java架构之路-(分布式zookeeper)zookeeper真实使用场景
上几次博客,我说了一下Zookeeper的简单使用和API的使用,我们接下来看一下他的真实场景。
一、 分布式集群管理:sparkles: :sparkles: :sparkles:
我们现在有这样一个需求,请先抛开Zookeeper是集群还是单机的概念,下面提到的都是以Zookeeper集群来说的。
1. 主动查看线上服务节点
2. 查看服务节点资源使用情况
3. 服务离线通知
4. 服务资源(CPU、内存、硬盘)超出阀值通知
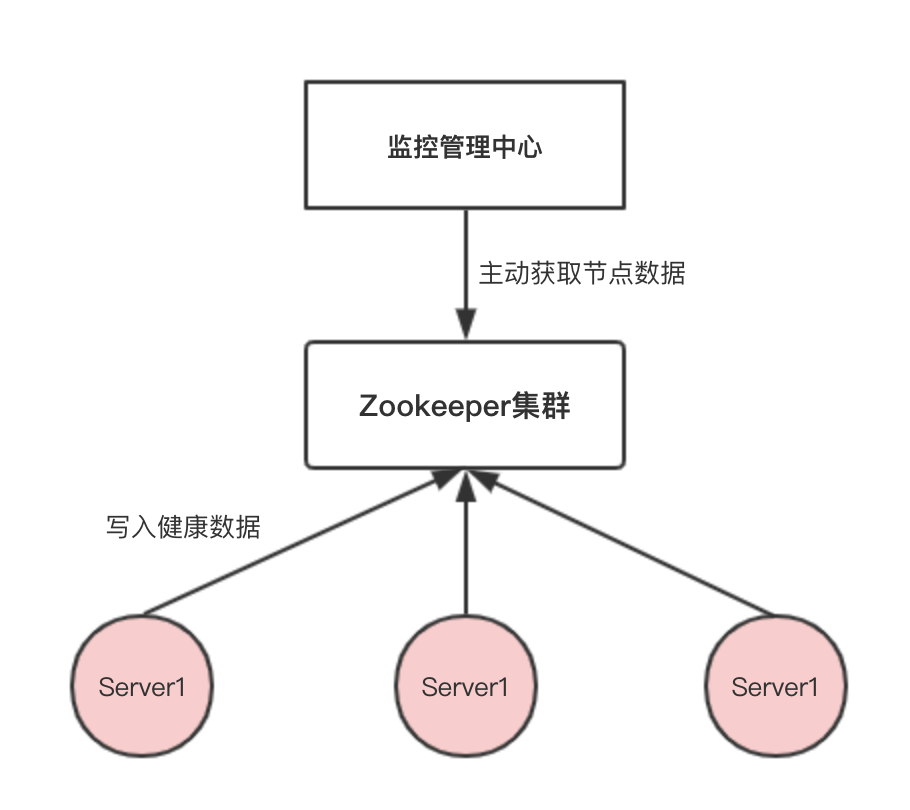
我们先来看一下代码实现流程吧。主要分为两个部分的,一个部分是写入Zookeeper集群,另一部分是获取Zookeeper集群内部的数据。
写入Zookeeper集群部分:
写入的信息包括该服务器的内存使用情况,CPU使用情况等信息。
public void init() {
zkClient = new ZkClient(server, 5000, 10000);
System.out.println("zk连接成功" + server);
// 创建根节点
buildRoot();
// 创建临时节点
createServerNode();
// 启动更新的线程
stateThread = new Thread(() -> {
while (true) {
updateServerNode();//数据写到 当前的临时节点中去
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "zk_stateThread");
stateThread.setDaemon(true);
stateThread.start();
}
//创建根节点,如果根节点已经存在,则不再重复创建
public void buildRoot() {
if (!zkClient.exists(rootPath)) {
zkClient.createPersistent(rootPath);
}
}
// 生成服务节点
public void createServerNode() {
nodePath = zkClient.createEphemeralSequential(servicePath, getOsInfo());
System.out.println("创建节点:" + nodePath);
}
每一个服务都有自己的唯一的临时序号节点。
