使用Java实现DDD持久性构建机制,避免JPA等基础设施污染领域模型 - Oliver Drotbohm
当涉及到实现DDD模型对象从仓储数据库中创建时,人们通常很难在纯正概念和技术实用主义之间找到良好的平衡。在本文中,我将讨论一个实验性想法,以Java代码表达DDD的一些战术设计概念,并导出元数据,例如实现持久性,而不会使用JPA等技术注释污染了领域模型,同时在模型上附加了映射层。
上下文
在Java应用程序中,可以通过多种方式来实现域驱动设计的构建块。在将实际领域模型与特定于技术的方面分离时,这些方法通常会做出不同的权衡。许多Java项目在仍然使用例如JPA批注直接注释在领域模型类上,这种简化持久性虽然不必维护单独的持久性实体类,却换来了错误依赖。这是否一个好主意不在本文讨论范围之内。我们的主要重点是看看即使在这种情况下,我们如何也可以使领域模型更专注于DDD。
我们要涉及的另一方面是如何使DDD构造在代码中可见。通常,它们中的很多都可以间接地标识出来,例如,通过分析由Spring Data存储库管理的领域类型按照其定义是聚合的。但是,在这种情况下,我们依赖于一种特定的持久性技术来精确地获取该信息。同样,如果我们可以在没有任何其他上下文的情况下通过观察类型来推理类型的角色,那不香吗?
案例
让我们从一个简单的例子开始,请注意,模型类不是设计模型的唯一方法。我只是在描述在特定情况下设计的结果。它涉及如何在代码中表示集合,实体或值对象,以及一种特定方式的效果。
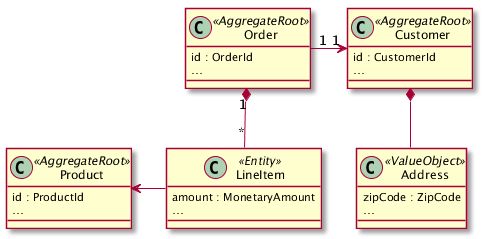
让我们从Order到Customer 总体关系开始。直接使用JPA注释在模型类代码中非常幼稚,可能看起来像这样:
@Entity
<b>class</b> Order {
@EmbeddedId OrderId id;
@ManyToOne Customer customer;
@OneToMany List<LineItem> items;
}
@Entity
<b>class</b> LineItem {
@ManyToOne Product product.
}
@Entity
<b>class</b> Customer {
@EmbeddedId CustomerId id;
}
尽管这构成了可工作的代码,但是模型的许多语义仍然是隐式的。在JPA中,最粗糙的概念是实体。它不知道聚合。它还将自动将立即加载用于一对一关系。而对于聚合关系,这却不是我们想要的。
这种情况下,以技术为中心的反应就是从立即加载切换到延迟加载。但是,这带来了一个新问题,我们开始挖坑,实际上已经从领域建模转向建模技术,这是我们首先要避免的事情。我们也可能要改变映射对象类型到对象的标识字段,如在Order用CustomerId更换Customer。虽然这解决了级联问题,但现在还不清楚该属性有效地建立了聚合关系。(banq注:这种方式在"某实现DDD"书籍中曾经误导很多人)
对于所引用的LineItem items,应该采取默认的立即加载机制,而不是延迟加载,因为DDD聚合通常控制着其内部的生命周期。
改善主意
为了改善上述情况,我们可以开始引入新类型,这些类型允许我们显式分配角色以建模工件,并通过使用泛型来约束它们的组成。让我们从这些内容开始(大多数内容最初是在John Sullivan的 Advancing Enterprise DDD中描述的-恢复聚合, 但在尝试将其转换为库的同时进行了稍微重命名)。
<b>interface</b> Identifier {}
<b>interface</b> Identifiable<ID <b>extends</b> Identifier> {
ID getId();
}
<b>interface</b> Entity<T <b>extends</b> AggregateRoot<T, ?>, ID <b>extends</b> Identifier>
<b>extends</b> Identifiable<ID> {}
<b>interface</b> AggregateRoot<T <b>extends</b> AggregateRoot<T, ID>, ID <b>extends</b> Identifier>
<b>extends</b> Entity<T, ID> {}
<b>interface</b> Association<T <b>extends</b> AggregateRoot<T, ID>, ID <b>extends</b> Identifier>
<b>extends</b> Identifiable<ID> {}
Identifier只是为标识符类型配备的标识接口。这鼓励使用专用类型来描述聚合的标识符。这样做的主要目的是避免每个实体都由一个通用类型(例如Long或UUID)来标识。从持久性的角度来看,这似乎是个好主意,但会容易将Customer标识符与Order 标识符混合在一起。明确的标识符类型避免了该问题。
DDD Entity是一个可识别的概念,这意味着它需要公开其标识符。它也绑定到一个AggregateRoot。乍一看似乎很不直观,但它可以验证不是从不同的集合中意外引用了Entity诸如此类LineItem。使用这些接口,我们可以设置静态代码分析工具来验证我们的模型结构。
Association接口基本上是指向相关集合的标识符的一种间接方式,该标识符仅在模型内发挥表达作用。
这些接口以及所有后续提到的代码都可以通过一个名为库jDDD, GitHub仓库 。
显式构造
应用这些概念后,我们的模型将是什么样子(为了清晰起见,未声明JPA注释,请参见 此处的 代码)?
