Java 中的字符集与编码
关于 ASCII , Unicode 和 UTF-8 的概念这里不再赘述,可以通过链接查看它们在维基百科上的定义。
快速入门,推荐阅读阮一峰的博客《 字符编码笔记:ASCII,Unicode 和 UTF-8 》
本文主要介绍Java中对字符是如何存储并读取的
一个汉字“张”引发的一系列问题
- 首先确定"张"的 Unicode码 为16进制
U+5F20 - 16进制
5F20转换为2进制为0101 1111 0010 0000

- 查看Unicode和UTF-8的转换规则
- 在ASCII码的范围,用一个字节表示,超出ASCII码的范围就用字节表示,这就形成了我们上面看到的UTF-8的表示方法,这様的好处是当UNICODE文件中只有ASCII码时,存储的文件都为一个字节,所以就是普通的ASCII文件无异,读取的时候也是如此,所以能与以前的ASCII文件兼容。
- 大于ASCII码的,就会由上面的第一字节的前几位表示该unicode字符的长度,比如110xxxxx前三位的二进制表示告诉我们这是个2BYTE的UNICODE字符;1110xxxx是个三位的UNICODE字符,依此类推;xxx的位置由字符编码数的二进制表示的位填入。越靠右的x具有越少的特殊意义。只用最短的那个足够表达一个字符编码数的多字节串。注意在多字节串中,第一个字节的开头"1"的数目就是整个串中字节的数目。
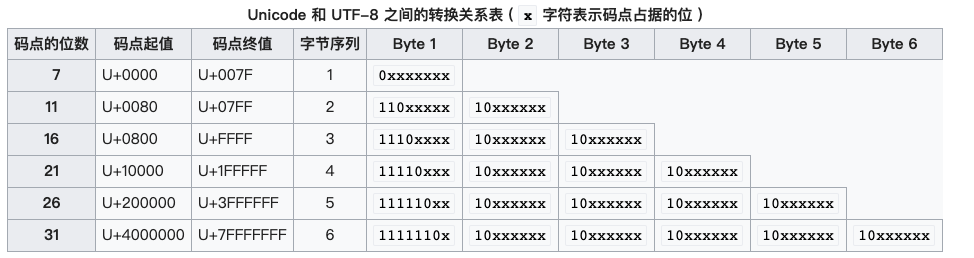
因为 U+5F20 落在 U+0800 ~ U+FFFF 区间,可以确定汉字“张”转换成 UTF-8 格式后由 3个字节 组成,按照上面的转换规则,得出 汉字“张”的 UTF-8 编码为 1110 0101 1011 1100 1010 0000

这和我们直接查看"张"的编码是保持一致的(默认编码为UTF-8)

- 用FileReader读取字符
File file = new File(System.getProperty("user.dir") + "/src/main/java/com/dsying/IO/a.txt");
Reader reader = new FileReader(file);
System.out.println(reader.read()); // 24352
复制代码
24352的确是汉字“张”的10进制码点

- 用FileInputStream读取字节
File file = new File(System.getProperty("user.dir") + "/src/main/java/com/dsying/IO/a.txt");
FileInputStream is = new FileInputStream(file);
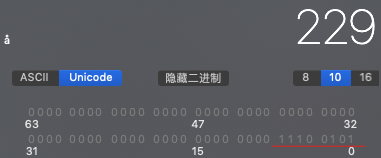
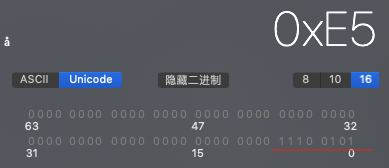
System.out.println(is.read()); // 229
复制代码
229 的16进制表示确实是 E5 ,也就是汉字"张”的第1个字节
- 用FileInputStream读取字节数组
File file = new File(System.getProperty("user.dir") + "/src/main/java/com/dsying/IO/a.txt");
FileInputStream is = new FileInputStream(file);
// 每次读取3个字节
byte[] bytes = new byte[3];
is.read(bytes);
System.out.println(Arrays.toString(bytes)); //[-27, -68, -96]
复制代码
为什么bytes里存的是负数,明明第一个字节E5对应的十进制应该是229啊,存的为什么是-27?
这是因为 byte 只能存 1 个字节即 8 个二进制位,也就是 -128 ~ 127 之间的数,byte显然存不下229,发生了溢出
-27再如何转为229?
负数的二进制可由正数的二进制 取反加一 得到
然后再用 1110 0101 & 0xff 最终得到 1110 0101 (高位全部为0)也就是 229
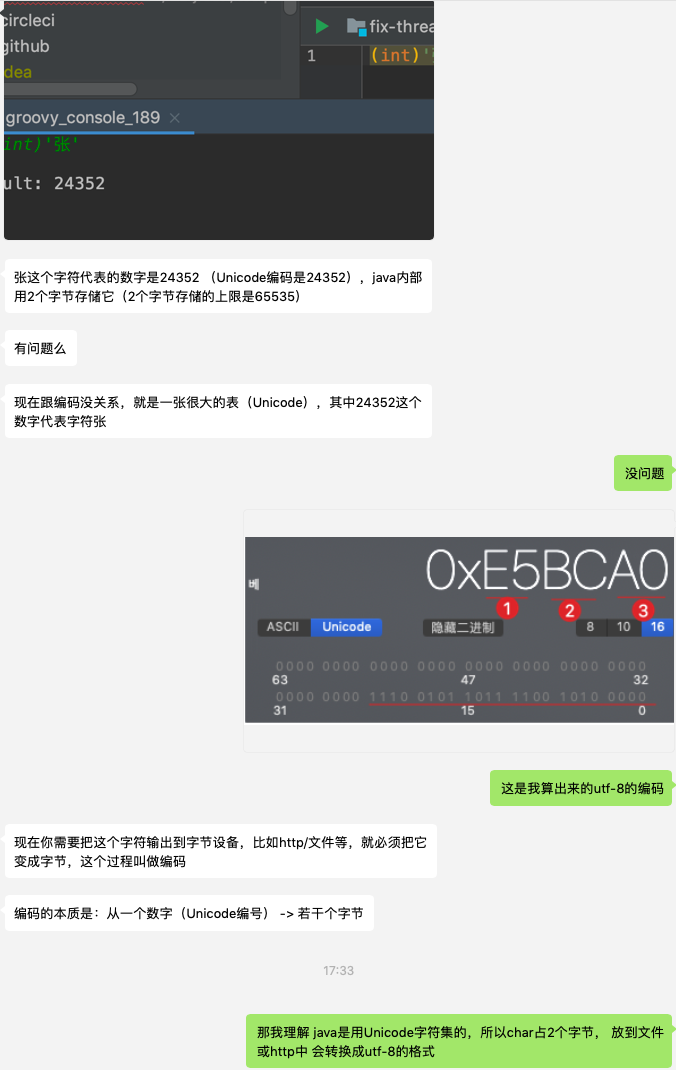
Java中char类型占多少字节?如果是2个字节,为什么有时getBytes().length > 2
放上一张我咨询别人的截图
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