// 获取服务节点状态
public String getOsInfo() {
OsBean bean = new OsBean();
bean.lastUpdateTime = System.currentTimeMillis();
bean.ip = getLocalIp();
bean.cpu = CPUMonitorCalc.getInstance().getProcessCpu();
MemoryUsage memoryUsag = ManagementFactory.getMemoryMXBean().getHeapMemoryUsage();
bean.usedMemorySize = memoryUsag.getUsed() / 1024 / 1024;
bean.usableMemorySize = memoryUsag.getMax() / 1024 / 1024;
bean.pid = ManagementFactory.getRuntimeMXBean().getName();
ObjectMapper mapper = new ObjectMapper();
try {
return mapper.writeValueAsString(bean);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
// 数据写到 当前的临时节点中去
public void updateServerNode() {
zkClient.writeData(nodePath, getOsInfo());
}
当每个服务开启的时候,我们就应该向我们的Zookeeper发送我们的信息,也就是优先在根节点下创建一个临时序号节点,并且写入服务器的相关信息。就这样我们的Zookeeper集群中就有了我们的服务器相关的信息。
读取Zookeeper集群信息部分:
我们对于我们的节点递归监听就可以了。监听过程可以写入我们的阈值限制,从而达到报警的目的。
// 初始化订阅事件
public void initSubscribeListener() {
zkClient.unsubscribeAll();
// 获取所有子节点
zkClient.getChildren(rootPath)
.stream()
.map(p -> rootPath + "/" + p)// 得出子节点完整路径
.forEach(p -> {
zkClient.subscribeDataChanges(p, new DataChanges());// 数据变更的监听
