对象池化的艺术
对象池化的技术的出现都是可以说是不得以而为之,如果我们有足够快的CPU,足够大的内存,那么对象池化的技术是完全没必要,各种垃圾回收也是没必要的;但凡事总有个但是,资源总是有限的,如何在有限资源下发挥出最优效果,也是自人类诞生以来一直在探索的问题。
Tomcat-高效的环形队列
Tomcat是在Java技术体系中常用的Web容器,其采用的NIO(非阻塞I/O)模型相较于传统的BIO(阻塞I/O)来说获得了更高的性能。其NIO模型如下图所示。

Acceptor用于阻塞的接收连接,在接收到连接之后选择一个Poller来执行后续I/O任务处理。(Poller数量是固定的)
如果是你,你会如何实现这个选择Poller的过程呢?不妨先考虑一下
在Tomcat中会将Poller保存在一个环形队列中,并通过一个原子变量来循环获取队列中的下一个元素, 如下图所示。
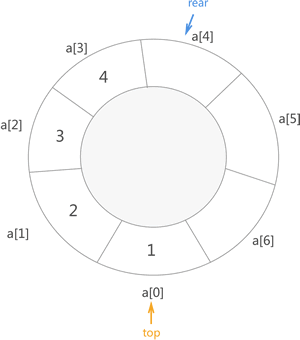
图片来自于 点击访问 ,自己画的实在太丑了
环形队列在物理意义上是以线性数组(链表亦可)的方式进行保存的,并非是真的是圆形的方式存在在内存中。
我们可以使用javascript来快速体验一下环形数组.
let pollers = [1,2,3,4,5,6]
let index = 0
let getNext = function(){
return pollers[Math.abs(index++) % pollers.length]
}
for(let i = 0 ; i < 10086 ; i++){
console.log(getNext())
}
复制代码
可以看出环形队列的实现就在于取余操作可以将我们的索引 index 给限制 pollers.length 范围内,使得我们永远可以取到队列中下一个元素,如果队列被取完了,则会回到队列的头部重新开始遍历。
仅仅如此吗?在JS中你这样子玩完全没问题,因为浏览器的JavaScript是 单线程 的执行不会遇到并发问题,但作为一名后端程序猿, 并发以及线程安全 是你必须考虑到。
分析代码可以发现,我们需要维护一个索引 index 来标志当前所在的位置,因此如果我们将 index 用原子类保存,这样就不会遇到线程安全问题也不用加锁。
因此Poller对象池的实现其实挺简单的,如下代码所示, pollerRotater 是一个原子类,可以保证我们无锁,且线程安全的获取下一个索引(原子类的相关介绍,可以看这位老哥的文章)
public Poller getPoller0() {
int idx = Math.abs(pollerRotater.incrementAndGet()) % pollers.length;
return pollers[idx];
}
复制代码
Jetty-精打细算的房产投资者
如果你是手头比较紧的房产投资人,考虑一下如何投资房产才能使效益最大化?通常来说有一下几种选择
- 高位接盘,借遍了亲戚朋友顺便掏空了六个钱包,结果血本无归
- 买二手房,你接手了各种类型房子并改造成了各种类型的出租房(单身公寓、两居、三居室等等)租给客户,于是你每年都有了固定的收入(和城中村的二房东聊过,一年几十万是有的)
同理,对于计算机来说内存和CPU都是珍贵的资源,如果你一开始创建了大量的对象,那么将占据大量的资源,并且很有可能这些对象一个都不回被复用并且还会使你的内存溢出,服务崩溃。(当然,如果你服务器内存足够大,当我没说)
因此,我们并可以回收那些不再需要用到对象,并保存到我们对象池中,因此要被回收的对象需要有恢复到最初使的状态。(租客不再续租房子了,我们需要对房子进行清理一遍租给其他客户)
此外我们还可以对对象进一步细化进行分类,以满足不同类型的需求(如单身客户一般都租单人间,有老婆孩子都会租大一点的)
那么对象池化技术在Jetty中都使怎么应用的呢?
我们知道,不论使用NIO或者BIO都需要提供一个缓冲区以供读写数据,并且这些缓冲区会被频繁的使用到,因此Jetty为缓冲区设计了一个对象池 ByteBufferPool
ArrayByteBufferPool
ArrayByteBufferPool是ByteBufferPool的一个实现
默认情况下ArrayByteBufferPool的结构如下图所示
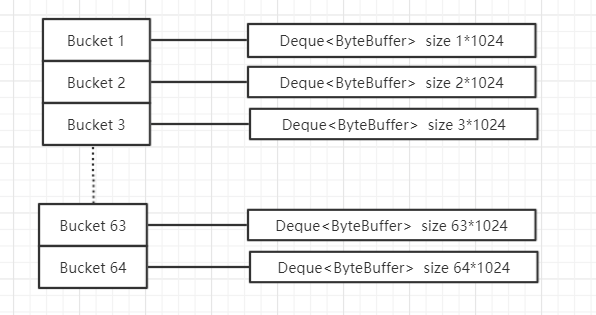
如上图所示Bucket使用线性数组来保存,每个 Bucket 装的都是不同大小的 ByteBuffer 缓冲区,以适应不同缓冲区大小需求。默认的有64个 Bucket , ByteBuffer 的基础大小称为 Factor 在此图中 factor 的大小为1024。
为什么要对缓冲区大小进行分类?原因很简单,充分利用资源(你让一个单身汉去租三居室,这不害人吗,有钱的话,当我没说)
并且我使用Fiddler简单统计了一下访问掘金首页过程中常见的数据包大小。
- 请求的数据包大都在
100b至400b之间(说明如果我们使用jetty的话还是有优化空间的,如将factor调整为512以节省空间) - 响应的数据报在
100b至1000kb之间,最大的主要是静态资源(js、css)等完全可以放在CDN上来减轻Web容器的压力
如你所看到,对ByteBuffer按大小进行分类可以让我们充分利用资源,并且通过调整factor参数来减少内存的占用来实现进一步的优化。
注意 实际保存 ByteBuffer 的是 ConcurrentLinkedDeque ,因为名字太长所以用其接口来表示
那么,如何根据缓冲区呢大小获取相应的Bucket,使用以下公式即可
Bucket索引=(目标缓冲区大小 - 1 ) / factor
在本例中,factor是1024, 如果要想要一个10086大小的缓冲区应有
(10086 - 1)/1024 = 10 即Bucekt得数组索引为10,是Bucekt数组中的第十一个元素其ByteBuffer的大小为 1024*11
至于为什么要将缓冲区大小减一,相信你稍微思考一下便知晓
值得注意是, ArrayByteBufferPool 并不会在一开始就立即为所有 Bucket 分配 ByteBufferPool 。而是在需要使用的时候先判断有没有目标大小的 ByteBuffer ,如果有则从相应的Bucekt中取一个返回给调用方,如果没有则新建一个 。在不需要使用的时候由调用方主动归还给 ArrayByteBufferPool
除此之外, 还可以为 ArrayByteBufferPool 指定最大内存(避免耗尽内存造成内存溢出),当缓存的 ByteBuffer 的大小总和超过这个值的时候会执行清理工作,将旧的 Bucekt 清除掉。
有兴趣的可以阅读相应类的源码
org.eclipse.jetty.io.ArrayByteBufferPool 复制代码
总结
分而治之 可以说是人类解决问题基本方法论。如果你了解 ConcurrentHashMap 的分段锁,那么你就应该会对Jetty的 ByteBufferPool 的设计思想倍感亲切,都是 分而治之 的思想的最好实践。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

