Java -- 字符串常量池介绍
最近看到个案例,twitter工程师在地理位置信息存储上使用 String.intern() 方法从而节省了大量内存,关键点就是JVM的 String Pool ,因此本篇文章对 String Pool 探个究竟。(没看过源码,主要是根据往上资料以及个人理解)
String Pool
什么是String Pool
JVM所使用的内存中,字符串作为一种特殊的基础数据类型,占据了大量的内存,且字符串有着大量的重复。由于字符串具体不可变性,因此使用 String Pool 对于同样的字符串做一个缓存,防止多次分配内存,从而提高内存利用率。
String Pool是什么结构
String Pool 在JDK当中是一个类似HashTable的结构,其特点线程安全,不可扩容,但是可以rehash
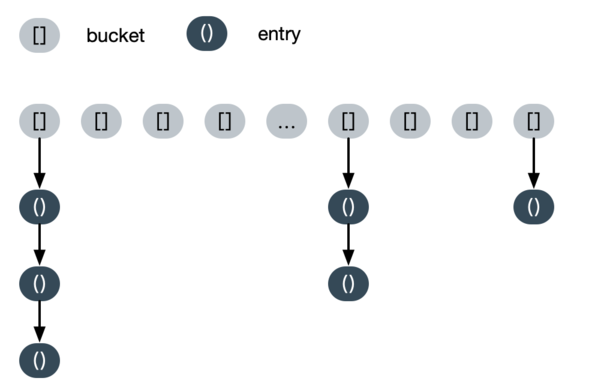
String Pool存在什么区域
JDK6之前, String Pool 存放在永久代,因此大小受到永久代的限制,默认1009大小,且不可更改。从JDK7开始 String Pool 转移到了堆内存当中,默认大小为60013(用素数降低冲突概率),此时可以通过 -XX:StringTableSize 参数进行控制大小,可以使用 -XX:+PrintStringTableStatistics 参数,让JVM退出时打印出常量池使用情况。
哪些字符串会放到String Pool
可以把代码中常用的字符串分为三类,然后分别做实验。
private static final String STR1 = "world" String str = "hello";
首先使用一个空Main方法,增加 -XX:+PrintStringTableStatistics 参数,在IDEA JDK8下,我电脑运行的输出 Number of entries 一直是840,那么这个就是基础数据了。
# 代码
public class Main {
public static void main(String[] args) {
}
}
# 输出
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 840 = 20160 bytes, avg 24.000
Number of literals : 840 = 57584 bytes, avg 68.552
增加局部变量后,常量池大小+1
# 代码
public class Main {
public static void main(String[] args) {
String str1 = "hello";
}
}
# 输出
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 841 = 20184 bytes, avg 24.000
Number of literals : 841 = 57640 bytes, avg 68.537
增加静态变量,常量池大小+1
# 代码
public class Main {
private static final String STR = "world";
public static void main(String[] args) {
String str1 = "hello";
}
}
# 输出
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 842 = 20208 bytes, avg 24.000
Number of literals : 842 = 57696 bytes, avg 68.523
动态拼接,常量池不变
# 代码
public class Main {
private static final String STR = "world";
public static void main(String[] args) {
String str1 = "hello";
for (int i = 0; i < 10; i++) {
String temp = Integer.toString(i);
}
}
}
# 输出
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 842 = 20208 bytes, avg 24.000
Number of literals : 842 = 57696 bytes, avg 68.523
动态拼接,增加intern调用,常量池+10
# 代码
public class Main {
private static final String STR = "world";
public static void main(String[] args) {
String str1 = "hello";
for (int i = 0; i < 10; i++) {
String temp = Integer.toString(i).intern();
}
}
}
# 输出
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 852 = 20448 bytes, avg 24.000
Number of literals : 852 = 58176 bytes, avg 68.282
那么从我这个不专业的测试,可以得出结论,如有疑议可以评论中讨论哈。
- 字面字符串常量会进入到字符串常量池
- 代码中动态生成的字符串不会进入常量池
- intern可以主动让字符串进入常量池
常见问题解释
1.String str4 = new String(“abc”)执行过程?
通过反编译以及常量池输出,可以看出结论,常量池+1,不包括常量池的话,对象也是+1,流程是先创建(new)一个String对象,压入(dup)到栈顶,然后从常量池中(ldc)初始化abd字符串,调用构造函数初始化(invokespecial)对象,最后将对象引用赋值(astore_1)给本地变量str4。反编译插件可以使用 IDEA插件 – Class Decompile
# 反编译结果
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String abc
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
10: return
}
# 常量池输出
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 841 = 20184 bytes, avg 24.000
Number of literals : 841 = 57632 bytes, avg 68.528
2.JDK6与JDK7下不同代码结果差异
往上常见的题目如下,JDK6下 false,false ,JDK7下 false,true ,那么本质原因我认为是字符串常量池所在位置调整导致,JDK6时,字符串常量池位于永久代,因此对象也直接在永久代分配,由于永久代不会很大,所以所以大小被限制在1009。那么同一个对象,intern进入到常量池后,实际上会在永久代创建一个新的对象。而JDK7下,字符串常量池转移到堆中,不再有容量限制问题,因此可以直接利用堆中已经存在的对象(S4就是直接使用了S3对象),而不需要重新创建。
public static void main(String[] args) {
String s = new String("1"); # 该对象创建出来时,常量池已经有1存在
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1"); # 与s最大的不同,是该对象创建出来时,常量池并没有存在11
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
intern使用技巧
String Pool 的本意是缓存高复用的字符串对象,从而节省大量内存,那么遵从本意就是合理使用。
举个例子,假设某一业务需要在服务端Session中保存用户的地理位置信息(省,市,县),那么地理位置信息就属于高复用字符串对象,使用intern必定会节省大量内存消耗。再举个反例,某中间件做链路追踪时,生成的traceId,误调用了intern方法,那么结果会导致字符串常量池越来越大,YGC时扫描的对象越来越多,从而导致线上YGC越来越耗时,最终引发故障。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