});
// 监听子节点,的变更 增加,删除
zkClient.subscribeChildChanges(rootPath, (parentPath, currentChilds) -> initSubscribeListener());
}
我们也可以将我们获取到的信息写入到我们的web页面中去。作为我们Zookeeper集群对于服务器健康信息管理的小程序。(我服务器到期了,要不就给你们一套完整的代码演示了,过几天补全)
总结:就是每个服务器往我们的Zookeeper写入数据,在写入之前创建根节点,然后创建我们的临时序号节点再来写入我们的数据,也是利用了临时序号节点的特性,不会重复,而且断开连接会清理掉。也可以将server服务器和我们的Zookeeper部署在同一个服务器也是不会影响的。(自行考虑内存,CPU,网络等问题)
二、 分布式注册中心 :sparkles: :sparkles: :sparkles: :sparkles:
很多分布式项目,并不是使用Spring Clould的Eureka的,自我觉得Eureka和Zookeeper平分秋色吧。我们来看一下我们的需求。
现有一个积分系统,由于使用人数巨大,我们需要同时部署四台服务器才能承载住我们的并发压力。那么我们的请求来了,由谁来控制请求哪台服务器呢?这时就有了我们的Zookeeper注册中心(需结合dubbo)。
我来大致用图解的形式说一下原理,一会再说细节。
分布式注册中心原理:
说到分布式注册中心,我们需要知道几个名词。
注册中心: 注册中心是指我们的Zookeeper集群,主要是用来存储我们的接口信息和监听我们服务提供者是否正常运行的。并且还保存了我们服务消费者的相关信息。
服务提供者: 谁提供了这些接口,谁就是提供者。
服务消费者: 谁想调用这些接口,谁就是消费者。
工作流程:
1.服务启动,也就是我们的接口启动了,优先去我们的注册中心去注册我们的接口信息,也就是用临时序号节点来存我们的接口信息。
2.以后我们的服务提供者会持续的发送消息到注册中心去,持续的告诉我们的注册中心,我们还是可用的,还是活着的。
3.服务消费者来调用我们的接口了, 第一次 ,需要到我们的注册中心去找一个合适接口。(具体如何分配,并不是由Zookeeper来控制的),并将我们的注册中心的提供服务IP列表缓存到自己的服务器上。
4.只要服务提供方节点没有变动,我们的消费者以后的调用,只许读取自己本地的缓存即可,不在需要去注册中心读取我们的服务提供者IP列表。
