Spring Data JPA 进阶初探:配置文件、注解和持久层简单接口
SpringData JPA是spring基于ORM框架、JPA规范的基础上封装的一套JPA应用框架,是基于Hibernate之上构建的JPA使用解决方案,可以使开发者使用极简的代码实现对数据库的访问和操作。它提供了包括增删改查等在内的基本功能,且易于扩展。
一、Spring Data Jpa、JPA 和 hibernate三者关系
通俗来讲Spring Data Jpa是对 JPA 规范的一层封装,hibernate实现了JPA规范。
我们使用java代码调用 Spring Data Jpa的api,Spring Data Jpa封装了 JPA 规范,并且内部使用的是hibernate实现,hibernate封装了jdbc进行数据库操作。
Java代码-->Spring Data Jpa --> JPA 规范-->hibernate-->jdbc -->mysql数据库
二、配置文件说明
hibernate.hbm2ddl.auto 参数的作用主要用于:自动创建、更新、验证数据库表结构,有四个值。
- create:每次加载 Hibernate 时都会删除上一次生成的表,然后根据 model 类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。
- create-drop:每次加载 Hibernate 时根据 model 类生成表,但是 sessionFactory 一关闭,表就自动删除。
- update:最常用的属性,第一次加载 Hibernate 时根据 model 类会自动建立起表的结构,以后加载 Hibernate 时根据 model 类自动更新表结构,不会删除表中的数据。
- validate :每次加载 Hibernate 时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。
其他配置项:
- dialect 主要是指定生成表名的存储引擎为 InnoDB
- show-sql 是否在日志中打印出自动生成的 SQL,方便调试的时候查看
三、实体类中的注解
- @Entity(name=”EntityName”) 必须,此注解标记 Pojo 是一个 JPA 实体。声明这个类对应了一个数据库表。
- @Table(name=””,catalog=””,schema=””) 可选,声明了数据库实体对应的表信息。包括表名称、索引信息等。
- @Id 必须,@Id 定义了映射到数据库表的主键的属性,一个实体只能有一个属性被映射为主键。
- @GeneratedValue(strategy=GenerationType,generator=””) 可选,strategy: 表示主键生成策略,有 AUTO、INDENTITY、SEQUENCE 和 TABLE 4 种,分别表示让 ORM 框架自动选择,generator: 表示主键生成器的名称。
- @Column(name = “user_code”, nullable = false, length=32) 可选,@Column 描述了数据库表中该字段的详细定义,这对于根据 JPA 注解生成数据库表结构的工具。
- @Transient可选,@Transient 表示该属性并非一个到数据库表的字段的映射,ORM 框架将忽略该属性。
- @Enumerated 可选,使用枚举的时候会用到。
四、持久层服务类
在 Spring Data JPA 的中,实现一个持久层的服务是一个非常简单的。
在创建好实体类后,我只需要声明一个接口,这个接口继承 org.springframework.data.repository.Repository<T, ID> 接口或者他的子接口就行。其中 T 是数据库实体类,ID 是数据库实体类的主键。然后再简单的在这个接口上增加一个 @Repository 注解就结束了。
4.1、Jpa 持久层常用的接口
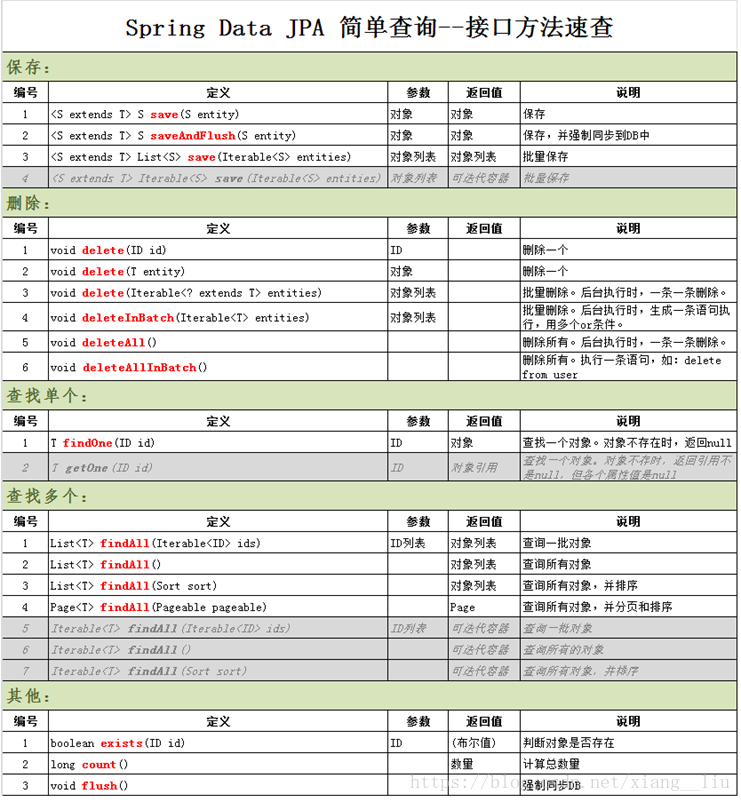
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

