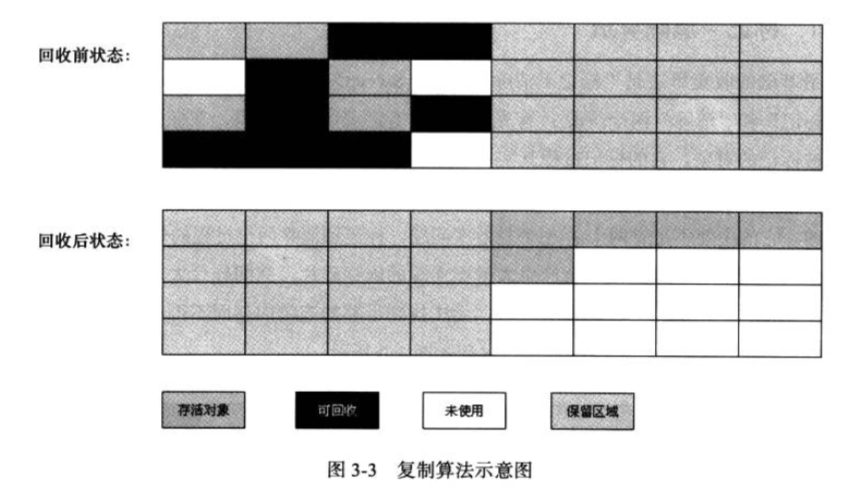
现代的商业虚拟机基本上都采用这个算法来回收新生代.因为新生代的垃圾回收比较的频繁,对于效率的要求更加高一些.
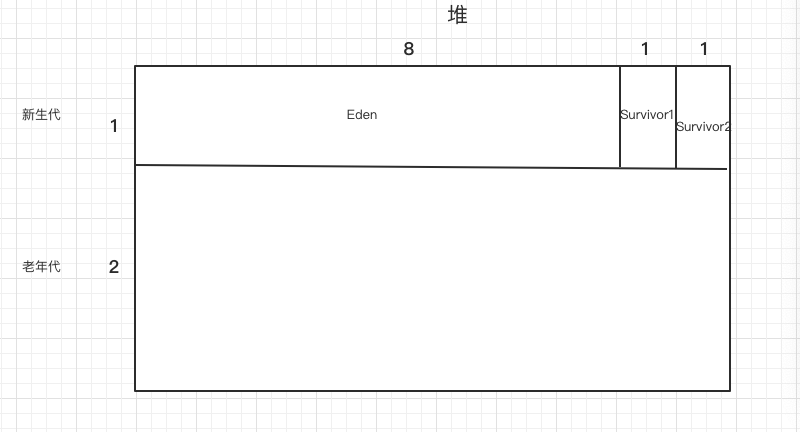
同时对复制算法进行了一些改良.经过统计,新生代的对象98%都是朝生夕死的,所以复制算法中的内存不需要按照1:1进行划分,而是划分为 Eden:Survivor1:Survivor2=8:1:1
(比例可调整)三块空间,每次使用Eden和一个 Survivor区域,当需要垃圾回收时,将其中存活的对象copy到另一个survivor中.然后对eden和已经使用survivor进行统一回收.这样相比于普通的复制算法,每次可以使用到90%的空间,浪费较小.
但是,survivor的内存大小是我们进行估算得到的,我们没有办法确保每次垃圾回收时存活的对象都小于10%,所以需要老年代进行分配担保.分配担保是指,如果survivor的空间不够用,可以在老年代里申请空间存放对象.
标记-整理算法(Mark-Compact)
复制算法在对象存活率较低是一种可靠的算法,但是当对象存活率较高,极端情况下,一次gc的时候,100%的对象都存活,那么复制算法的效率就不高了.因此在HotSpot的老年代中使用另外一种算法.即 标记-整理算法 .
标记-整理算法,首先仍然是和 标记-清除 算法一样的标记过程,但是之后并不进行直接的清除,而是将存活的对象整理的整齐一点,然后以边界为限,回收掉边界以外的内存.示意图如下:
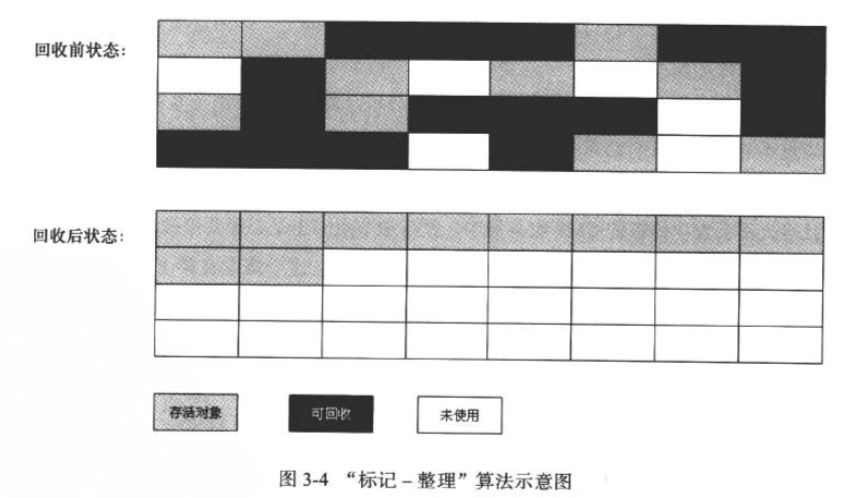
分代收集算法
在上面的垃圾收集算法中也提到了 新生代 , 老年代 等概念,这就是由于现在的虚拟机都使用 分代收集 的算法.
分代的主要目的是: 根据对象的存活周期不同,把内存区域分为几块,存放不同生命周期的对象,以方便根据特点使用不同的垃圾收集算法来提高内存回收效率.