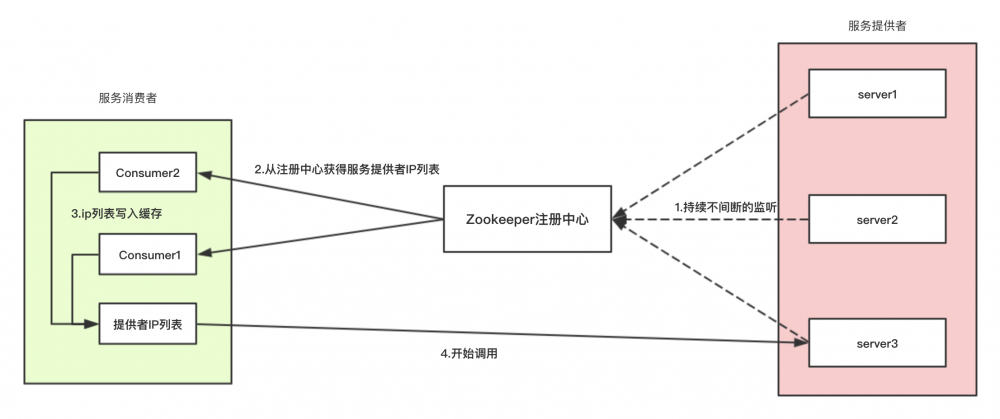
这里有一个最直观的好处就是,原来我们写接口需要指定去哪个IP调用,如果接口服务器IP变了,我们还需要调整我们的程序,这里我们只需要调用Zookeeper即可,不再需要调整程序了。
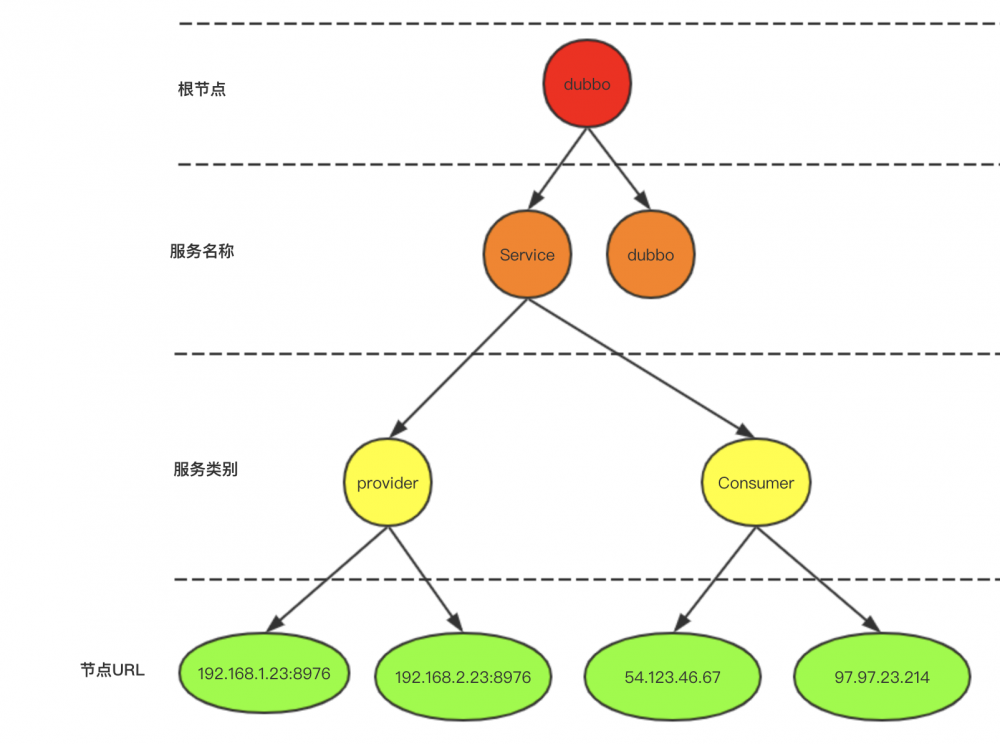
注意:保存消费者,我暂时理解的是为了方便直观的看到当前都有哪些在调用我们的接口。
三、 分布式JOB :sparkles: :sparkles: :sparkles:
分布式JOB,我第一次遇到这个名字的时候是懵的,我还记得我当时做项目要弄一个自动发送邮件的这样一个需求,但是我们是横向部署的,三台服务器都有这段代码,每到半夜11.30的时候都会发三份完全一致的邮件,有人会提出,我们只写一个自动任务,一台服务器部署不就可以了吗?请你弄死他,我们要的高可用,你一台服务器怎么保证高可用,这样的程序是明显不合理的。说到这我们就有了我们的分布式Job,分布式Job就是要解决这样类似的问题的。
还是先看一下实现原理和思路。
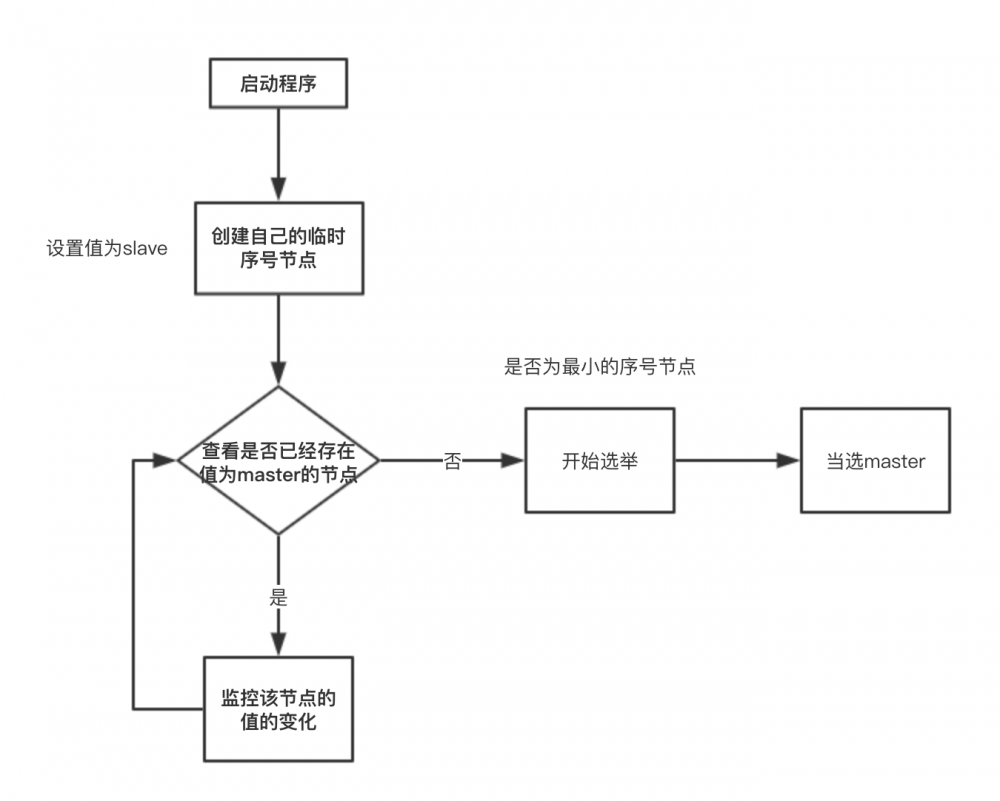
这样我们就能保证只有master服务器能执行我们的自动任务,如果master宕机了,我们会有候补队员保证我们的高可用。
四、 分布式锁 :sparkles: :sparkles: :sparkles: :sparkles: :sparkles: :sparkles:
我们单机的程序,来使用synchronized关键字是可以实现多线程争抢的问题,分布式锁很多是redis集群来实现的,我们来使用Zookeeper也是可以的实现的。
程序内的锁一般分为共享读锁和排它写锁,也就是我们加了共享读锁的时候,其它线程可以来读,但是不能改,而我们的排它写锁,其它线程是不能进行任何操作的。
我们可以这样来设计。
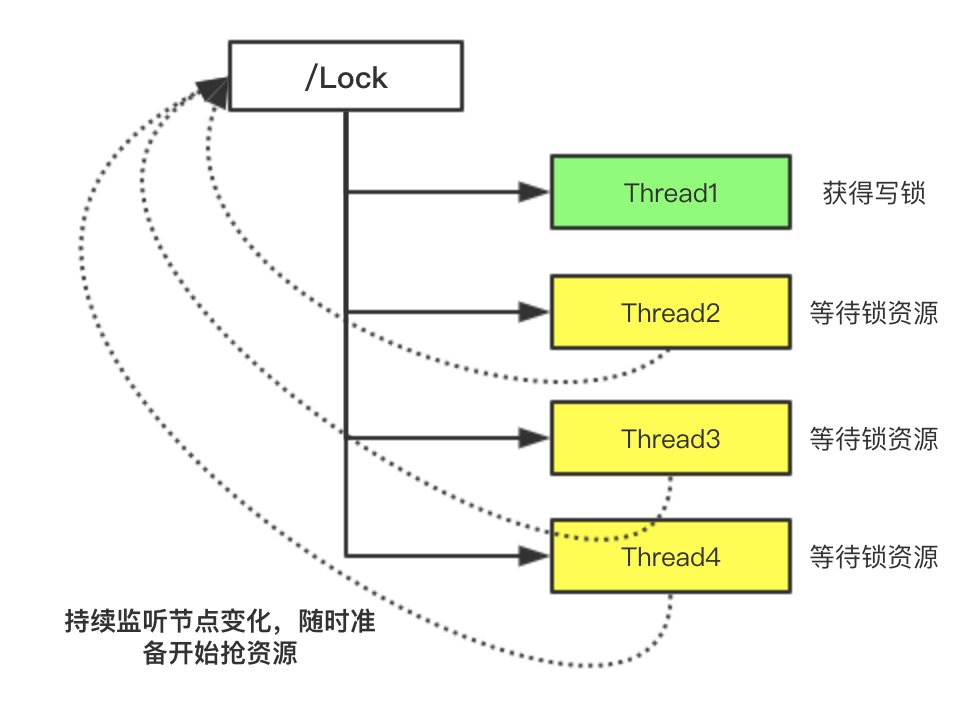
来一个线程就往我们的lock节点内添加一个临时序号节点,值设置为readLock或者是writeLock,标记我们获得是什么类型的锁,当我们再来线城时,优先监听我们的Lock节点的数据,来判断我们是否可以得到锁的资源,感觉还不错,可以实现。但这样的实现并不是很合理的,我们图中画了三个等待的线程还好,如果等待的线程是100个1000个的话,lock节点数据变化了,也就是上一个锁释放掉了,我们那1000个线程会疯抢我们的锁(羊群效应),可以想象1000个大妈在超市抢鸡蛋的样子,可怕....