<b>class</b> OrderId implements Identifier {} <font><i>// same for other ID types</i></font><font>
<b>class</b> Order implements AggregateRoot<Order, OrderId> {
OrderId id;
CustomerAssociation customer;
List<LineItem> items;
}
<b>class</b> LineItem implements Entity<Order, LineItemId> { … }
<b>class</b> CustomerAssociation implements Association<Customer, CustomerId> { … }
<b>class</b> Customer implements AggregateRoot<Customer, CustomerId> { … }
</font>
这样,我们可以仅通过查看类型和字段来提取许多其他信息:
- Order的标识符类型是OrderId,之前虽然也存在,但却被JPA注释了。
- LineItem是属于Order集合的实体。
- customer属性清楚地表明它代表与Customer聚合的关联association。
使用 jQAssistant 或 ArchUnit之 类的工具对仅保留在其自己的集合中的实体进行验证是一项非常直接的任务。还可以提取信息,用于文档等。
持久性技术
尽管所有这些都很好,但我们仍然面临最终必须将其映射到数据存储的挑战,在这种情况下,假设使用JPA。如之前所确定的,存在一些默认的映射规则,我们需要将其结果应用于模型的样板注释。此类步骤的一些示例:
- 所有实体都需要加上注释@javax.persistence.Entity。
- 标识符类型将需要成为@Embeddable,标识符本身ID(DDD定义:一个实体的属性类型可分配给Identifier)映射为@EmbeddedId。在例如Hibernate中,还需要实现嵌入式标识符Serializable(以实现第二级缓存中的潜在可用性)。
- Entity聚合中的属性可以使关系映射@OneToOne或@OneToMany默认为立即加载,因为聚合应用控制它们的生命周期是合理的。
- 实现Association也必须是可嵌入的。
我们实际上如何从外部将这些默认值赋值到类型中?我有一个 基于ByteBuddy 的 原型实现 。它提供了一个 JpaPlugin 实现ByteBuddy的Plugin接口,供其构建插件使用,如下所示:
使用ByteBuddy JPA插件基于DDD概念默认JPA批注:
<plugin>
<groupId>net.bytebuddy</groupId>
<artifactId>byte-buddy-maven-plugin</artifactId>
<version>${bytebuddy.version}</version>
<executions>
<execution>
<goals>
<goal>transform</goal>
</goals>
</execution>
</executions>
<configuration>
<transformations>
<transformation>
<plugin>….JDddJpaPlugin</plugin>
</transformation>
</transformations>
</configuration>
</plugin>
该插件的工作原理如下:
- 通过检查传递给Plugin实现的类型是否实现了任何感兴趣的接口来识别DDD概念。
- 对于每个概念,检查现有注释的类型和字段,如果不存在,则添加适合当前关系的默认值。
与Spring Data集成
在使持久性技术适应类型系统中可用信息方面,我们可以采取的最后一步是如何Associations轻松解决问题。我们前面提到的示例包含这些接口,这些接口在某些时候实际上可以将其转换为Spring Data:
<b>interface</b> AggregateLookup<T <b>extends</b> AggregateRoot<T, ID>, ID <b>extends</b> Identifier> {
Optional<T> findById(ID id);
}
<b>interface</b> AssociationResolver<T <b>extends</b> AggregateRoot<T, ID>, ID <b>extends</b> Identifier>
<b>extends</b> AggregateLookup<T, ID> {
<b>default</b> Optional<T> resolve(Association<T, ID> association) {
<b>return</b> findById(association.getId());
}
<b>default</b> T resolveRequired(Association<T, ID> association) {
<b>return</b> resolve(association).orElseThrow(
