Java内存模型(一) - 一个码农的期望
最近发现自己在产品思维上有所欠缺,并且刚刚读完《java并发编程艺术这本书》,于是决定从程序员的需求角度大概写写自己对JMM的理解,希望对大家有所帮助。
背景知识
了解一个解决方案首先得明白它处理的问题,通过背景知识,我们可以更好的理解它产生的原因,以及其中所包含的思想
在单个处理器的处理速度的提升已经不在明显的时候,人们便尝试使用多种方法来提高计算机的运算效率,其中包括
- 引入多级缓存机制,同过减少了读取运算数据、存储运算结果等I/O操作的次数,让计算机运算快速执行,减少了处理器等待时间
- 使用多核处理器,三个臭皮匠顶过顶过一个诸葛亮
- 代码乱序优化,重新调整顺序的代码可以使用硬件底层的批处理等技术,加快运算效率
但同时一个全新概念的引入,往往会伴随着诸多问题等待着这些伟大的先驱者去解决。
缓存一致性问题
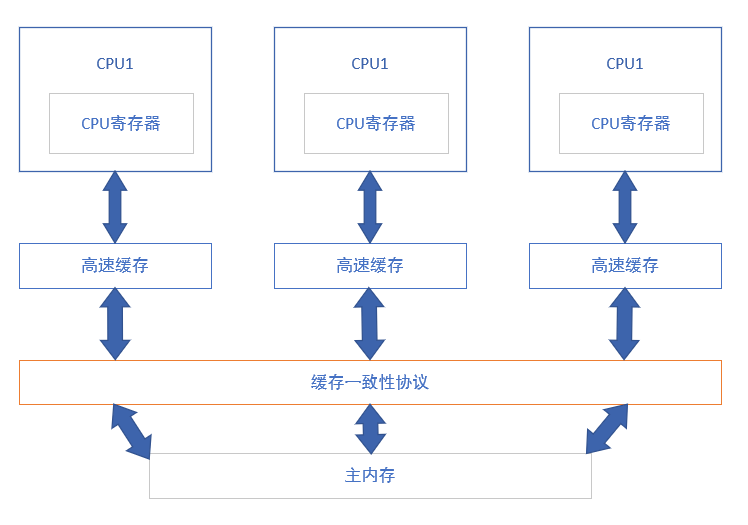
10/13/16dc57096e9b6482?w=1003&h=716&f=png&s=54796)
当多个处理器要使用和修改主内存中同一块区域时,可能会导致不同处理器中的数据不一样,如何将不同CPU寄存器、高速缓存中的数据进行同步,保证数据的一致性,运算的正确性的同时保证处理器的效率是设计着需要考虑的问题。在硬件上,各个处理器都遵循了各自的一致性协议,来解决这些问题
指令重排序问题
# CPU1 CPU1 a = 2 b = 100 b = 100 a = 2 print(a + b) print(a + b) 复制代码
重排序能够有效的提高处理器的运算效率,但是重排序有时候会让结果发生错误,尤其是在多核环境下,会发生很多奇妙的问题,猜猜下面两个CPU输出的结果
# CPU1 CPU2
a = 10 b = 20
b = a + 100 a = b + 100
print(f"b = {b}") print(f"a = {a}")
复制代码
如果已多次运行以上程序会发现,在终端中竟然出现了 a = 100, b = 100的结果, 原因是底层处理器”自以为是“的重排序使得我们运行的程序变成如下
# CPU1 CPU2
a = 10 b = 20
print(f"b = {b}") print(f"a = {a}")
b = a + 100 a = b + 100
复制代码
各种硬件的区别
为解决多核处理器所带来的问题,不同的设计着提供了不同的方案,但对于程序员,了解这些策略并编写正确的程序具有很大的难度
程序员对JMM的期望
在生活中我们常常做不了甲方,但对于JAVA的设计者们来说,我们就是甲方,而且我们的要求不多,也并不过分
顺序一致性
当我们程序员写出了正确的代码的前提下,希望程序按照我们所设想的代码顺序执行,并输出正确的结果
所以在设计的时候,处理器的内存模型和编程语言的内存模型都会以顺序一致性作为参考,接下我们具体的谈谈顺序一致性的具体要求
数据读写与顺序一致性
当我们处理多线程问题的时候,常常会遇到如下数据竞争的问题:
- 线程1: 读取内存区域的x变量
- 线程2: 更新内存预取的x变量
- 以上两个操作如何同步?
作为程序员我们期望,当我们约定了线程1的操作先于线程2执行(反之亦然),此时这个程序便成为了一个没有数据竞争的程序,同时我们也可以称之为正确同步的程序,该程序的执行将具有 顺序一致性
线程与顺序一致性
当我们运行了多个线程的时候,顺序一致性向我们保证了:
- 一个线程的所有操作必须按照程序的顺序来执行(无指令重排序),所有操作只能看到一个单一的操作执行顺序(将并行转化为串行)
- 每个操作必须是 原子执行 且立刻对所有线程可见。(注:原子执行是指这种操作一旦开始,就一直运行到结束,中间不会有任何线程切换)
 {
a = 1;
flag = true;
}
public synchronized void reader() {
if (floag) {
int i = a;
...
}
}
}
复制代码
在上面实例代码中,writer()和reader()方法,分别在线程1和线程二中执行,我们也期望同步块中的执行也满足线程的 顺序一致性 。
代码的运行效率
在满足 顺序一致性 的条件下,我们希望代码的执行效率越快越好
代码的可读性和易实现
我们希望JAVA的设计者们能够提供安全且易实现的机制,满足顺序一致性以及执行效率,并且让我们的写出来的代码具有良好的可读性。
JMM的诞生
效率与一致性的博弈
从上文我们可以看到,顺序一致性与执行效率是相互矛盾的,所以JAVA的设计者们做了如下决定
在满足执行结果与程序员期望结果的前提下,尽可能的减少顺序一直性对内存模型的束缚
为此,提出了happens-before原则来描述这种设计理念,本文不会针对这个概念做深入的解释,但我们可以这么理解,设计者们为程序员创造了一个程序是按照顺序一致性执行的桃花源,它不会违背程序员所期望的结果,但实际过程却有所不同。
语言设计
java设计者们为达到可读性和易实现性,提供了一下关键字和方法
- synchronized 关键字
- volatile 关键字
- final 关键字
- 锁
- concurrent包
JMM就是由这些小部件组成
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