比如新生代中对象存活率低,那么可以使用复制算法,每次copy少量的对象即可,且效率较高.
而老年代中的对象存活率高,并且没有人能为他做分配担保,因此必须使用 标记-整理 或者 标记-清除 算法.
所以在 HotSpot中,整个Java堆大致是如下的样子(新生代和老年代的比例默认为1:2):
垃圾收集器
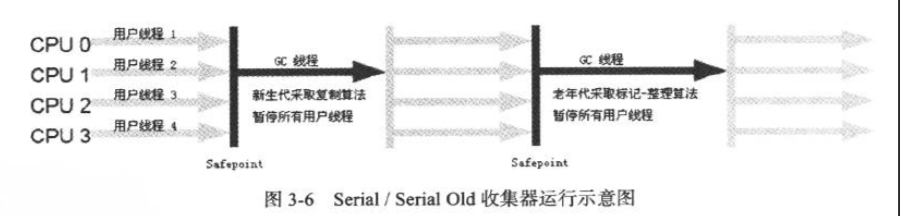
Serial收集器
这是最基本也是最古老的的垃圾收集器,是一个单线程收集的过程,目前仍然是Client模式下的JVM的默认新生代收集器.
下图是他的收集过程:
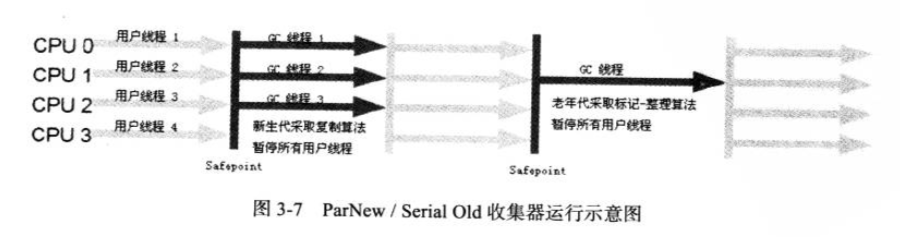
ParNew
ParNew收集器是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集之外,其余行为和Serial收集器一模一样.下图是他的收集过程:
Parallel Scavenge收集器
这个收集器在定义上和ParNew非常相似,但是它主要关注的是提高系统的吞吐量.他的收集过程和ParNew相似.
Serial Old
Serial Old收集器是Serial收集器的老年代版本,使用了标记-整理算法.他的收集过程和Serial一样.
Parallel Old
这是Parallel Scaevnge收集器的老年代版本,使用多线程进行 标记-整理 算法进行收集.
他的收集过程和Parallel Scavenge收集器一样.
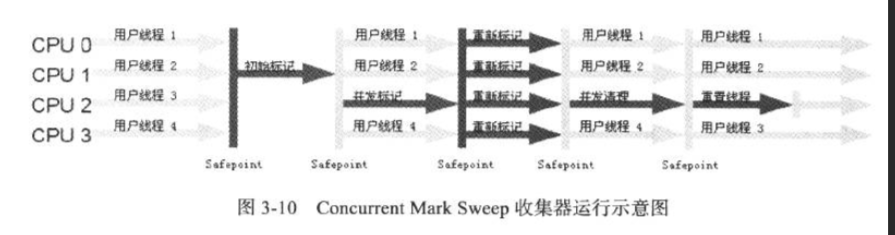
CMS收集器
Concurrent Mark Sweep 是一个以最短停顿时间为目的的收集器,他的收集过程更加复杂一点,分为四个步骤:
- 出师表及
- 并发标记
- 重新标记
- 并发清除
他的收集过程如下所示:
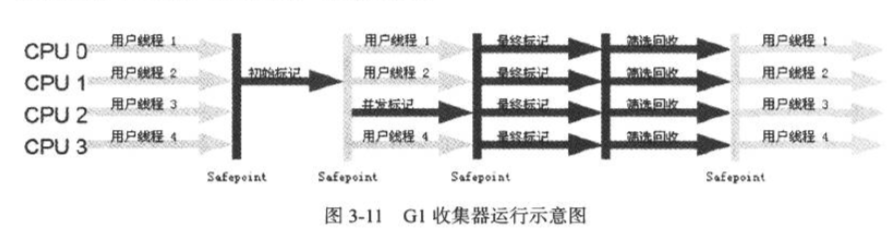
G1收集器
G1收集器是发展的比较好的收集器,他的收集步骤大概有以下几个部分:
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
他的收集过程图如下:
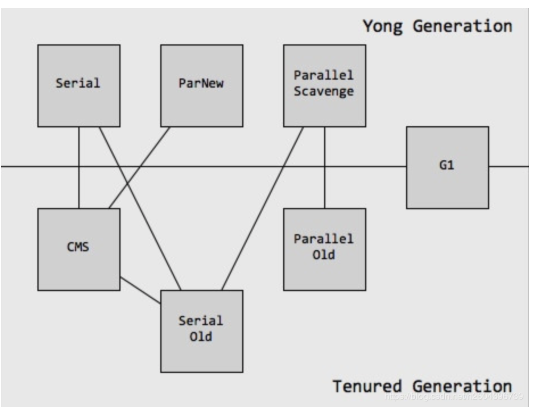
总结
垃圾收集器并不是可以无限搭配的,下面是他们的搭配图:
这里对垃圾收集器的介绍比较简略,主要是垃圾收集器实际上是一个很复杂的东西,但是是一个封装的很好的东西,里面的复杂不太需要知道,大部分时间我们用稳定的最新的研究成果即可....
但是,我们应该了解一下,在感觉瓶颈出在了垃圾收集器的时候,有可以去详细研究的能力以及基础知识即可.
2019-08-11 完成
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