我们换一个实现的思路再来试试。
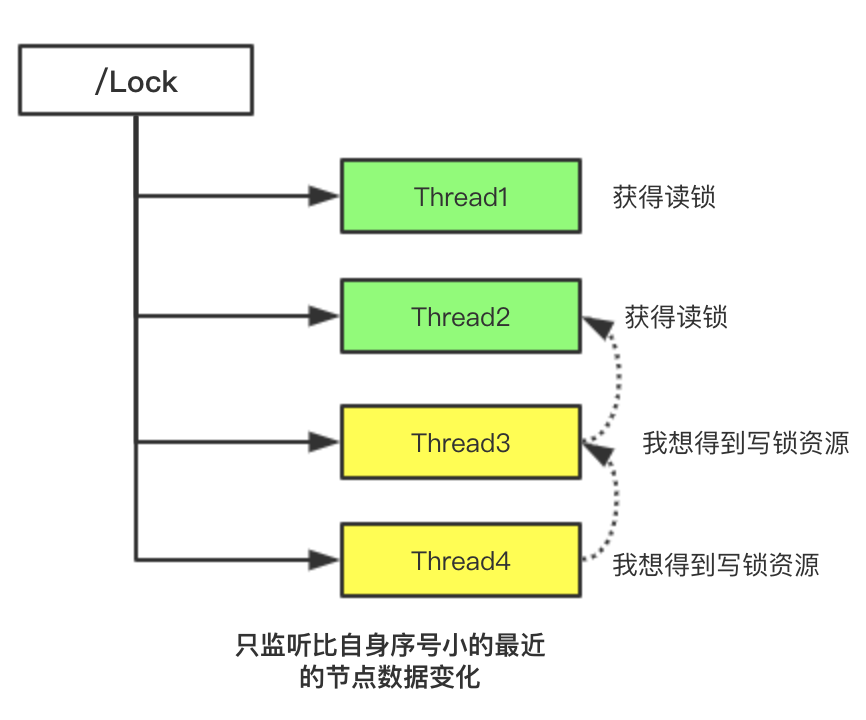
我们这次改为只监听比其小的节点数据即可,以图为例来说,我们的Tread3想获得写锁,必定等待Tread1和Tread2的读锁全部释放,我们才可以给Tread3添加写锁,我们持续监听Tread2线程,当Tread2线程锁释放掉,我们的Tread3会继续监听到Tread1的使用情况,直到没有比他小的在使用锁资源,我们才获得我们的写锁资源。
感觉这个和我们的分布式JOB差不多,最小的序号获得锁。只不过有一个共享读锁和排它写锁的区别而已。
等我服务器续费的,上代码,下次博客继续来说说Zookeeper的 源码 。


最进弄了一个公众号,小菜技术,欢迎大家的加入

正文到此结束
- 本文标签: spring ip 集群 API value src bean 分布式锁 node cat 管理 json client Service 高可用 部署 源码 压力 redis HTML build Job 分布式 递归 服务器 线程 数据 App dubbo JAVA架构 id 并发 root tar UI CTO 总结 ACE Master stream web map 需求 锁 博客 MQ 缓存 update js zookeeper 代码 Eureka 删除 IO synchronized java https 秋色 多线程 list http mapper 注册中心
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