() -> <b>new</b> IllegalArgumentException(
String.format(<font>"Could not resolve association %s!"</font><font>, association)));
}
}
</font>
AggregateLookup.findById(…)本质上等同于CrudRepository.findById(…)这不是巧合。 AssociationResolver公开使用关联的公开标识符来解析Associationvia findById(…)方法的方法。这样可以使a CustomerRepository看起来像这样,并且可以直接使用,而无需进行任何其他更改。
<b>interface</b> Customers <b>extends</b>
o.s.d.r.Repository<Customer, CustomerId>,
AssociationResolver<Customer, CustomerId> { … }
Order order = … <font><i>// obtain order</i></font><font>
Customers customers = … </font><font><i>// obtain repository</i></font><font>
Optional<Customer> customer = customers.resolve(order.getCustomer());
</font>
Customers式一个标准的Spring Data仓储,我们可以轻松地通过其存储库显式地解决与其他聚合的关联。
公开问题和展望
1.让领域代码依赖接口?
我知道这是一个极具争议的话题。有一群人根本不去打扰,如果他们是例如Spring Data的一部分,他们会很乐意依赖这些接口。其他人理所当然地担心保持其领域模型尽可能独立于技术方面。但是,这有中间立场。如果您考虑一下:用编程语言实现领域模型也是技术上的耦合。
我认为,如果没有办法一定要依赖库包,那么就可以依靠某种技术使得删除这种依赖的工作量很小。这里提供的是一组接口,使我们能够使DDD概念明确(以前是隐式的)。首先,这与DDD的精神是一致的。
2.是否要求Identifier限制性?
泛型类型被绑定到ID extends Identifier,消除了使用简单类型(可能性Long,UUID)作为标识符的可能性。尽管这在某种程度上是有意的,但也可能被认为过于侵入。
3.持久性设置是否太令人困惑?
尽管特定于概念的默认设置很好,但也可能会造成一些混乱,特别是对于习惯于查看JPA批注的开发人员而言。“这怎么运作的?” 这个问题很容易提出。新的默认值是什么样的?
4.有进一步的其他持久性技术集成
对于其他持久性集成,也可能根据适用于DDD构造的规则提供映射默认值。这可能意味着其他ByteBuddy插件,也可能是对构建块接口的可选检查,以推断模型。
5.构建集成
尽管通过ByteBuddy集成默认设置的效果很好,但是如果一切顺利的话,什么也没发生,也没感到尴尬,这可能只是习惯了。错误会导致命令行构建失败,这很好。但是,与Eclipse的集成存在一些问题。
总结
本文介绍了在设计领域模型并将其直接映射到JPA等持久性技术时,表达DDD构建的常见问题。建议使用一组描述构造块及其关系的接口作为一个库来提供。使用ByteBuddy实现了基于这些构造的改进的JPA默认映射Plugin。建议进行其他Spring Data集成,以简化显式解析聚合之间的关联。
库和示例代码位于此 GitHub存储库中 。当前可从 Spring Artifactory存储库中 获取的二进制文件:
<repositories>
<repository>
<id>spring-libs-snapshot</id>
<url>https:<font><i>//repo.spring.io/libs-snapshot</url></i></font><font>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.jddd</groupId>
<artifactId>jdd-core</artifactId>
<version>0.0.1-SNAPSHOT</version> <!-- Replace with current version <b>if</b> needed -->
</dependency>
</dependencies>
</font>
正文到此结束
- 本文标签: 总结 root Enterprise IO 数据库 解析 core ip OneToOne 专注 管理 开发 java ACE 二级缓存 find CTO entity eclipse neToMany 模型 IDE dependencies spring 生命 plugin zab 注释 src maven ManyToOne id 数据 插件 删除 https ORM 缓存 代码 lib db JPA 工作原理 UI list http git Persistence 本质 GitHub
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

