初学Hadoop之计算TF-IDF值
1.词频
TF(term frequency)词频,就是该分词在该文档中出现的频率,算法是:(该分词在该文档出现的次数)/(该文档分词的总数),这个值越大表示这个词越重要,即权重就越大。
例如:一篇文档分词后,总共有500个分词,而分词”Hello”出现的次数是20次,则TF值是: tf =20/500=0.04

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

或者

2.逆文档频率
IDF(inversedocument frequency)逆向文件频率,一个文档库中,一个分词出现在的文档数越少越能和其它文档区别开来。算法是: log(总文档数/(出现该分词的文档数+1)) 。如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。
例如:一个文档库中总共有50篇文档,2篇文档中出现过“Hello”分词,则idf是: Idf = log(50/3) =1.2218487496
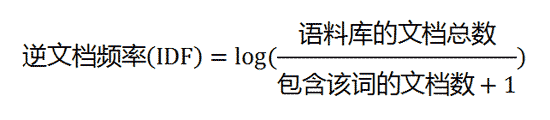
3.TF-IDF
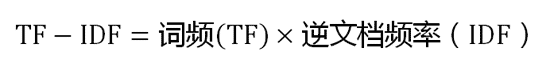
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。
3.1用途
自动提取关键词,计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
信息检索时,对于每个文档,都可以分别计算一组搜索词("Hadoop"、"MapReduce")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
3.2优缺点
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不 多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和 每一段的第一句话,给予较大的权重。)
4.使用Hadoop计算TF-IDF
运行参数,第一个为文本存储路径,第二个为临时路径,第三个为结果输出路径
/home/hadoop/input /home/hadoop/temp /home/hadoop/output
package com.example.test; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TFIDF { // part1------------------------------------------------------------------------ public static class Mapper_Part1 extends Mapper<LongWritable, Text, Text, Text> { String File_name = ""; // 保存文件名,根据文件名区分所属文件 int all = 0; // 单词总数统计 static Text one = new Text("1"); String word; public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { InputSplit inputSplit = context.getInputSplit(); String str = ((FileSplit) inputSplit).getPath().toString(); File_name = str.substring(str.lastIndexOf("/") + 1); // 获取文件名 StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word = File_name; word += " "; word += itr.nextToken(); // 将文件名加单词作为key es: test1 hello 1 all++; context.write(new Text(word), one); } } public void cleanup(Context context) throws IOException, InterruptedException { // Map的最后,我们将单词的总数写入。下面需要用总单词数来计算。 String str = ""; str += all; context.write(new Text(File_name + " " + "!"), new Text(str)); // 主要这里值使用的 "!"是特别构造的。 因为!的ascii比所有的字母都小。 } } public static class Combiner_Part1 extends Reducer<Text, Text, Text, Text> { float all = 0; public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { int index = key.toString().indexOf(" "); // 因为!的ascii最小,所以在map阶段的排序后,!会出现在第一个 if (key.toString().substring(index + 1, index + 2).equals("!")) { for (Text val : values) { // 获取总的单词数。 all = Integer.parseInt(val.toString()); } // 这个key-value被抛弃 return; } float sum = 0; // 统计某个单词出现的次数 for (Text val : values) { sum += Integer.parseInt(val.toString()); } // 跳出循环后,某个单词数出现的次数就统计完了,所有 TF(词频) = sum / all float tmp = sum / all; String value = ""; value += tmp; // 记录词频 // 将key中单词和文件名进行互换。es: test1 hello -> hello test1 String p[] = key.toString().split(" "); String key_to = ""; key_to += p[1]; key_to += " "; key_to += p[0]; context.write(new Text(key_to), new Text(value)); } } public static class Reduce_Part1 extends Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text val : values) { context.write(key, val); } } } public static class MyPartitoner extends Partitioner<Text, Text> { // 实现自定义的Partitioner public int getPartition(Text key, Text value, int numPartitions) { // 我们将一个文件中计算的结果作为一个文件保存 // es: test1 test2 String ip1 = key.toString(); ip1 = ip1.substring(0, ip1.indexOf(" ")); Text p1 = new Text(ip1); return Math.abs((p1.hashCode() * 127) % numPartitions); } } // part2----------------------------------------------------- public static class Mapper_Part2 extends Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String val = value.toString().replaceAll(" ", " "); // 将vlaue中的TAB分割符换成空格 // es: Bank // test1 // 0.11764706 -> // Bank test1 // 0.11764706 int index = val.indexOf(" "); String s1 = val.substring(0, index); // 获取单词 作为key es: hello String s2 = val.substring(index + 1); // 其余部分 作为value es: test1 // 0.11764706 s2 += " "; s2 += "1"; // 统计单词在所有文章中出现的次数, “1” 表示出现一次。 es: test1 0.11764706 1 context.write(new Text(s1), new Text(s2)); } } public static class Reduce_Part2 extends Reducer<Text, Text, Text, Text> { int file_count; public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 同一个单词会被分成同一个group file_count = context.getNumReduceTasks(); // 获取总文件数 float sum = 0; List<String> vals = new ArrayList<String>(); for (Text str : values) { int index = str.toString().lastIndexOf(" "); sum += Integer.parseInt(str.toString().substring(index + 1)); // 统计此单词在所有文件中出现的次数 vals.add(str.toString().substring(0, index)); // 保存 } double tmp = Math.log10( file_count*1.0 /(sum*1.0)); // 单词在所有文件中出现的次数除以总文件数 = IDF for (int j = 0; j < vals.size(); j++) { String val = vals.get(j); String end = val.substring(val.lastIndexOf(" ")); float f_end = Float.parseFloat(end); // 读取TF val += " "; val += f_end * tmp; // tf-idf值 context.write(key, new Text(val)); } } } public static void main(String[] args) throws Exception { // part1---------------------------------------------------- Configuration conf1 = new Configuration(); // 设置文件个数,在计算DF(文件频率)时会使用 FileSystem hdfs = FileSystem.get(conf1); FileStatus p[] = hdfs.listStatus(new Path(args[0])); // 获取输入文件夹内文件的个数,然后来设置NumReduceTasks Job job1 = Job.getInstance(conf1, "My_tdif_part1"); job1.setJarByClass(TFIDF.class); job1.setMapperClass(Mapper_Part1.class); job1.setCombinerClass(Combiner_Part1.class); // combiner在本地执行,效率要高点。 job1.setReducerClass(Reduce_Part1.class); job1.setMapOutputKeyClass(Text.class); job1.setMapOutputValueClass(Text.class); job1.setOutputKeyClass(Text.class); job1.setOutputValueClass(Text.class); job1.setNumReduceTasks(p.length); job1.setPartitionerClass(MyPartitoner.class); // 使用自定义MyPartitoner FileInputFormat.addInputPath(job1, new Path(args[0])); FileOutputFormat.setOutputPath(job1, new Path(args[1])); job1.waitForCompletion(true); // part2---------------------------------------- Configuration conf2 = new Configuration(); Job job2 = Job.getInstance(conf2, "My_tdif_part2"); job2.setJarByClass(TFIDF.class); job2.setMapOutputKeyClass(Text.class); job2.setMapOutputValueClass(Text.class); job2.setOutputKeyClass(Text.class); job2.setOutputValueClass(Text.class); job2.setMapperClass(Mapper_Part2.class); job2.setReducerClass(Reduce_Part2.class); job2.setNumReduceTasks(p.length); FileInputFormat.setInputPaths(job2, new Path(args[1])); FileOutputFormat.setOutputPath(job2, new Path(args[2])); job2.waitForCompletion(true); // hdfs.delete(new Path(args[1]), true); } }
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

